Apuntes Curso Fundamentos de Base de Datos (FBD)
Este archivo cuenta con los apuntes del curso de bases de datos de la facultad de ingeniería más un resumen del libro del curso Fundamentals of database systems de Elmasri siguiendo la estructura temática del mismo.
Parte I (Introduction)
Introducción
Dato vs Información: El primero son datos procesados e interpretables, tienen un valor semántico. Mientras que un dato es una mera representación simbólica. Ej: 01010 (No representa nada).
Definiciones
database: Colección de datos relacionados. Open fing: Conjunto de datos inter-relacionados
sistema de información: Conjunto de componentes que interactúan con el objetivo de almacenar, recuperar y procesar datos e información para crear nueva información.
database management system (DBMS): Es un sistema computarizado que permite a usuarios administrar y mantener una base de datos. Es un software de propósito general que facilita el proceso de definir, construir, manipular y compartir una base de datos entre varios usuarios y aplicaciones.
Universe of discourse (UoD): (Dominio de discurso) The domain of discourse, also called the universe of discourse, universal set, or simply universe, is the set of entities over which certain variables of interest in some formal treatment may range.
definición de una DB: Descripción o definición de las estructuras de datos y restricciones que tendrá una base
construcción de una DB: Proceso de carga de los datos en la base
manipulación de una DB: Proceso de explotación de la base, esto es, la recuperación y modificación de los datos almacenados.
modelo de datos: Lenguaje para especificar una base de datos. Especifica: Estructuras,restricciones y operaciones.
schema: (Esquema) Descripción de los datos que tenemos y la relación entre ellos (incluye las relaciones de integridad).
instancia: Los datos per se que se encuentran en la database.
Caracterísiticas de una base de datos
- Representa un aspecto del universe of discourse (UoD)
- Es una colección coherente de datos con un significado inherente.
- Está diseñada,construida y poblada con datos con un propósito específico. Tiene un grupo de usuarios interesados con aplicaciones preconcebidas.
Una base de datos puede tener cualquier tamaño y complejidad.
Aspectos Generales
Definir una database implica definir sus data types, estructuras y constraints entre los datos que son almacenados. La definición de la DB la almacena el DBMS en una forma de catálogo o diccionario a esto se le llama meta-data.
Construir una database es el proceso de almacenar datos en un medio de almacenamiento administrado por un DBMS.
Manipular una base de datos implica usar funciones de tipo query para obtener datos específicos, actualizar cambios del UoD y generar reportes con la data.
Compartir una DB permite a multiples usuarios y programas acceder a la DB de forma simultanea.
Un programa interactuá con la DB a través de queries (requests) de datos al DBMS. Una query hace que se devuelvan datos. Se le llama transaction a las operaciones que generan lectura y escritura en una DB.
Diseño de una DB
Una DB forma parte del sistema de información (IT) de una organización. Diseñar una DB comienza con el proceso de especificación y análisis. Estos requerimientos se transforman en un diseño conceptual que puede ser representado y manipulado utilizando herramientas computacionales para ser fácilmente transformado en una implementación de una base de datos (Ejemplo: modelo MER). Este diseño luego es traducido a un diseño lógico que se expresa con un modelo de datos implementado en un DBMS. La etapa final es el diseño físico donde se añaden más especificaciones para el acceso y almacenamiento de la DB. El diseño de la DB ess implementado y habitado con datos reales, para reflejar el UoD.
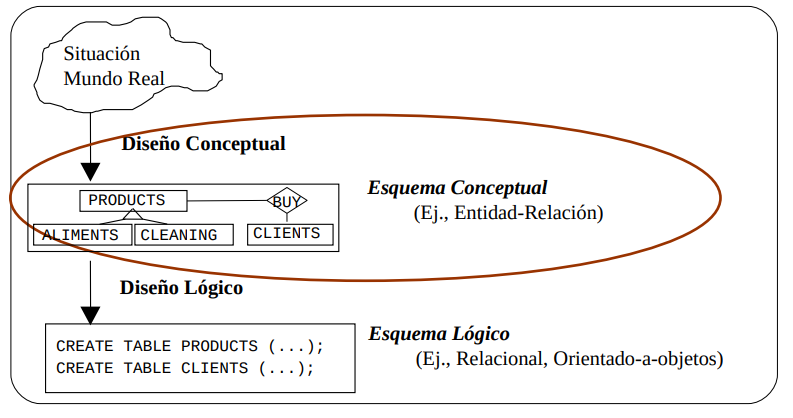
The Database Approach
El approach de usar una DB difiere significativamente del clásico paradigma de tener los datos guardados en simples archivos. Los programas implementaban los archivos y estos estaban estrechamente relacionados. Esto trae problemas... En el DB approach un solo repositorio mantiene los datos que es definido una vez para luego ser accedido constantemente por distintos usuarios a través de consultas (queries), transacciones y programas. Las principales características del database approach vs file processing approach son:
- La naturaleza Self-describing de un sistema de base de datos.
- Encapsulamiento entre programas y datos más la abstracción de los mismos.
- Soporte para distintas formas de ver los datos
- Soporte para sharing y procesar accesos de forma simultanea
Self-Describing Nature of a DB System
Una característica fundamental del acercamiento DB es que un sistema de base de datos no solo contiene la DB per se pero también una definición completa de la estructura de la DB con sus constraints. Esta definición es almacenado en el DBMS catalog que contiene también la info del formato de cada campo. La info del catalogo se le llama meta-data, describe la estructura de la DB primaria. Cabe notar la existencia de bases de datos que no requieren metadata: Los sistemas NOSQL.
El catalogo es utilizado por el DBMS y por los usuarios. El DBMS no esta escrito para una DB en particular, por lo que accede al catalogo para conocer la estructura de los archivos. Los usuarios necesitan saber la estructura de la DB para poder acceder a ella y realizar las consultas.
Encapsulamiento entre Programas y datos
Existe una independencia entre los programas y los datos con el db approach. En el procesamiento de archivos tradicional la estructura de los datos estaba dentro del programa, y un cambio en la estructura implica cambiar el programa. Un DBMS provee a los usuarios con una representación conceptual de los datos. Ahorrándole los detalles de como estos se implementan.
Distintas formas de ver los datos y concurrencia.
Los DBMS incluyen un control de concurrencia, permitiendo que los users accedan a los datos simultáneamente sin incoherencias (ver: reservar un asiento en dos terminales). A esto se le llama online transaction processing. Es fundamental que una DBMS se asegure de que las transacciones a una base de datos sucedan de forma correcta y eficiente. Una transacción es un proceso que incluye una o más accesos de R/W a una db. Una DBMS debe asegurar las siguientes dos propiedades
- Insolación: Una transacción debe ejecutarse como si fuera la única que existiese.
- Atomicidad: El DBMS debe asegurarse que todas las operaciones de una transacción se ejecutan, o no se ejecuta ninguna.
Actores en escena
En grandes organizaciones, muchos actores interactúan con una base de datos en el dia a dia y están interesados en los contenidos de la base de datos en su trabajo.
Administrador de DB: (Database Administrator DBA) Este es encargado de supervisar la DB y el DBMS y software relacionado. El DBA es responsable de autorizar el acceso a la DB, coordinar y monitorear su uso.
Diseñador de DB: Encargado de identificar los datos que deben ser almacenados y elegir las estructuras adecuadas para representarlos. Deben comunicarse con los usuarios para entender sus requerimientos para llegar a un diseño que los cumpla. Los diseñadores interactúan con cada grupo para generar una visión de la DB. Tras interactuar con varios se integran todas las visiones y requerimientos. Estas tareas se hacen previamente a la implementación de la DB.
Usuarios finales: Son los que en su trabajo tienen que acceder a la DB. Se dividen en varias categorías:
- Usuario casual: accede ocasionalmente a la db, pero precisa información distinta en cada acceso, utiliza una interfaz sofisticada para hacer queries especificas.
- Usuarios naive o parametric: Son los mayoritarios, hacen queries constantes usando tipos standard de queries y updates llamadas canned transactions, estas fueron programadas y testeadas adecuadamente. Estas se realizan a través de apps, por ejemplo: Acceder al balance de una cuenta del banco.
- Usuarios sofisticados: ingenieros, científicos y analistas que están familiarizados con los servicios del DBMS para implementar sus propias aplicaciones para sus usos personales.
- Usuarios standalone: Mantienen DB personales usando programas amigables con menus e interfaces. Ej: Un usuario de Memory.
Analistas de sistemas y Programadores (software engineers dice el libro xD): Son los que programan las canned transactions que los end users utilizan. Tienen que tener clara las cosas que el DBMS ofrece.
Actores detrás de escena
Son los que no están directamente relacionados con la DB en si pero con el DBMS y sus herramientas. Estos son los diseñadores del propio DBMS (el cual se implementa de a módulos por su complejidad). Estos incluyen pero no se limitan a: Implementación de catálogos, lenguaje para procesar consultas, procesamiento con interfaces, acceder y bufferer datos, controlar concurrencia, manejar seguridad y reliability de datos. Realizar una interface con los demas componentes del sistema, como el OS, compiladores y lenguajes de programación. Otras personas son los que desarrollan plugins y herramientas para incorporar al DBMS, estas son especificas y valiosas. No olvidar el sysadmin que mantiene el hardware que corre la base de datos.
Ventajas del DBMS approach
Utilizar un DBMS incluye ventajas adicionales a las ya mencionadas. El DBA debe utilizar las capacidades para cumplir los objetivos relacionados al diseño, administración y el uso de una gran cantidad de usuarios.
Controlar redundancia: Como la data esta en un solo lugar, ya no están los problemas de tener varias copias en muchas maquinas y tener que preocuparse por el syncing y bla bla bla. Ni hablar de que cuando hay muchos datos estoy malgastando espacio. A su vez se da lugar a inconsistencias. En el db approach cada item lógico esta en un solo lugar. Esto se le conoce como data normalization, y asegura la consistencia de la DB y ahorra espacio. Sin embargo, a veces es bueno tener redundancia para aumentar la performance de las consultas. Por ejemplo, es mejor acceder a un solo archivo donde hay un record redundante que tener dos archivos separados. A esto se le llama desnormalizacion un DBMS debe ser capaz de controlar su redundancia y evitar las inconsistencias entre archivos.
Acceso restringido: Un DBMS debe tener un sub-sistema de autorización de acceso a los datos, cuentas de usuario con políticas de seguridad para determinar quien puede modificar y leer información
Almacenamiento persistente de objetos Las database orientadas a objetos pueden almacenar los objetos con estructuras definidas por class de c++ o Java por ej. Para almacenar instancias de forma persistente. Estos sistemas ofrecen compatibilidad con los objetos de lenguaje de programación
Proveer de estructuras de almacenamiento y técnicas de consulta eficientes: Un DBMS debe proveer de estructuras especializadas para aumentar la búsqueda en el disco de algún registro. Se usan archivos auxiliares llamados indexes. Los registros deben ser copiados a memoria principal para ser accedidos, los DBMS implementan buffering & caching para acelerar los tiempos de acceso. Los DBMS tienen sus propias técnicas de buffering aparte de las del SO residente. Por otro lado, el DBMS debe pensar un plan de ejecución eficiente para las consultas que se le realizan según las estructuras de almacenamiento que este disponga.
Backup y recovery: Cuando algo falla, un DBMS debe ser capaz de mantener la DB en un estado coherente en el que estaba antes de que el sistema fallase. También deben mantenerse backups de disco en caso de fallos de disco.
Proveer de muchas interfaces: Debe dar interfaces para todos los usuarios: Apps, lenguajes de consulta, interfaces para lenguajes de programación y comandos. Interfaces GUI y web-GUI.
Representar relaciones complejas entre los datos: Nada, debe saber representar todo, definir nuevas relaciones cuando aparecen y actualizar los datos de forma fácil y eficiente.
Forzar restricciones de integridad: Hay ciertas restricciones que mantienen la base de datos en un estado coherente. Un DBMS debe proveer de las funciones para definir y hacer valer estas restricciones. (Ej: la edad es un int y mayor a 18). Las restricciones sobre un registro que hacen referencia a otros registros se le llaman referential integrity constraint. Una clásica es la unicidad de items en un registro (key or uniqueness constraint). Estas restricciones se derivan de la semántica de los datos y del UoD que representan. Algunas restricciones tendrán que ser verificadas por los programas que actualizan la DB o ingresan datos. A estas constraints se las llama business rules. Las constraints inherentes a un modelo especifico de datos se les llama inherent rules of the data model.
Permitir Inferencias y acciones usando reglas y triggers: Algunos DB systems tiene que proveer la capacidad para definir reglas deductivas para inferir nueva información de la que se encuentra en la DB. A estos se los llama deductive database systems. Un ejemplo es un conjunto de reglas para definir si un alumno está suspendido. Estas se expresan de forma declarativa como reglas, las cuales son mantenidas por el DBMS para determinar quienes son todos los alumnos suspendidos. Sistemas modernos le asocian triggers a las tablas, un trigger es una forma de regla que se activa cuando se actualiza la tabla, realizando operaciones sobre otra tabla, enviando msgs, etc. Estos son llevados a cabo por los llamados active database systems. Triggers complejos se los suele llamar stored procedures.
Implicaciones adicionales: Forzar un standard, reducir tiempos de desarrollo, flexibilidad, disponibilidad de información actualizada, economía de escala, etc.
Cuando no usar un DBMS
Existen situaciones donde no vale la pena usar una base de datos. Los costos de inversion en hardware y software, tener personal especializado, la generalidad de un DBMS, y todo lo que implica generan overhead que hacen que no valga la pena tener una DB en sistemas simples cuya estructura de datos no cambia en el tiempo. Sistemas real-time donde la performance es todo, sistemas embebidos con poca memoria o donde no interesa que muchas personas accedan a los datos a la misma vez.
Conceptos y arquitectura de un sistema de bases de datos
La arquitectura de un DBMS ha evolucionado de un sistema monolítico a un sistema modular con una arquitectura servidor/cliente, acompaño las tendencias en la industria.
Data models, schemas & instances
Ona característica fundamental del database approach es que provee data abstraction, estos es la supresión de detalles de como están organizados los datos. Diferentes usuarios pueden percibir los datos a su nivel preferido de detalle. Un data model - una colección de conceptos para describir la estructura de la DB - permite lograr esta abstracción. La estructura de una base de datos son los data types, relaciones y constraints que se aplican sobre los datos. Muchas DB incluyen un set de basic operations para especificar el uso de la DB. Es común incluir conceptos que modelan la parte dinámica del comportamiento del sistema, por ejemplo la de determinar si un estudiante está suspendido.
Existen 3 categorías de modelos de datos: Alto Nivel (Conceptual), Lógicos (de implementación) y Bajo Nivel (Físico). El modelo conceptual usa conceptos como entidades, atributos y relaciones. Una entidad representa un objeto real o concepto, un atributo representa una propiedad de interés que describe una entidad y una relación entre 2 o más entidades representa una asociación entre las mismas. Un ejemplo de data model conceptual es el MER (Modelo entidad-relación). Los modelos de datos de implementación son los mas usados en los DBMS, estos incluyen el modelo relacional. (Otros en desuso son los network y hierarchical models). Estos modelos representan los datos usando estructuras tipo registro, por lo que se les llama record-based data models, una alternativa a estos son los object data models. Los modelos de datos físicos hablan de como los datos se representa la información y los access path - estructura de búsqueda que hace que buscar records sea eficiente (hash,index), ej: index, arboles, tablas de hash.
La descripción de una DB se le llama DB schema, se especifica durante la etapa de diseño y no se espera que cambie mucho. Una visualización de un schema se le llama schema diagram:
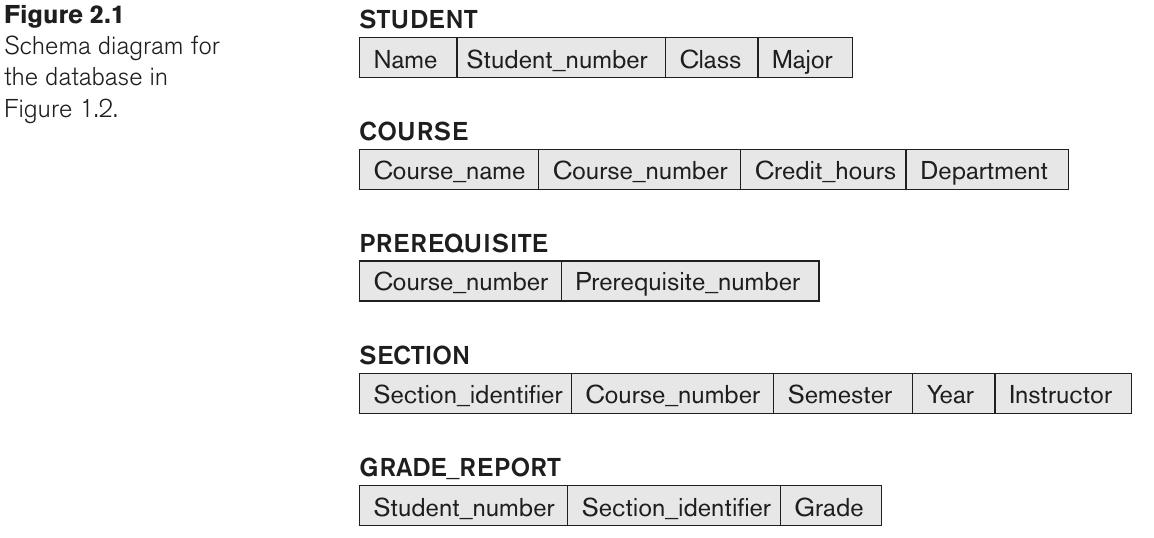
Cada objeto del schema se le llama schema construct. Notar que un diagrama muestra algunos aspectos del schema. Por ej, las constraints y los tipos de datos se omiten. El contenido de una DB cambia frecuentemente, los datos que se encuentran en un momento dado se llaman database state/snapshot o set actual de ocurrencias, instancia de una DB. Cuando definimos una nueva DB, le damos un schema al DBMS, al principio tendremos una instancia vacía de una DB, sin datos. Cada vez que se actualizan los datos, la db cambia a un nuevo estado. El estado actual se le llama current state. El DBMS es responsable que cada cambio de instancia sea hacia un valid state. Ie. que satisfaga el schema. Recordar que el DBMS guarda el schema en el catalogo. Adicionalmente, un DBMS provee operaciones para cambiar el schema para una DB ya poblada. A esto se le llama schema evolution.
Three-schema Architecture and Data Independence
La arquitectura de 3 esquemas permite separar los usuarios de la DB física. Se definen 3 niveles:
internal level: Tiene un schema interno que describe la estructura física de la DB. Usa un modelo físico de datos y se encarga de las minuciosidades del almacenamiento.
conceptual level: Tiene un schema conceptual que describe la estructura de toda la DB para una comunidad de usuarios. Se reservan los detalles de implementación. Se suele usar un modelo de datos representacional para describir el conceptual schema. El schema conceptual suele basarse en un high-level data model.
external or view level: Tiene muchos schemas externos o visiones de usuario. Describe una parte de la DB. Suele implementarse con un representational data model, basado en un external schema design de un high level conceptual data model.
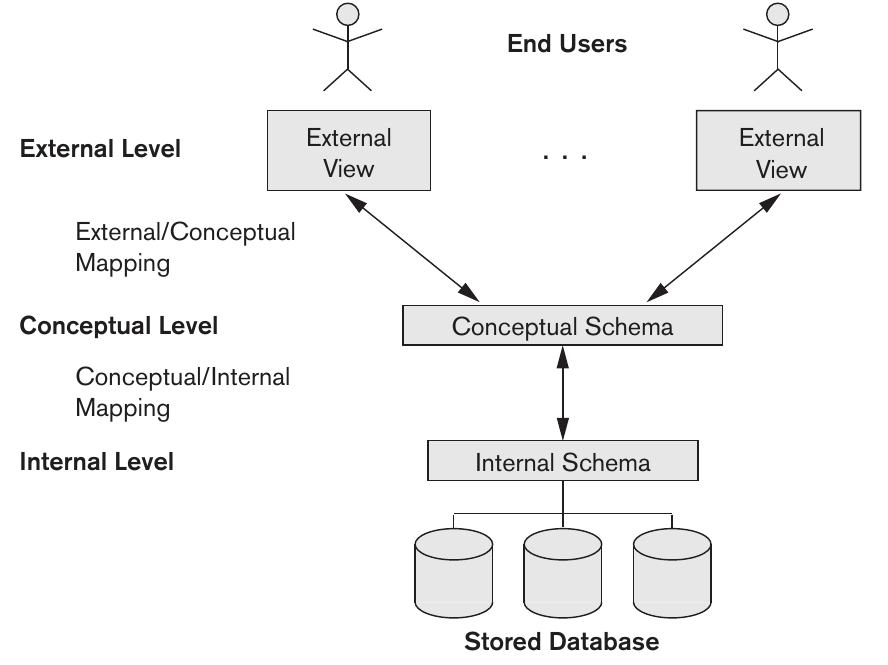
Los 3 esquemas no siempre están completamente separados, depende de la implementación. Notar que los esquemas son descripciones de los datos. Notar que los datos que se extraen de una DB deben ser formateados para coincidir con la vision externa que tenia un usuario en particular, a esto se le llama mapping. Estos pueden consumir muchos recursos, por lo que algunos DBMS no soportan lo de tener muchas external views.
La independencia de datos se define como la capacidad de cambiar un schema de un nivel sin la necesidad de cambiar un schema de los niveles mas altos. Se definen dos tipos:
Independencia lógica de datos: Es la capacidad de cambiar un schema conceptual si cambiar los schemas externos. Se pueden agregar registros o constraints y no necesariamente tener que cambiar el schema externo y los programas que lo utilizan. A lo sumo tendrá que cambiarse los mapping para transformar la vision del usuario.
Independencia física de datos: Es la capacidad de cambiar un schema interno sin tener que cambiar el schema conceptual. Poder cambiar la organización de archivos, indexes, paths etc.
Database languages and interfaces
Los schemas se definen utilizando un lenguaje. Existen varios tipos para distintas etapas, aunque actualmente se usa un solo lenguaje para todas las etapas.
Data definition language (DDL): Se utilizan para definir db que no usan muchos niveles. El DBMS tiene un compilador que construye la descripción del esquema en el catalogo.
Storage definition language (SDL): Se utiliza para representar el internal schema. Usualmente se reemplaza por una combinación de parámetros y funciones administradas por el DBA.
View definition language (VDL): Especifica las user views y los mappings al conceptual schema.
Data manipulation language (DML): Se utiliza para que los usuarios puedan manipular la base de datos. Existen dos tipos: High-Level/Non-procedural y Low-Level/procedural. El primero puede usarse para especificar pedidos completos y específicos al DBMS. Pot otro lado un procedural necesita la ayuda de un lenguaje turing-completo para loopear de forma iterativa sobre los pedidos. Por ello, los low-level se les llama record-at-a-time ya que procesan de a uno. Los high-level son set-at-a-time o set-oriented ya que devuelven sets enteros de datos. SQL es high level. A query in a high-level DML often specifies which data to retrieve rather than how to retrieve it (declarative).
En las bases de datos modernas todos estos lenguajes se agrupan en uno solo que integra todas las funcionalidades: SQL. El SDL se reemplaza por ajustes, funciones y parámetros del DBMS que el DBA es encargado. Cuando un DML esta embebido en (por ej) C++ se le llama a c++ el host language y a SQL data sublanguage. Cuando SQL se usa de forma standalone se le suele llamar query language. Los lenguajes 4GL son procedurlaes y orientados al acceso de BDs.
DBMS Interfaces
Muchas interfaces user-friendly son provistas para los distintos usuarios. Por ejemplo menu-based interface for web-clients. Apps for mobile devices. Forms-based interfaces (herramientas tipo encuestas para rellenar datos). GUI para mostrar schemas y interfaces en lenguaje natural (el DBMS trata de interpretarlas). Basadas en keywords, speech I/O (Hey Siri), interfaces para usuarios parametricos y para DBA(comandos).
The Database System environment
Modules
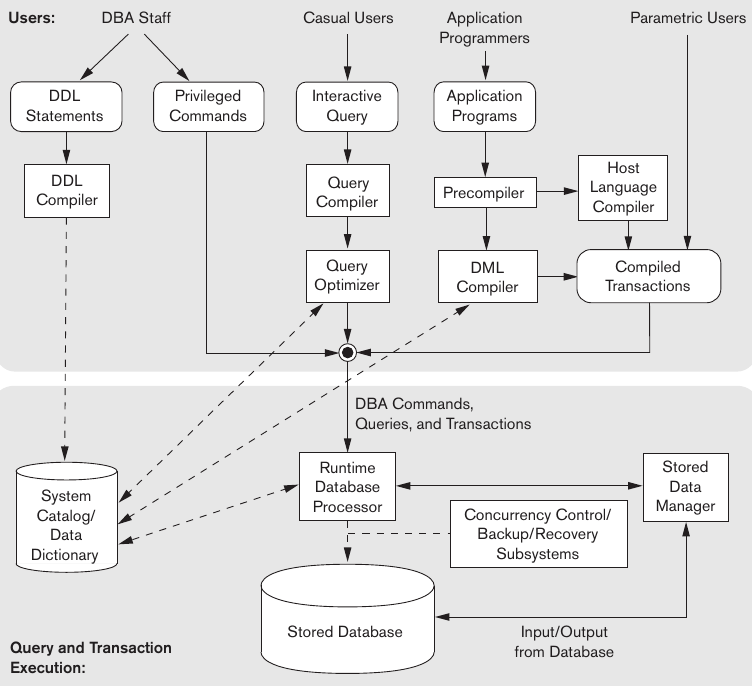
La imagen ilustra los componentes típicos de un DBMS. Se divide en userland y los módulos internos. El DDL compiler procesa definiciones de schemas y guarda tales descripciones en el catalogo del DBMS. El query compiler evaluá la sintaxis, nombre de las entidades, etc. de las consultas de los usuarios para compilarlas a código interno. Este es luego optimizado por el query optimizer. Adicionalmente en las canned operations los pre-compiladores de los lenguajes mandan el código al DML compiler para transformarlo en object code para su linkeditación. El runtime database processor ejecuta los comandos del DBA, query plans y las canned transactions con runtime parameters. Trabaja con el catalogo para cargarle estadísticas y con el stored data manager para optimizar el disk I/O. Dependiendo del sistema el DBMS va a tener más o menos libertad para administrar el hardware.
Los DBMS adicionalmente proveen utilidades como herramientas para cargar datos ya existentes a una DB (Con su respectiva conversión), herramientas de backup, reorganización de almacenamiento y monitoreo de performance, etc.
Computer-aided software engineering tools are used in the design of database systems. Los data dictionaries brindan información adicional que un catalogo. Grandes organizaciones usan data dictionaries (data repository) con información de schemata, restricciones, estándares de uso, descripción de programas e información de usuario. A estos se les llama information repositories y son accedidos usualmente por los usuarios más que el DBMS. Por ultimo, los DBMS tiene software de comunicación para comunicarse en redes e integran el sistema DB/DC system. (database/data communication) para el sistema cliente/servidor.
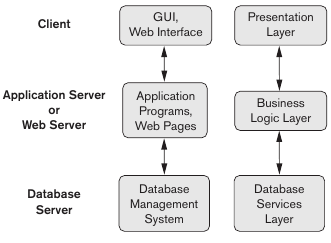
Arquitectura centralizada y cliente/servidor
Originalmente toda la estructura del DBMS se encontraba centralizada en un mainframe. Desde la consola se hacían las queries y las conexiones de red eran muy primitivas. Con el tiempo los sistemas DBMS empezaron a explotar la capacidad de cómputo del user-side, llevando a la arquitectura DBMS cliente/servidor. El cliente tiene las interfaces e interfaces para acceder al DBMS. Existen 2 principales tiers de arquitectura cliente servidor:
Tier-2: Las queries y procesamiento del SQL se hacen desde el servidor, a este se le llama query/transaction server. En los RDBMS se le llama servidor SQL. Cuando un cliente quiere acceder al DBMS se utiliza una API. El asenso de la internet genero un cambio en los roles del cliente y servidor, llevando al tier3.
Tier-3: Aparece un servidor en el medio que es el que provee una interfaz y modela la interacción de los clientes de acuerdo a las reglas de negocio del sistema. A este se le llama web server o application server. Esto aumenta la seguridad ya que el cliente no interactuá de forma directa con la base de datos.
Clasificación de DBMS
Un DBMS puede clasificarse por muchos criterios. El central es el modelo de datos. Algunos criterios adicionales son:
- Numero de usuarios. Single-user systems vs multi-user systems (la mayoría).
- Distribución. La base de datos puede estar centralizada en una computadora o en varias, lo que se conoce como distributed DBMS (DDBMS). Los sistemas Big Data son distribuidos y los datos son replicados para su reliability. Los DDBMS se dividen en
- Homogéneos: Usan el mismo DBMS en todos sus nodos.
- Heterogéneos: Usando distintos DBMS y middleware para acceder a las distintas bases de datos. Los nodos pueden tener autonomía, llevando a un DBMS federado (o multi database system).
- Costo: Podes usar PostgreSQL free o pagar millones por un sistema gigante.
- Tipos de access path: Como almacenan los archivos (has, tabla de archivos invertida, etc)
- Propósito: Pueden ser de propósito general o especializados. Cuando la performance es esencial se construyen DBMS especializados para procesar datos definidos a velocidades elevadas. A los sistemas que deben responder rápido y tienen concurrencia se les llama OLTP (Online transaction processing), tienen que soportar altas concurrencias sin delays excesivos.
Modelo de datos
Este es el criterio central para clasificar un DBMS. Existen varios tipos siendo el relacional el de mayor proliferación (El de objetos esta ganando en el big data...)
- Relacional: Representa la base de datos como una colección de tablas, donde cada tabla puede almacenarse en archivos separados. Utilizan el lenguaje SQL y soportan visiones de usuario limitadas.
- Object: Define la database en términos de objetos, sus propiedades y operaciones. Aparecen las clases (estas se organizan en DAGs) y sus operaciones se especifican en métodos.
- KeyValue: Asocia una clave única con cada valor y provee accesos rápidos.
- Document: Se basa en JSON y guarda los datos como documentos (ensamblando objetos complejos)
- Basados en columnas: Guarda las columnas de las filas en paginas de disco para acceso rápido y tener muchas versiones de los datos.
- XML: Forma de intercambio de datos en la WEB, los DBMS dan operaciones para su manejo
- Legacy: Están los hierarchical, network set type que se usaban en el pasado pero ya no tienen relevancia.
Parte II (Conceptual Data Modelling and Database design)
Data Modelling using the Entity-Relationship (ER) Model
Apuntes OF2
Nos centrarémos en los conceptual schema. A través del modelado conceptual. I.e actividad en la cual se construyen esquemas conceptuales de la realidad. Primer etapa de diseño de una DB.
modelos conceptuales
- Modelos de datos de muy alto nivel
- Se concentran en describir el dominio del problema, mostrando estructuras y relaciones de integridad
- Suelen tener un representación gráfica asociada
- Ejemplos
- MER
- ER-Extended
- SDM
El esquema conceptual luego pasara por el esquema lógico, estos tendrían que ser equivalentes y es importante aclarar donde no lo son.
Conceptos básicos
Elementos identificables:
- Conjuntos: Elementos de interés aparecen agrupados o clasificados en conjuntos de acuerdo a sus características. '
- Relaciones entre conjuntos. (Conjuntos de parejas,ternas,cuaternas,etc.)
- Restricciones de integridad.
- Atributo: Característica que nos interesa de un determinado elemento de la realidad (Nombre de un niño). Suele tener un type.
- Cardinalidad -N:1 Dado A,B se dice que tiene cardinalidad N:1 si dado un elemento cualquiera de A, puede haber en la relación solo una pareja con ese elemento. Ej = {(a1,b2),(a2,b1),(a3,b1)}. (Es una restricción de integridad!) -N:N Dado un elemento de A, puede haber cualquier cantidad de elementos de B.
- Totalidad: Dada una relación entre A y B, se dice que es total con respecto a A si todos los elementos de A debe aparecer en alguna pareja de la relación.
Principios del modelado conceptual
- Principio del 100%: El esquema conceptual asociado a un problema debe representar todos sus aspectos.
- Principio de Conceptualización: El schema conceptual no debe incluir ningún elemento asociado a la implementación del esquema o ningún elemento orientado a la performance de la DB.
Modelo Entidad-Relación
Modelo conceptual muy usado propuesto por Chen (lmao) en 1976. Existen variantes, los modelos Orientados a Objetos se inspiran y toman ideas de este modelo.
Conceptos básicos:
- Entidad: elemento de la reality
- Relación: asociación entre elementos.
El MER tiene un DDL gráfico orientado a mostrar las estructuras de datos y restricciones de integridad. Pero no tiene un DML standard. El MER tiene dos elementos básicos:
- Diagrama de entidad relación
- Restricciones no estructurales: Formulas lógicas que no pueden ser expresadas en el diagrama por su complejidad o por falta de notación. Deben escribirse en lenguaje lógico, semiformal y en el peor de los casos en lenguaje natural.
A diferencia del UML, los objetos no tienen identificación en si misma, solo podemos conocer a las entidades a través de sus atributos. Podría estar en el problema de tener dos entidades con los mismos atributos, y ahi estamos en un problema de identificación... Otra diferencia es que UML se utiliza tanto para modelado conceptual como lógico, a diferencia del MER que es solo conceptual.
Constructores
- Conjunto de Entidades: Modela los objetos de la realidad
- Relación: Modela asociaciones entre objetos
- Atributo: Modela propiedades de tipo de entidades o de relaciones
- Agregación: representa un tipo de relación como un tipo de entidad.
- Especialización: Modela sub tipos de entidades.
- Débil: Permite expresar dependencia.
No confundir el schema (esquema) ER de la DB con el diagrama ER de la base. El diagrama es una representación gráfica de la estructura de los datos de la base. El esquema es la estructura de datos representada por el diagrama. El lenguaje tiene una semántica bien definida.
Como aplico el MER para representar la realidad? Seguir los siguientes pasos:
- Identificar elementos de nuestro problema
- Identificar relaciones entre los elementos
- Representar las propiedades que nos interesan de los elementos.
Diagrama de entidad-relación
Los conjuntos de entidades se presentan con un rectángulo con el nombre, del que "cuelgan" los atributos. Las relaciones son un rombo con el nombre y conecta al set de entidades que relaciona. Hay notaciones particulares para las distintas restricciones.
Atributos
Un atributo es una función tal que dado un elemento de un determinado conjunto de entidades devuelve un valor de un determinado conjunto de valores. Ej: Para el conjunto de entidades persona. Tengo una función llamada \(Nombre : Personas \rightarrow Nombres\) que devuelve el nombre de una persona.
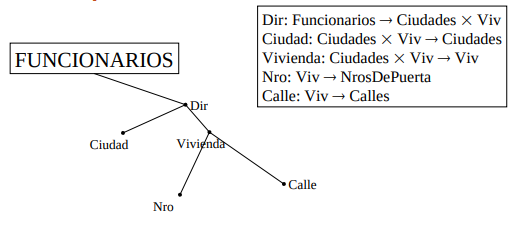
Atributos estructurados
Permiten representar atributos compuestos que están formados por varias partes independientes. La función dirección va a un producto cartesiano. Ej: (Dir Ciudad (Vivienda Nro Calle)). Dir: \(Persona: Personas \rightarrow Ciudad \times Vivienda, Ciudad: Ciudades \times Viv \rightarrow Ciudades\)
Atributos multi-valorados
Son funciones que devuelven un valor de tipo conjunto de otro dominio. Devuelven un elemento del conjunto Potencia de otro dominio. Ej: Función que para un libro me devuelve un conjunto de autores. Autores: \(Libros \rightarrow 2^{autores}\). Estos se ilustran en el schema con un asterisco.
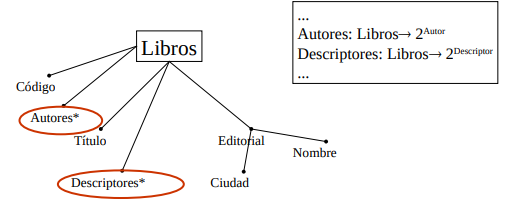
Restricciones sobre conjuntos de entidades
Se dice que un atributo es determinante cuando no pueden existir dos entidades en el conjunto que entregan el mismo valor en ese atributo. Un conjunto de entidades puede tener varios atributos determinantes. Los determinantes permiten identificar las entidades. Una característica que se verá más adelante es que toda entidad de la base de datos debe ser identificable. En el schema se representan subrayando el atributo
Relaciones
Una relación es un conjunto entidades. En el schema se representan con un rombo que uno los conjuntos de entidades participantes. Existen restricciones sobre las relaciones: Cardinalidad y totalidad. La cardinalidad responde a la pregunta: Cuantos b's pude estar relacionado un a? La totalidad fuerza a que todo a esté relacionado con un b.
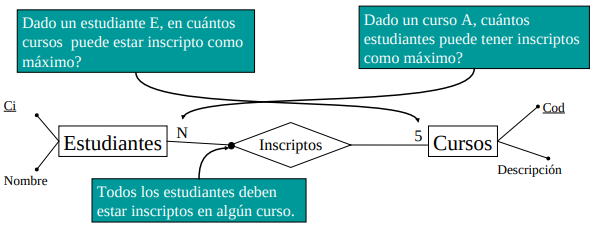
Pueden existir relaciones que requieren restricciones que no tienen una notación en el MER (restricciones no estructurales). Para estas usamos lógica de primer orden (recordar que una relación es un set!).
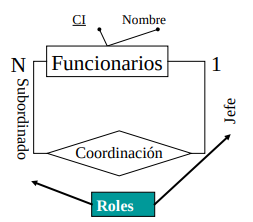
Las relaciones pueden tener atributos. Las relaciones son conjuntos, alas tenemos una función que va de un conjunto a un dominio. Una auto-relación es una relación donde A y B son la misma entidad. Para caracterizar la relación en esta caso se agregan etiquetas llamados "roles".
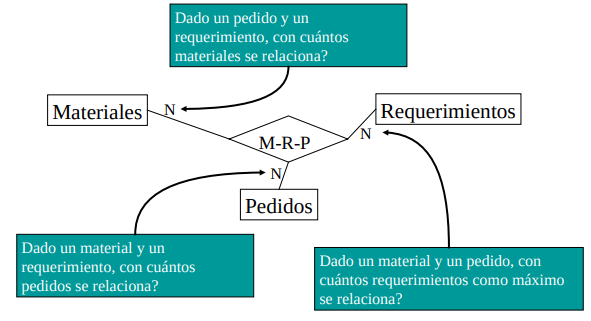
Las relaciones multiples asocian más de 2 entidades. Recordar que todas las partes deben estar presentes (ej: las ternas). Para pensar la cardinalidad fijamos n-1 entidades y nos preguntamos con cuantos conjuntos de n-1 entidades se puede relacionar esa entidad.
Agregaciones
Trata de representar asociaciones entre elementos de relaciones y de otros conjuntos de entidades. Es un operator de casting, interpreta una relación como si fuera un conjunto de entidades. Se representan rodeando la relación y sus entidades participantes en un cuadrado (o cosa deforme). Desde el punto de vista fuera del cuadrado todo es una entidad, por lo que podemos relacionarla con otras entidades fuera del area interior. Las agregaciones permiten representar más situaciones, pero son menos claras que les relaciones múltiples.
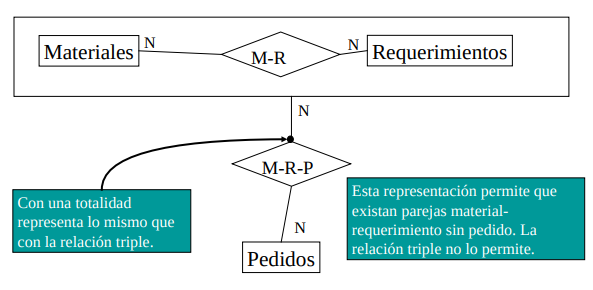
Especialización
Se representa en el scheme con un triangulo que une las demás sub-entidades. Se usa cuando tenemos una entidad que puede tener atributos y relaciones diferentes. Las sub-entidades son subconjuntos. En un principio se puede ser muchas cosas a la vez, o no ser ninguna.
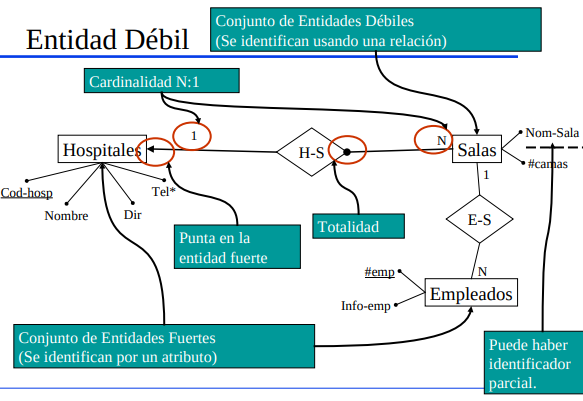
Entidad Débil
Una entidad es débil cuando su identificación es débil. Para poder identificarla necesito ir a su identidad fuerte. (Ej: Las salas de un hospital, necesito al hospital para identificarlas). Se ilustran con una flecha que empieza con un punto que va de la entidad débil a la entidad fuerte (En el medio de la flecha esta el rombo del nombre de la relación). Podrían no tener atributos determinantes, pero por lo general tienen atributos determinantes, los cuales son débiles y se subrayan con un punteado. No olvidar agregar la cardinalidad!
Control de calidad
Para asegurar la calidad de los esquemas conceptuales se define un conjunto de propiedades que se deben chequear durante y al final de su desarrollo:
- Completitud (Maximizar)
- Correctitud (Maximizar)
- Minimalidad (Maximizar)
- Expresividad (Balancear)
- Explicitud (Balancear)
Completitud
Un esquema es completo cuando se representan todas las características relevantes de la realidad planteada.
"En criollo: No me comí nada"
Chequeo: Se debe controlar que todos los conceptos del problema estén representados en alguna parte del esquema. A su vez tenemos que control que todos los requerimientos sean realizables por el sistema (podemos obtener todo lo que nos piden desde la base). Otra técnica es hacer paráfrasis del esquema. I.e a partir del esquema escribir un texto que lo represente. Luego se compara el texto generado con el de la letra.
Correctitud
Existen dos tipos:
Sintáctica: Habla de la forma en que se especifica el esquema con respecto al lenguaje usado para hacer esa especificación. Un esquema es correcto sintácticamente cuando las distintas partes de este están construidas correctamente con respecto al lenguaje utilizado. Por ej: respetar la sintaxis de las agregaciones. Algunos ejemplos de chequeo son:
- Existencia de cardinalidades en cada relación
- Existencia de atributos determinantes en cada entidad, si no existen then verificar que sea entidad débil con respecto a otra.
- Existencia de una y solo una relación y todas las entidades que intervienen en la misma dentro de cada agregación.
Semántica: Habla de la forma en que la especificación representa el problema. . Un esquema es correcto semánticamente si cada elemento del problema se representa utilizando las estructuras adecuadas. Este concepto es una entidad o relación? Una sola categoría de entidades o mas de una? Las relaciones que participan son binarias o multiples? cual es el mecanismo de determinación del conjunto de entidades? Están bien las cardinalidades y totalidades?
Minimalidad
Un esquema es minimal si cualquier elemento de la realidad aparece solo una vez en el esquema. Tener cuidado con los atributos que implican otros. Por ejemplo, una sala tiene x paciente. Y el hospital, compuesto por salas lleva el total de pacientes. Estamos llevando la cuenta de pacientes en dos lugares! Tenemos que tratarlo con cuidado, ya sea indicando que es un atributo calculado y como se calcula o no incluirlo y escribirlo como comentario fuera del diagrama.
Se debe chequear donde está representado en el esquema cada elemento de la realidad y a que elemento de la realidad corresponde cada elemento del esquema.
Expresividad
Un esquema es expresivo si representa la realidad en una forma natural que puede ser fácilmente comprensible basándose unicamente en la semántica del modelo.
Explicitud
Un esquema es explícito si no utiliza mas formalismos que el diagrama ER. Recordamos que el orden para la explicitud es: MER->Logica de primer orden -> Comentarios
Tenemos que tratar de buscar un balance entre todas las propiedades para conseguir un buen diagrama.
Modelo Relacional
Modelo de datos totalmente distinto al MER. Es un modelo de datos lógico (con ciertas características conceptuales), se usa como modelo implementado por el DBMS.
Vision informal del modelo
Las estructuras consisten en TABLAS. Cuyas columnas corresponden a ATRIBUTOS de tipo atómico y las filas corresponden a registros de datos. Las operaciones están fundamentalmente orientadas al modelo de TABLAS, como conjunto de registro. Es un modelo de datos simple y claro pero con mucho potencial para modelar casi todas las aplicaciones de database.
Conceptos generales
Dominio \(D.\) : Es un conjunto de valores atómicos.
Esquema de relación \(R(A_1,A_2,...)\): Donde \(R\) es el nombre de la relación y \(A_n\) son los atributos con dominios \(D_n\).
Relación \(r(R)\): Es una instancia de un esquema de relación R. Consiste en un conjunto de t-uplas: \(r= {
Tupla: Recordar que la instancia de un esquema de relación es un conjunto de tuplas: Ejemplo \(Esquema: ESTU(CI,nombre,dir\). Y una instancia es \((<5421345-3,"Nog","Canelones 123"> \ <\dots>)\) . La tupla es un elemento de un producto cartesiano de N dominios. Esta puede verse de dos formas distintas:
- Puede verse como un array: Utilizamos la posición en el arreglo para tomar cada parte. Ej: \(
- Puede verse como una función del nombre de los atributos en el contenido: \(t: { CI,nombre,dir } \rightarrow Nro \cup Strings\) . Ejemplo: \(
- Puede verse como un array: Utilizamos la posición en el arreglo para tomar cada parte. Ej: \(
Esquema de DB relacional o esquema relacional: Conjunto de esquemas de relación.
Características de las relaciones
Las relaciones son un conjunto de tuplas: No están ordenados y no hay repetidos. Los valores de los atributos en tuplas son atómicos (indivisibles). Las tuplas están ordenadas en la visión de producto cartesiano, pero en la visión tuplas como funciones no lo están.
Restricciones de integridad en el modelo relacional
restricciones de Dominios
Restricciones de tipo en los \(D_i\) . Indica a que tipo pertenecen los valores, pueden incluir subrangos o enumerados. Ejemplo: FUN(CI,Nombre,Dir,Edad)
- CI: number(9); Nombre: Dir: String; Edad: number(2); Edad > 18;
Superclave
Dado \(R(A_1,\dots,A_n)\) se dice que \( X \subseteq { A_1,\dots,A_n}\) es superclave en un esquema \(R\), si no puede existir ninguna \(r(R)\) tq tenga dos tuplas con valores iguales de X (\(t[X]=t'[X]\))
Clave
Una clave es una superclave que no contiene propiamente una superclave (o sea minimal). Las claves se marcan con un subrayado.
Claves Foráneas
Dado \(R\), un conjunto de atributos \(X\) es una FK (foreign key) de \(R\) con respecto a \(S\): si los atributos de \(X\) coinciden en dominio con los de una clave \(Y\) de \(S\) . Los valores de \(X\) en tuplas de \(r(R)\) (para toda r) corresponden a valores de \(Y\) en la relación \(s(S)\).
Ej: Si tengo un atributo ID_ESTU en examen entonces tiene que haber un estudiante que tenga el ID_ESTU. (Es una clave de los estudiantes que se encuentra en otra tabla).
Para notar una clave foranea lo escribimos como por ejemplo: Inscriptos.CI FK Estudiantes.CI
Observaciones
Una BD se considera valida si todas las relaciones r satisfacen las RIs, todas las instancias actuales de todas las relaciones declaradas en el esquema relacional satisfacen todas las RIs (Restricciones de Integridad).
Las RI surgen de la observación en la realidad, no de la observación de relaciones. Las RI se definen a nivel de Esquema de relación, no a nivel de instancia Las RI son verificadas o violadas por relaciones (instancias) no por esquemas de relación.
Operaciones de modificación
Insert
Sea \(R(A,B,C)\) y \(r(R)\) , insert \(
Delete
Sea \(R(A,B,C)\) y \(r(R)\): Delete from R where \(
Update
update R set \(
Calculo Relacional
Es un lenguaje de consulta para el Modelo Relacional. Tienen como objetivo recuperar datos de la instancia actual de la database. Esta basado en formulas de lógica de primer orden para definir conjuntos por comprensión. Una consulta en CR es una especificación de un conjunto por comprensión de un conjunto de tuplas. Existen dos sublenguajes del mismo:
- Calculo de tuplas: Variables de tipo tupla, es decir el universo esta formado por tuplas. Sus expresiones son de la forma: \( {
- Calculo de dominios: Variables por valor de atributo, es decir, el universo está formado por valores individuales.
Se deben considerar tres aspectos al definir un lenguaje de consulta:
- Sintaxis: Una descripción de cuales son las frases correctamente escritas en dicho lenguaje
- Semántica: Una forma de establecer la correspondencia de cada frase bien escrita según la sintaxis con un significado dado
- Pragmática: Como el contexto influye en el uso del lenguaje. Este contexto esta dado por el esquema (Estructura y restricciones) y el significado de dicho esquema para quienes interpretan los datos.
El calculo relacional es una familia de lenguajes de consulta sobre el modelo relacional basado en formulas de lógica de primer orden para construcción por comprensión de conjuntos de tuplas. Existen dos sublenguajes:
- Calculo de tuplas: Variables de tipo tupla, esto es, el universo formado por tuplas
- Calculo de dominios: Variables por valor de atributo, es decir el universo esta formado por valores individuales En el curso solo se trabaja con calculo de tuplas.
Calculo de tuplas
Sintaxis
Las expresiones son de la forma:
\( {
Definiciones formales:


Semántica
El universo está formado por todas las tuplas que se pueden construir con todos los dominios. El resultado de una consulta está dado por todas las tuplas del universo que cumplen con la condición expresada en la fórmula de la consulta.


Notar que el universo siempre es el conjunto de todas las tuplas que es posible formar con todos los dominios de los atributos. Por lo que es un conjunto infinito, con tuplas de cualquier aridad y dominio en cualquier posición.
Fórmulas Inseguras
Una formula insegura es aquella que permite resultados infinitos en consultas CRT (Calculo relacional de tuplas). Esto pasa porque el universo es infinito, por lo que pueden construirse consultas que hagan yield de resultados infinitos.
Dominio de una expresión CRT: Es el conjunto de todos los valores que aparecen como valores constantes en la expresión o bien existen en cualquier tupla de las relaciones a las que se hace referencia en la expresión
Se dice que una expresión CRT es segura si todos los valores de su resultado pertenecen al dominio de la expresión. Ejemplos:

Criterios generales
Para verificar que una formula es segura podemos:
- Pensar en la formula de la consulta y traducirla a \(\land \ \lor \ \lnot \).
- Si la formula tiene la forma \(\phi_1 \lor \dots \lor \phi_n \rightarrow\) Deben aparecer todas las variables libres en un predicado no negado.
- Si la formula tiene la forma \(\phi_1 \land \dots \land \phi_n \rightarrow\) Cada variable libre debe aparecer en al menos una \(\phi_i\) del predicado no negado.
Pragmática
Recordar que al realizar consultas, se accede a las claves de un elemento y luego se relacionan elementos a través de estas claves. Formulas útiles a recordar:

Calculo de Dominios
En el calculo relacional de dominios, el universo es todas las uniones de dominios que tenemos. En el calc. de dominios tenemos directamente los valores de los dominios, no trabajamos con tuplas.
Se suele usar el underscore para marcar variables que estarían con un existencial. Es como para decir que existe algo pero no me importa que es.
No todas las consultas son necesariamente resolubles en calculo. Por ejemplo, si tenemos una condición que implica "contar", puede que no sea posible formular una sentencia para la misma.
Structured Query Language (SQL)
Structured query language es el lenguaje comercial de consulta más aceptado, standard aprobado por ANSI e ISO en 1986. Existen varios dialectos de este: SQL-86,SQL-1999,SQL-2006,etc. Se pensaba que los gerentes iban a poder hacer consultas de forma directa usando SQL... lmao.
El SQL puede definirse en 3 partes:
- Data Definition Language (DDL): Create Table, Alter Table, etc. (Definir las tablas)
- Data Manipulation Language (DML): Insert, Delete, Update... (Modificar la instancia de una database)
- Query Language (Lo más famoso): Select, etc. (Hacer consultas)
También hay instrucciones para manejo de seguridad, manejo de restricciones, etc. A su vez cada DBMS implementa operaciones adicionales sobre SQL.
SQL vs Cálculo de tuplas
Una estructura básica de una consulta SQL tiene la forma:
\(SELECT T_1.a_2,T_2.a_5,\dots\) (Selecciono las tablas y sus atributos, estoy creando una nueva tabla "virtual en esta declaración") \(FROM T_1,T_2,\dots\) (Estoy eligiendo de donde vienen los datos que van a ser cargados a la tabla.) \(WHERE \phi\) (Declaro que es lo que deben cumplir los datos.)
En cálculo de tuplas sería algo como \(
Conceptos generales
En SQL se pueden anidar consultas. Las variables que se definen por fuera pueden ser referenciadas en las consultas anidadas. El asterisco en las consultas funciona como una wildcard. Equivale a listar todos los atributos de una tabla.
El WHERE EXISTS(...) equivale a decir que si existe algo en la consulta anidada entonces devuelvo algo (true).
IN y NOT IN es un operador que indica sobre que conjunto debe cumplirse la condición.
Existen operaciones adicionales posibles SQL que no se ven en el curso. Por ejemplo, recursividad, manejo temporal, consultas sobre tablas modificadas al "vuelo". También provee DDL y DML: Create Table, insert, delete, grant,etc. el as permite hacerle un alias a una tabla.
También puedo hacer operaciones aritméticas!!! Select fecha, numP producto, F.nombre, precioUnit*cantV from itemVta as F
Join
El problema de unir dos tablas con una key y una foreign key es un problema usual en las database. De ello surge el operador de Join que permite explicitar esta intención. Es decir, en lugar de imponer la igualdad de keys puedo usar el operador JOIN: \(SELECT nombre, #prod\) \(FROM (VENTAS OIN FABRICANTES ON VENTAS.#fab=FABRICANTES.#fab)\)
Otra opción es el NATURAL JOIN que elimina columnas con nombres repetidos \(SELECT nombre,#prod FROM (VENTAS NATURAL JOIN FABRICANTES)\)
Existen las variantes left join y right join que incluyen las entradas de la tabla respectiva que no tienen una foreign keys en su tabla compañera. También está ale FULL JOIN que hace que se incluya todo.
Clausulas de join adicionales:


SQL- DDL
Create table

El varchar[128] indica un string de largo variable topeada a 128 bytes. Existen otras palabras reservadas como unique, default, etc. Existen multiples tipos de datatypes. Numéricos, de tipo character-string, bit-string, boolean, date, timestamp, intervalos, etc.
También se pueden definir dominios usando CREATE DOMAIN nombre AS EX. Donde EX puede ser un tipo como CHAR(9)
SQL - Consultas
Recordar que las tablas SQL son un multiset de tuplas. Es decir, pueden haber elementos repetidos. Esto es diferente al calculo relacional donde se trabaja con sets de tuplas. La forma básica de una consulta SQL es:

In SQL, the basic logical comparison operators for comparing attribute values with one another and with literal constants are =, <, <=, >, >=, and <>. Los atributos especificados en el SELECT se les llama atributos proyectados. Y la formula lógica en el where se le conoce como selection condition. Se les llama join condition a las condiciones que combinan dos tuplas (por ejemplo, dos tablas).
Algunos operadores destacados:
- Select
- From <lista de tablas
- Where
- Group by
- Having
- Order by
El order by permite devolver las entradas de forma ordenada según un criterio. El primer atributo es el de mayor orden. Para indicar si se quiere ordenar de manera ascendente(default) o descendente un atributo se pueden usar las keywords DESC y ASC.
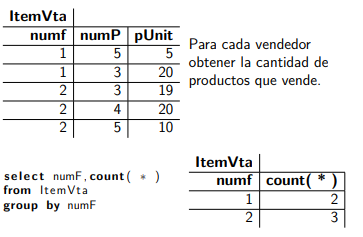
Existen funciónes agregadas y el modificador Distinct. Este ultimo hace que las funciones agregadas trabajen sobre valores en vez de trabajar sobre tuplas. La lista de atributos en el GROUP BY indica sobre qué atributos sse deben agrupar las tuplas de la tabla base. El resultado de la consulta es una tupla pro grupo. Por lo tanto, hay que garantizar que los valores de salida (Select) son únicos para cada grupo. La condición Having selecciona los grupos que quedan en el resultado. Ejemplo:

Algebra Relacional
Idea general
Tenemos un conjunto de operadores para consultar relational databases. Se define un conjunto de operaciones estándar y operadores que reciben y devuelven relaciones, tanto sobre conjuntos de tuplas (union,diferencia,cartesian product) como específicos para relational databases (selección, proyección, join, etc.)
Sintaxis
Cuando una sentencia se vuelve muy larga podemos darle un alias para utilizar más adelante: \(A \equiv \Pi{f,p}(fabs * Ventas) \) . Se puede cambiar de estrategia de mención de atributos al usar este alias: \(res \equiv A \bowtie{\)2=\(3} Prods\)
Selección
Permite obtener las tuplas que cumplen una cierta condición. Su sintaxis es \(\sigma{
Proyección
Permite obtener las tuplas con un cierto conjunto de atributos. Su sintaxis es \(\Pi_{
Union
La union no es más que la union de dos conjuntos de tuplas. Sin embargo, ambos sets de tuplas deben ser compatibles, esto es cuando tenemos los mismos dominios en el mismo orden en ambos esquemas. Ej: \(R \cup S\) da como resultado otra relación cuyo esquema es igual al de R (y S) y que tienen como conjunto de tuplas la union de los conjuntos de tuplas R y S.
Diferencia
Permite obtener la diferencia de dos relaciones tomadas por un mismo conjunto de tuplas. Tiene los mismos requerimientos que la union. \(R - S\) me devuelve una nueva relación con el mismo esquema de R y con las tuplas de R que no están en S
Intersección
Permite obtener la intersección entre conjuntos de tablas...
Producto Cartesiano
Permite obtener el producto cartesiano de dos relaciones tomadas como conjuntos de tuplas \((
Tengo que tener cuidado con los atributos con identificador repetido. Al suceder esto no tengo otra opción que referirme a los atributos utilizando referencias por posiciones. Esto se hace con la sintaxis \( \\)x,\\(y\) donde x e y son atributos según su posición en el esquema. Recordar que no se puede hacer un híbrido entre posiciones y nombre de los atributos.
Estos son los operadores básicos, toda consulta la puedo hacer con estos, aunque muchas veces quedan horribles. Se presentan operaciones adicionales para simplificar:
Join
Permite combinar tuplas de dos relaciones a través de una condición sobre los atributos. Corresponde a una selección sobre el Prod. Cartesiano de las relaciones. Su sintaxis es \((
Join Natural
El join natural se nota como \(R*S\) o \(R \bowtie S\). Es equivalente a realizar el \(\theta\) -join con la condición de igualdad entre los atributos de igual nombre y luego proyectar eliminando columnas con ese nombre repetido.
Como se ejecuta un Join?
Cuando se realiza un join entre relaciones (R y S), cada vez que una tupla R y otra de S cumplen la condición del join, se genera un tupla en el resultado. Para que se genere una tupla en el resultado alcanza con que exista una tupla en T y otra n S que se "conecten" por la condición del join.
División
Sean R y S dos relaciones con esquemas \((a_1,a_n,b_1,\dots,b_m)\) y \((b_1,\dots,b_m)\) respectivamente, la operación \(R \div S\) da como resultado otra relación con el esquema \((a_1,\dots,a_n)\) cuyo contenido es las tuplas tomadas a partir de las de r(R) tq su valor \((a_1,\dots,a_n)\) está asociado en r(R) con TODOS los valores (b_1,\dots,b_m) que están en s(S).
Observar que se le llama a esta operación cociente porque \(A=A \div B \times B + R\)
Algebra vs Calculo
Existen formulas que resuelven cada operador de algebra relacional en calculo. Mostrando que ambas formas son equivalentes.
Pasaje MER a Modelo Relacional
Como pasamos del esquema conceptual a un esquema lógico que siga siendo fiel a la realidad? (Equivalencia MER a Relacional) Se debe hallar una expresión equivalente para cada una de las estructuras del MER.
Dependencias de inclusión
Es otra restricción sobre el modelo relacional. Expresa que una proyección de ciertos atributos de una tabla debe estar incluida en la proyección de otros atributos de otra (o la misma ) tabla. EJ: \(\Pi{a1,a2}(A) \subseteq \Pi{b1,b2}(B)\)
Entidades
Por cada entidad se debe crear una tabla. Por cada atributo simple se crea un atributo en la tabla. Los atributos estructurados se crean tantos atributos como "hojas" tenga esta estructura. La clave primaria de la tabla se selecciona como uno de los atributos determinantes de la entidad. Los restantes atributos determinantes (si existen) se marcan como claves alternativas.
Los multivaluados se debe crear una tabla aparte que tenga como clave la clave de la tabla inicial y el multivalued. De esta forma tenemos una tabla que puede tener varias entradas para una clave pero combinaciones únicas de clave/atributo.
Recordar que las claves alternativas se marcan aparte. Las que van subrayado son siempre las claves primarias.
Relaciones
N:N
Para cada relación binaria con cardinalidad N:N se crea una tabla donde: Se colocan las claves primarias de las tablas que representan a cada una de las entidades participantes. Si existen atributos en la relación se tratan como si fuesen los de una entidad. La clave primaria está formada por los atributos correspondientes a las claves primarias de las tablas que representan las entidades participantes.
A su vez, por cada entidad participante en una relación se agrega una dependencia de inclusión: Sea R la tabla de la relación y Q la tabla de un participante: \(\Pi_{qpk}(R) \subseteq \Pi{q_pk}(Q)\) . si la relación R es total sobre Q, se agrega también la inclusión al revés.
La estrategia es análoga para las relaciones ternarias. (N:N:N)
1:N
Se divide en dos casos: 1:N con y sin totalidad del lado N. Si es con totalidad del lado N, no se crea tabla para la relación y se agrega la clave de la tabla de la entidad del lado 1 en la tabla de la entidad del lado N. En el otro caso se trata como una N:N excepto por la primary key que es la clave del lado N.
Entidades débiles
Por cada entidad de bil se crea una tabla. Se procede con las relaciones 1:N y totales del lado N, no creando la tabla de la relación y agregando la clave primaria de la tabla de ela entidad fuerte en la tabla de la entidad débil. La clave primera de esta tabla va a ser la clave de la entidad fuerte + los atributos que son identificadores parciales.
Agregaciones
Se crea una tabla con las claves primarias de la tabla creada anteriormente para la relación.
Categorizaciones
Hay diferentes opciones de implementación. Existen por lo menos 4 formas de implementarlas:
- Por joins: Se aplica a cualquier caso, aunque puede tener menos performance que el caso 4. En esencia tengo tablas para las especializaciones y la entidad general. Cada tabla con sus atributos y una primaryKey que es semanticamente compartida con la clase principal.
- Por vistas: Si es total (General = esp1+esp2+esp3). Tengo las tablas especializadas con sus atributos y claves. Tengo la entidad general como una vista: Esto es un conjunto de tuplas definido por comprensión en base a las especializaciones: \(Personal \equiv {
- Con atributo de tipo: Si es disjunta. Tengo una única tabla con todas los atributos de todas las especializaciones. Tengo un atributo extra tipo que indica que tipo de especialización es (y por ende que atributos son validos). Puedo tener instancias de tuplas con atributos nulos!!!
- Con atributo booleanos: También se puede aplicar en cualquier caso, aunque suele gastar mas memoria que el caso 1. Es análogo al caso 3, pero en vez de tener un atributo tipo tengo booleanos para cada especialización indicando si la tupla pertenece a alguna de estas (o a ninguna). Los atributos validos van a ser aquellos donde el booleano vale true.
Vistas: Consultas con un nombre.
Dependencias Funcionales
Como podemos evaluar la calidad de un schema? Algunas medidas informales son:
- Semántica de los atributos
- Reducción de valores redundantes en tuplas
- Reducción de los valores nulos en tuplas
- No generación de tuplas erroneas.
De estos se derivan las siguientes pautas:
Diseñe un esquema de relación de modo que sea fácil explicar su significado. No combine atributos de varios tipos de entidades y tipos de vínculos en una sola relación.
Diseñe los esquemas de las relaciones de modo que no haya anomalías de inserción, eliminación o modificación en las relaciones. Si hay anomalías señálelas con claridad a fin de que los programas que actualicen la BD operen correctamente.
Hasta donde sea posible, evite incluir en una relación atributos cuyos valores pueden ser nulos. Si no es posible, asegúrese de que se apliquen solo en casos excepcionales y no a la mayoría de las tuplas de una relación.
Diseñe los esquemas de modo que puedan reunirse por condición de igualdad sobre atributos claves, para garantizar que no se formen tuplas erróneas.
Es decir, se quiere evitar las anomalías en la inserción, modificación y eliminación de tuplas por redundancia. El desperdicio de espacio y dificultad para las operaciones por valores nulos y la generación de datos erroneos por joins hechos relacionando mal las relaciones.
Para evitar estos errores se presentaran conceptos y teorías formales que permitan detectar y evitar estos problemas.
Definición
Una dependencia funcional \(X \rightarrow Y\) entre 2 conjuntos de atributos X e Y que son subconjuntos de R, especifica una restricción sobre las posibles tuplas que formarían una instancia r de R. Esta restricción es \((\forall t_1,t_2 \in r)(t_1[X]=t_2[X]\rightarrow t_1[Y]=t_2[Y])\) donde \(t_1 y t_2\) son dos tuplas pertenecientes a \(r\) . En español, \(X \rightarrow Y\) implica que si una tupla tiene los mismos valores en X, entonces tiene los mismos valores en Y. Ejemplo: \({Nombres,Apellidos} \rightarrow {CI}\)
Clausura de \(F: F+\)
Se define \(F\) como el conjunto de dependencias funcionales que se especifican sobre un esquema de relación R y \(F+\) el conjunto de todas las dfs que se cumplan en todas las instancias que satisfacen a F.
Las reglas de inferencia permiten identificar a \(F+\):
- (RI1) reflexiva - Si \(X \rightarrow Y\), entonces \(X \rightarrow Y\)
- (RI2) de aumento - \({X \rightarrow Y}\) |= \(XZ \rightarrow YZ\)
- (RI3) transitiva - \({X \rightarrow Y, Y \rightarrow Z} |= X \rightarrow Z\)
- (RI4) descomposición - \({X \ rightarrow YZ} |= X \rightarrow Y\)
- (RI5) unión - \({X \rightarrow Y, X \rightarrow Z} |= X \rightarrow YZ\)
- (RI6) pseudotransitiva - \({X \rightarrow Y, WY \rightarrow Z} |= WX \rightarrow Z\)
Las reglas RI1-RI3, son minimales y se las conoce como Reglas de Armstrong.
Clausura de \(X\) bajo \(F\): \(X+\)
\(X+\) es el conjunto de atributos determinados funcionalmente por \(X\)
Se presenta un algortimo para determinar \(X+\) bajo F:

Equivalencia de conjuntos funcionales
Dos conjuntos de dfs E y F son equivalentes \(\leftrightarrow E+ = F+\) . Esto es, todas las dfs en E se pueden inferir de F y todas las dfs en F se pueden inferir de E. E cubre a F y F cubre a E.
Para cada df \(X \rightarrow Y \in E\) calculamos \(X+(F)\) y verificamos que \(X+\) incluya los atributos de Y. Si se cumple para todas las dependencias, entonces estas son equivalentes.
Conjunto minimal de dfs.
Un conjunto de dfs es minimal si y solo si:
- Toda df en F tiene un solo atributo a la derecha
- No podemos reemplazar ninguna df \(X \rightarrow A \in F\) por una df \(Y \rightarrow A\), donde \(Y \subset X\) y seguir teniendo o un con conjunto de dfs equivalente a F.
- No podemos quitar ninguna df de F y seguir teniendo un conjunto de dfs equivalente a F.
Se le llama cubrimiento minimal de F al conjunto minimal \(F_{min}\) que es equivalente a \(F\).
Algoritmo para hallar un cubrimiento minimal:

Formas normales
Las formas normales son como un "certificado" que indique que un esquema de relación cumple un conjunto de buenas propiedades. La normalización puede entenderse como el proceso donde los esquemas de relación (er) insatifactorios se descomponen repartiendo sus atributos entre esquemas de relación más pequeños que poseen propiedades deseables.
Adicionalmente, la normalización no aseguro un buen diseño de BD que cumpla estas dos propiedades importantes:
- Join sin pérdida (JSP)
- Preservación de despendencias (PDD)
Definiciones
Superclave: Una superclave de \(R={A_1,...,A_n}\) es un conjunto de atributos \( S \subseteq R\) tal que no existen 2 tuplas distintas \(t_1, t_2\) tq \(t_1[S]=t_2[S]\)
Clave: Una clave \(K\) es una superclave que cumple que si se le quita alguno de sus atributos deja de ser superclave.
Clave candidata, clave primaria: Si una relación tiene más de una clave, cada una es una clave candidata. Una de ellas es arbitrariamente designada como clave primaria. El resto son secundarias.
Atributo Primo: Un atributo del esquema de relación R es primo si es miembro de alguna clave de R.
Dependencia Total: \(X \rightarrow Y\) es una df total si la eliminación de cualquier atributo \(A\) de \(X\) hace que la df deje de ser válida. (Esto es, no hay atributos redundantes a la izquierda)
Dependencia Parcial: \(X \rightarrow Y \)es una df parcial si es posible eliminar un atributo \(A\) de \(X\) y que la df siga siendo válida (I.e dependencia NO total)
Dependencia Transitiva: \(X \rightarrow Y\) es una df transitiva si existe un set de atributos \(Z\) que no sea un subconjunto de una clave R, y se cumple tanto \(X \rightarrow Z\) como \(Z \rightarrow Y\)
Formas Normales
Primera Forma Normal (1NF): Los dominios de los atributos deben incluir solo valores atómicos (no pueden haber atributos multivaluados o compuestos)
Segunda Forma Normal (2NF): Está en 1NF y Ningún atributo no primo \(A\) de \(R\) depende parcialmente de cualquier clave de \(R\) . En otras palabras, dada una clave y cualquier atributo que no sea un constituyente de dicha clave, el atributo no clave depende de solo una parte de la clave en vez de ella entera.
Tercera Forma Normal (3NF): Está en 2NF y ningún atributo no primo de R depende transitivamente de una clave de R. Un esquema de relación R está en 3NF si, siempre que tenemos una df \(X \rightarrow A\) se cumple en R, alguna de las 2 siguientes:
- \(X\) es una superclave de R
- A es un atributo primo de R
Forma Normal de Boyce-Codd (BCNF): Un esquema de realción está en BCNF si, siempre que una df \(X \rightarrow A\) se cumple en R, entonces X es una superclave de R.
Algoritmos de Diseño
Definiciones
Esquema de relación universal R: Se define \(R=(A_1,A_2,\dots,A_n)\) que contiene todos los atributos de la DB.
Descomposición de R: D: \(D=(R_1,R_2,\dots,Rm)\) que se obtiene mediante los algoritmos que realizan la descomposión utilizando las dependencias funcionales. Debe verificarse que \(\bigcup{i=1}^m R_i = R\) (La unión de la descomposión de ni mas ni menos que todo el esquema universal.)
Proyección de un conjunto de dependencias sobre un Esquema de Relación: Dado un conjunto de dfs \(F\) sobre R, la *proyección de \(F\) sobre \(Ri\), \(Pi{R_i}(F)\), donde \(R_i\), es un subconjunto de R, es el set de dfs \(X \rightarrow Y\) en \(F+\) tq los atributos de \(X \cup Y\) estén todos contenidos en \(R_i\)
Preservación de dependencias (PDD): Una descomposición \(D=(R_1,\dots,Rm)\) de R preserva las dependencias respecto a F si se cumple: \(((\Pi{R1}(F))\cup \dots \cup (\Pi_{Rm}(F)))+ = F+\)
Descomposición 3NF con Pres. de Dependencias (PDD)
Algoritmo
1. Encontrar un cubrimiento minimal G para F
2. For each miembro izq X de las df de G:
2.1 crear un esquema de relación {X union A_1 ... A_m} en D, donde X ->A_1, ... , X->A_m sean las únicas dfs en G con X como miembro izq.
3. Colocar todos los atributos restantes (que no fueron colocados en ningún esquema) en un solo ER para asegurar la prop. de preservación de dependencias (PDD)
Join sin Pérdida (JSP)
Definición: Una descomposión \(D=(R_1,R_2,\dots,R_m)\) de R tiene la propiedad de JSP respecto al conjunto de dfs F sobre R, si por cada instancia de relación r de R que satisfaga F, se cumple lo siguiente: \( \ast^m1((\Pi{R1}(r)),\dots,(\Pi_{Rm}(r)))=r\)
Propiedad: \(D=(R_1,R_2)\) de R tiene JSP respecto a F sobre R si y solo si: la df \(((R_1 \cap R_2) \rightarrow (R_1 - R_2) \in F+)\ \lor \ ((R_1 \cap R_2) \rightarrow (R_2 - R_1) \in F+)\)
Algoritmo
1. crear una matriz S con una fila i por cada relación Ri en la descomposición D, y una columna j por cada atributo Aj en R;
2. hacer S(i,j) := bij para todas las entradas de la matriz;
3. For each fila i que represente el er Ri:
For each columna j que represente el atributo Aj:
if Ri incluye a Aj
S(i,j) := aj;
4. while la iteración modifique S:
For each df X->Y en F
igualar los símbolos en los atributos de Y para aquellas filas que coinciden en los atributos de X;
5. si una fila tiene todos símbolos “a”, la desc es con JSP, en caso contrario, no lo es;
Algoritmo Descomposición en BCNF con JSP
1. Hacer D:={R};
2. While haya un esquema de relación Q en D que no esté en BCNF hacer:
2.1 Escoger un esquema de relación Q en D que no esté en BCNF;
2.2 Encontrar una df X->Y en Q que viole BCNF;
2.3 Reemplazar Q en D por dos esquemas (Q-y) y (X union Y)
Algoritmo Descomposición en 3NF con JSP y PDD
1. Encontrar un cubrimiento minimal G para F;
2. For each miembro izq X de una df que aparezca en G:
2.1 crear un esquema de realción {X union A_1 union A_2 ... union A_1m} en D, donde X->A_1,X->A_2,...,X->A_m sean todas las dfs en G con X como miembro izq.
3. Si alguno de los esquemas de realción contiene una clave de R, crear un ER adicional que contenga los atributos que formen una clave de R;
4. Eliminar ER redundates, es decir que estén contenidos en otro ya generado.
Dependencias Multi-valuadas
Idea intuitiva
Si se tienen 2 o más atributos que tienen más de un valor asociado con determinado objecto y que son independientes entre sí, se tendrán que repetir todos los valores de uno de los atributos con cada valor del otro atributo manteniendo la misma referencia para los objetos con el fin de que las tublas de la relación sigan siendo consistentes. Esta restricción se le llama dependencia multi-valuada.
Definición Formal
Una dependencia funcional multivaluada \( X \twoheadrightarrow Y\) especificada sobre el esquema de relación R, especifica la siguiente restricción sobre cualquier relación r de R:
Si existen 2 tuplas \(t_1 y t_2 \) en r tales que \(t_1(X)=t_2(X)\) , entonces deberán existir también 2 tuplas \(t_3, t_4\) en r tales que:
- \( t_3(X)=t_4(X) = t_1(X)=t_2(X)\)
- \( t_3(Y)=t_1(Y) = t_4(Y)=t_2(Y)\)
- \( t_3[R-XY] = t_2[R-XY], t_4[R-XY] = t_1[R-XY] \)
DVM Trivial
Se le llama dmv \( X \twoheadrightarrow Y\) trivial si \( Y \subseteq X \) o \( X \cup Y = R\) Tener una dmv no trivial en una relación implica tener valores redundantes en las tuplas.
Reglas de inferencia

Cuarta forma normal
Un esquema de relación R está en 4NF respecto a un conjunto de dependencias F si para cada dmv no trivial \( X \twoheadrightarrow Y\) en F+, X es una superclave de R.
Recordamos la propiedad de descomposición con JSP: D=(R_1,R_2) tiene JSP respecto a F sobre R sii La dmv \((R_1 \cap R_2) \twoheadrightarrow (R_1 - R_2) \in F+\)
OR
La dmv \((R_1 \cap R_2) \twoheadrightarrow (R_2 - R_1) \in F+\)
Algoritmo 4nf con JSP:

Dependencias multi-valuadas embebidas
Decimos que en un esquema de relación \(R\) se cumple la dependencia \(X \twoheadrightarrow Y | Z\) cuando en cualquier subesquema \(R_i\) de \(\)R\( tal que \)R_i = X \cup Y \cup Z\( se debe cumplir la dependencia \)X \twoheadrightarrow Y\(
Decimos que \) X \twoheadrightarrow Y |Z \( es una dependencia multivaluada embebida sobre R.
Estrategias de un Relational Database Management system
Un DBMS se puede dividir en 3 planos:
Comunicación con el usuario: Aquí están las APIs e interfaces que los clientes utilizan para acceder a la DB. Por ejemplo, consultas interactivas (tipo consola), enunciados en DDL y ordenes privilegiadas para los administradores, APIs con pre-compiladores para los programadores, etc. Los usuarios paramétricos pasan directamente al plano de gestion de operaciones con transacciones previamente programadas
Gestion de operaciones: En la gestion de operaciones se define como se va a acceder a la base de datos, la estrategia para responder a las consultas. procesador de base de datos lee estas sentencias del DML compiladas para decidir el mejor plan para llevar a cabo la consulta.
Gestion de datos: Los datos de la base literalmente. Que estrategias se van a utilizar para leer los datos (indexes, algorithms, etc.). También se incluye el sub-sistema de control de concurrencia y recuperación.
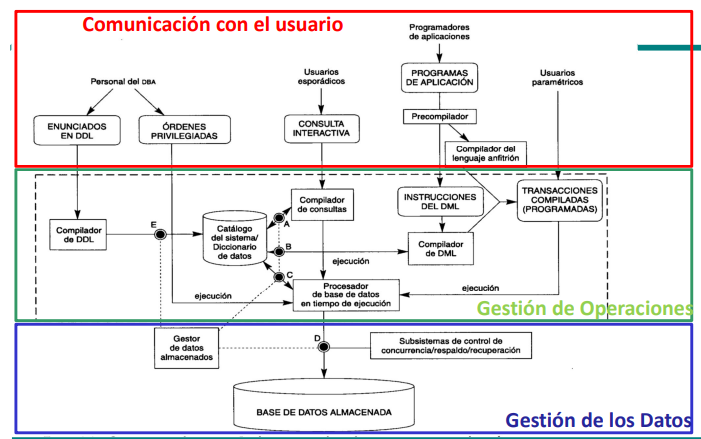
Procesamiento y organización de consultas.
Se distinguen 6 conceptos clave:
Organización y acceso a los datos: Definir las estructuras de datos que implementan los DBMS y como se utilizan
Procesamiento de consultas: Los algoritmos que implementan los operadores del algebra relacional.
Optimizacion de consultas: Estrategias que utiliza el manejador para modificar las consultas (pero manteniendo la equivalencia) y elegir los algoritmos a ejecutar.
Transacciones: Entender a un conjunto de operaciones complejas como algo atomico y cuantificable.
Concurrencia: Considerar que el DBMS debe poder permitir que varios procesos accedan a la base de datos de forma simultanea y manejar las situaciones que esto genera.
Estrategias de recuperación: Mecanismos que implementa el DBMS para asegurar la integridad de la bse de datos (recuperación) ante fallas en el sistema.
Organización física de las consultas
Los registros (tuplas) de una tabla se encuentran y forman archivos los cuales son una estructura lógica de acceso secuencial del file system. Estos archivos se ubican en una estructura lógica a nivel de disco llamada bloques. Estos bloques son la minima unidad de transferencia de datos entre la memoria y el disco. Un conjunto de bloques de disco constituye una particion. Los bloques del disco al ser leidos se mueven a memoria a trabas de buffers. Es en este punto que los datos pueden ser recién leidos por el DBMS.
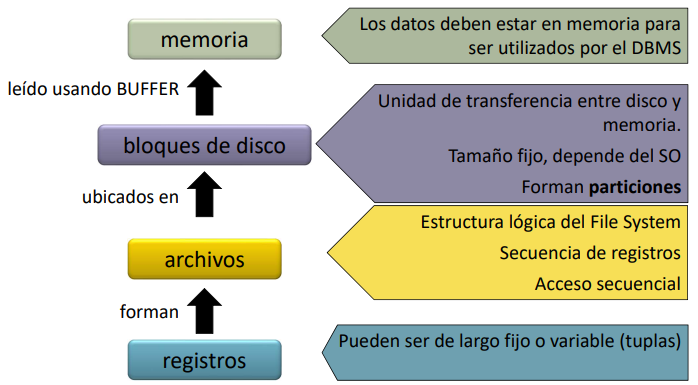
Dado que el acceso a datos es un aspecto esencial de un DBMS, estos implementan mecanismos que optimizan todo el proceso de acceso a los datos. Reimplementado: estructuras de datos, algoritmos de manipulaicon y organización y mecanismos de buffereing y paginado. En cierto sentido, los DBMS implementan su propio filesystem en un area de l disco.
El acceso secuencial de los discos no es siempre ventajoso para las consultas. Se hacen loops innecesarios para buscar cosas y para los joins. Por ejemplo, los JOINS de dos tablas costarian O(MxN) lo cual es costoso. Esto se puede mejorar utilizando estructuras que faciliten el acceso al disco a entradas en particular (i.e indices).
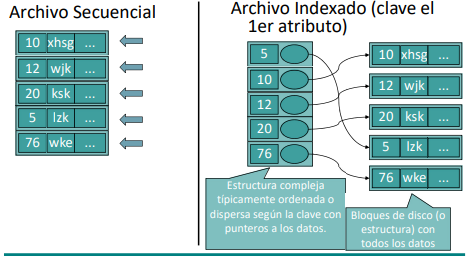
El indice es una estructura compleja típicamente ordenada o disperasa según la clave con punteros a los datos. Buscar algo en un indice es mas eficiente que la busqueda secuencial.
Tipos de indices
Físicos v Lógicos : Los index físicos son del estilo donde
Ordenados vs No-Ordenados : Requieren o no del ordenamiento de los datos en la database de los atributos a indexar.
Densos o no densos: Un index denso tiene una entrada para valor de busqueda posible. Mientras que un indice no denso (sparse) tiene entradas para solo algunos valores. Un indice primario es un ejemplo de indice sparse.
Simples vs Multi-nivel: El index tiene la ubicación directa del sector o se deben hacer varios accesos (ya sea a memoria o disco) para obtener la ubicación. Ejemplo clásico: Ordered list vs B+ tree.
Indices ordenados
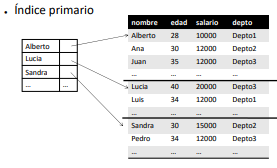
Indice primario: Es sobre la primary key de la tupla. Por cada clave se tiene la dirección en el disco: (bloque o bloque+offset)
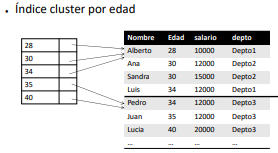
De Agrupamiento (cluster index): Se realizan sobre atributos que no son clave primaria. For each valor distinto, se agrega una entrada con la dirección en el disco al primer registro del grupo (bloque o bloque + offset). Es un ejemplo de index sparse. Notar que se necesita que los registros estén ordenados por los tipos de datos no primarios (clustering field), a estos archivos se llaman clustering files.
Indices con datos no ordenados
Indices secundarios
Se crean estructuras auxiliares ordenadas por el campo a indexar. Por cada entrada de index hay un puntero al bloque donde se encuentra el valor. (Si tengo muchos valores, tengo una lista con punteros como tantos bloques contengan el valor).
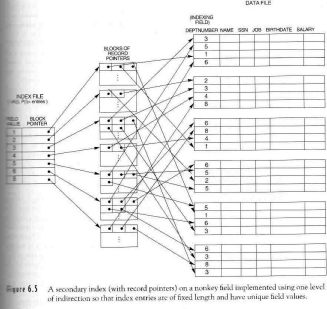
Otras estructuras de index
Hash
Andan bien para la inserción y la recuperación de condiciones por igualdad. Sin embargo no proporcionan un buen funcionamiento para condiciones de ordenamiento.
Arboles B y B+
Buen comportamiento en recuperación tanto para condiciones de igualdad como de orden. Anda bien para la inserción, la contra es que ocupa espacio adicional en el disco. Animación B-Tree. La diferencia clave entre un B tree y un B+ tree es que en el B+ los datos están unicamente en las hojas del árbol:
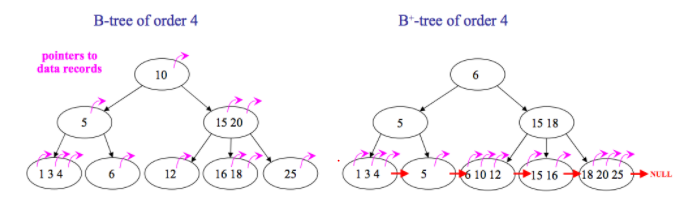
Por lo general, como la mayoria de los datos de un árbol B terminan estanado en las hojas. Es mas eficiente el árbol B+.
Para comparar las estructuras se utiliza la metrica mas relevanate: Cantidad de operaciones I/O. Se debe considerar que un bloque del disco puede almacenar varios nodos de una estructura de datos. Y que el acceso al disco, se hace por lo general con buffers que leen simultaneamente mas de un bloque. Esto ultimo trae mejoras en los lagoritmos.
Resumen
Los DBMS implementan las siguientes estrategias para organizar registros:
- Registros desordenados con acceso sequential.
- Registros ordenados con acceso secuencial.
- Registros ordenados e indexados por clave primaria con indice primario
- Registros ordenados e indexados por otro atributo con un indice cluster
- Registros desordenados e indexados por otro atributo con un indice secundario
- Indices implementados como hashes o arboles B+
Procesamiento y optimización de consultas
El proceso de resolución de una consulta se ilustra en esta imagen:
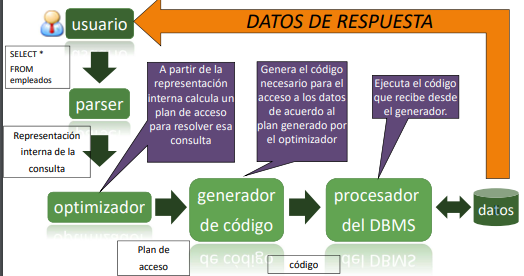
Este proceso puede optimizarse en sus distitnas fases. Existen 2 tipos de optimizacion:
- Optimización Heurística: Basada en equivalencia de las expresiones del algebra y ciertas estrategias básicas para limitar el tamaño de los resultasos
- Optimización por Costos: Basada en estimaciones4s y datos del catálogo que permiten seleccionar mejor el plan de acceso.
El parser y generador de código realizan los siguientes pasos para trabajar:
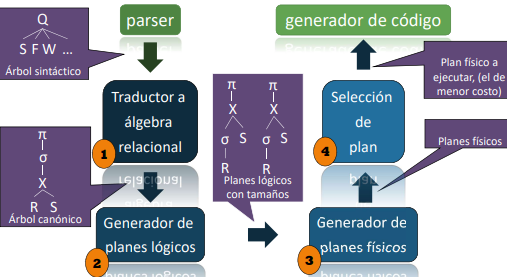
Los pasos del proceso de optimización son:
Generación del Algebra (+ Árbol canónico)
Generacion de planes lógicos (Optimización heuristica). Implica la aplicación de las heurísticas y consultas al catalogo para conocer el tamaño de las relaciones para transformar el árbol original
Generacion de planes físicos (Optimizacion por costos). Implica asociar a cada operacion los planes lógicos generados por una o mas implementaciones. Depende de las estructuras de datos disponibles.
Selección del plan final (Optimizacion por costos). Implica la evaluacion de lso planes físicos generados en base a la cantidad de operaciones IO de cada algoritmo.
Optimizacion por heuristicas
Cambiar la consulta original por otra equivalente para minimizar los resultados intermedios. Pueden existir varias formas y se basa en aplicar equivalencias de los operadores del algebra para que las selecciones y las proyecciones se apliquen lo antes posible.
Reglas de equivalencia:

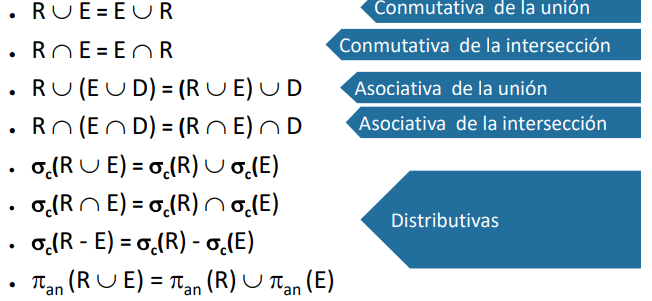
Heurísticas
Las reglas que se aplican para reducir los tamaños intermedios son:
- Cambiar selecciones conjuntuivas por una cascada de selecciones simples.
- Mover las selecciones lo mas abajo que se pueda del árbol
- Poner a la izquierda los productos de las hojas que generen menos tuplas, asegurando que el orgfen de las hojas cno cause operaciones de producto cartesiano
- Cambiar secuencias de selecciones y productos por joins
- Mover las proyecciones lo mas abajo posible del árbol, agregando las proyecciones que sean necesarias.
Optimizacion por costos
Plan físico
Le asocia a cada operador del algebra que aparece un un plan lógico una implemetnacion. Como se pueden considerar diferentes implementaciones para cada operador, entonces un mismo plan lógico puede originar diferentes planes físicos. Se estima el costo de cada uno mediante parametros que consideran la cantidad de operaciones IO.
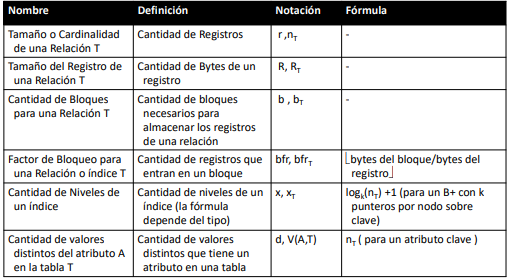
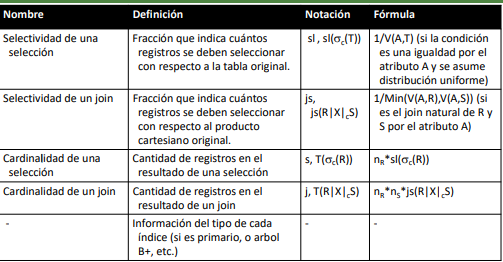
Implementaciones de los operadores
A cada operador de un plan lógico se el asigna una implementación. Hay que estimar los costos según cada algoritmo. Es importante la estrategia de implementation:
- Pipelines: Hay operadores que se ejecutan simultaneamente y pueden pasarse los resultados a medida que se generan. No graban resultados intermedios
- No pipelined: Los operadores se ejecutan secuencialmente y es necesario grabar resultados intermedios.
En este curso vamos a asumir que la selección y el join es no pipelined y la proyección es pipelined (tiene sentido desu)
En el costo se considera solo los acceso a disco (IO). Siempre se realizan operaciones de a bloque (pagina), las cuales contienen varios registros de indice o datos. Los costos de lectura dependen de como están organizados.
El costo de grabación siempre es el costo de grabar todo el resultado (R): \)\lceil n_r / bf_r \rceil \( donde \)bf_r = #bytesXbloque / #bytesXtupla \(.
Implementación de la selección
Búsqueda lineal: No tiene restricciones de uso. Lee cada registro uno a uno y si cumple la condición se lo pone en el resultado. Es \)O(b_r)\( (promedio \)b_r/2\( )
Búsqueda binaria: Requiere que los registros estén ordenados. Lee el bloque del medio y en función de una función de orden decide buscar hacia la izquierda io derecha. El costo de lectura de esto es \)log_2 (b_r) + \lceil s / bf_r \rceil -1\(
Con índice primario o cluster: Requiere registros ordenados. El costo es \) x + \lceil s / bf_r \rceil \( (x = cant. niveles del indice)
Hash: Solo sirve para condiciones de igualdad. Los costos de lectura son 1 o 2 dependiendo del tipo de Hash.
Secundario con B+: No tienen restricción. El costo es \)O(x+s)\(
Implementación del Join R |><| (A=B) S
Loop anidado por registros: No tiene restricciones de uso. Para cada registro de R, acceder a todos los bloques de S y combinar ese registro R con todos los de S. El costo es \)O(b_R + n_R*b_s)\(
Loop anidado por bloques: No tiene restricciones de uso. Para cada bloquede R, combinar todos los registros de ese bloque con todos los de S. El costo es \)O(b_r + \lceil b_r / (M-2) \rceil * b_s\( donde M es la cantidad de buffers.
Sort-Merge Join: Requiere que las dos tablas tengan los registros ordenados. De lo contrario hay costo de ordenarlas. Se recorre R y S en paralelo combinando los registros. Costo \)O(b_r + b_s)\( si se tuviese que ordenar el costo de ordenar sería \)2 b (1+log_2 b)\(
Index Join (Single loop): Tiene que existir un índice para S. Consiste en recorrer R y acceder por el índice a S. El costo es O(b_r + n_r * Z) donde Z depende del tipo de indice.
- Secundario: Z = x+s_s
- Cluster Z = x + \lceil s_s / bf_s \rceil
- Primario: Z= x+1
- Hash = h
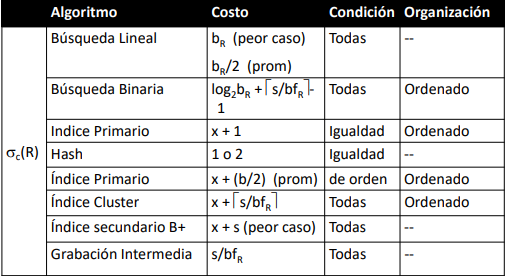
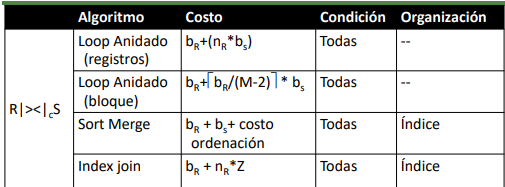
Control de Concurrencia y Recuperación
Control de concurrencia es la coordinación de procesos concurrentes que operan sobre datos compartidos y que podrian interferir entre ellos.
A cada uno de los procesos concurrentes que se ejecuta sobre datos compartidos se le llama TRANSACCIÓN si cumple las propiedades ACID.
- Atomicity: Desde el punto de vista del resultado, este se ejecuta totalmente o no.
- Consistency preservation: La base de datos siempre cambia de un estado consistente a otro consistente.
- Isolation: Una transacción no debe interferir con otra.
- Durability: Los cambios de una transacción confirmada deben persistirse en la database
Para garantizar el ACID, las transacciones pasan por los siguientes estadoS:
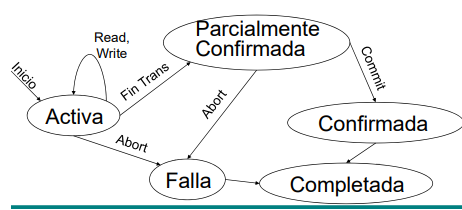
Notación y Definiciones
Las transacciones realizan las siguientes operaciones que se notan:
- \)r_i(X)\( : La transaccion i lee el item X de la base
- \)w_i(X)\( : La transaccion i escribe el item X de la base
- \)c_i\( : La transaccion i confirma que todas sus modificaciones son persistidas en la base
\)a_i\( : La transacción i indica que ninguna de sus modificaciones son persistidas en la base
Rollback: Es la accion de recuperar el estado anterior de la base de datos frente al abort de una transacción.
- Transaction Manager: Es el que administra las transacciones. Recibe las instrucciones que los programas preteneden ejecutar y se toma la libertad de reordenarlas, sin cambiar el orden relativo de los R/W. Para esto agrega instrucciones (aborts/commits) por su cuenta y demora las instrucciones.
- Historia (Schedule): Dado un conjunto de transacciones se le llama historia o schedule a una ordenación de todas lasoperaciones que interviene nen las transacciones siempre que estas aparezcan en el mismo orden que la transaccion
Historia Completa: Es la historia que cumple que todas las operaciones de las transacciones están presentes. Cualquier par de la misma transaccion debe aparecer en la historia en el mismo orden que en el de la transaccion. Las operaciones en conflicto deben tener su orden d3e aparición definido en la historia.
Operaciones en conflicto: dos operaciones (R/W) están en conflicto si cumplen: (pertenecen a distintas transacciones && acceden al mismo item && una es un write)
Historia Recuperable: Una historia es recuperable si ninguna transacción confirma lista que se confirmar on todas las transacciones desde las cuales leyó items. (Los commits están en el mismo orden que el flujo de datos ).
Historia que evita Abortos en Cascada: Una historia evita abortos en cascada si ninguna transacción lee de transacciones no confirmadas. (Los commits tiene que estar antes de lso reads siguientes)
Historia Estricta: Una historia es estricta si ningúna tarnsaccion lee o escriba hasta que todas a las transacciones que escribireron ese ítem fueron confirmadas (los commits tienen que estar antes de lso reads y writes siguientes)
Historias serializables y recuperables
Si las operaciones se ejecutasen de forma serial, no habria concurrencia pero si correctitud. Si las historias son entrelazadas, podría suceder que queden datos erroneos que no se puedan corregir (hacer un rollback) si una transacción aborta. Por lo tanto, se quieren historias entrelazadas y con comportamiento de seriales.
Historia serializable: Es aquella historia que es equivalente a una historia serial con las mismas transacciones. Que significa equivalente? Existen dos nociones que siguen la idea de que las transacciones son equivalentes si dejan la base de datos en el mismo estado. Esta idea es difícil de garantizar, por lo que se utilizan las siguientes definiciones de equivalencia\
- Por conflicto: Si las transacciones tienen todas las operaciones en conflicto en el mismo orden estas son equivalentes (CURSO)
- Por vistas: Si cada \)T_i\( lee las mismas \)T_j, \dots ,T_n\( en \)H\( y \)H'\(
Testeo de seriabilidad por conflictos: Grafo de seriabilidad
- Poner un nodo por cada transaccion en la historia. Si \)r_j(X)\( está después de \)w_i(X)\(, entonces hay un arco de \)T_i\( a \)T_j\(.
- Si \)w_j(X) está después de \(r_i(X)\), entonces hay un arco de \(T_i a T_j\)
- Si \(w_j(X) estád después de \)w_i(X)\( entonces hay un arco de \)T_i\( a \)T_j\(
Es decir, siempre se pone un arco si hay una Pareja de operaciones en conflicto, desde la primera transaccion a la segunda según del orden de las operaciones en conflicto.
Teorema de Seriabilidad
Una historia H es serializable si su grafo de seriabilidad es acíclico. (Gray, 1975)
Clasificación de historias
Con las definiciones estudiadas, podemos concluir que:
Control de seriabilidad y recuperación
El manejador deberia garantizar la construcción de historias serializables, que sean recuperables y que no tangan abortos en cascada. El manejador para esto demora las operaciones en conflicto con otras anteriores hasta que estas terminen. Los dos mecanismos para hacer esto es el de locking y timestamp.
Locks
Lock binario
Se consideran dos nuevas operaciones: \)l_i(X)\( lock y \)u_i(X)\( unlock. Cuando se ejecuta \)l_i(X) el DBMS hace que cualquier operación sobre X por otra transaccion no termine hasta que se ejecute \(u_i(X)\) . Es un comportamiento analogo a los semáforos de SO. La ventaja de estos locks es que son fáciles de implementar. Lo malo es que niega la lectura a otras transacciones cuando en realidad no seríá necesario.
Para utilizarlo hay que hacer que antes de hacer un r/w sobre X ejecutar l(X), luego de ejecutar el r/w se debe ejecutar u(X)
Read/Write Lock
Hay tres operaciones \(read_lock_i(X)\) \((rl_i(X))\), \(write_lock_i(X)\) \((wl_i(X))\) y \(unlock_i(X)\) \((u_i(X))\) . Se permite que varias transacciones hagan un rl (pero no un wl) simultáneamente sobre el mismo ítem. Es mas complejo que el lock binario.
Para utilizarlo hay que hacer que antes de un read, hacer un read_lock o write_lock, al terminar un unlock Si se quiere hacer un write, se debe pedir el write lock. Los looks pueden ser promovidos o degradados en vez de desbloquearse
Protocolos de Locking
Los locks en si no garantizan la seriabilidad. Para ello se necesita un protocolo de locking: un conjunto de reglas del uso de los locks que sean mas fuertes que las anteriores y que si garanticen la seriabilidad .
2PL
Two phase locking dicta que una transacción tiene 2 fases: la fase de crecimiento y la de contración. En la primera se crean locks y en la segunda se liberan. Una funcion de locks sobre el tiempo tendría la forma de un pico de sierra.
Existen distintas formas de 2PL.
- 2PL Básico: 2 fases. Susceptible a deadlock
- 2PL Conservador: Se exige que todos los locks se hagan al comienzo de la transacción. No es susceptible a deadlock, pero require saber de antemano todos los items que se van a leer/escribir (no siempre es posible)
- 2PL Estricto: Exige que no se libere ningún write lock hasta despues de terminar la transacción. Garantiza historias estrictas, susceptible a deadlock.
- 2PL Riguroso: Existe que no se libere ningún write/read lock hasta despues de terminar la transacción. Es más fácil de implementar que el estricto y es susceptible a deadlock.
Deadlock
Se da cuando una o mas transacciones esperan por otras. Podemos determinar si hay un deadlock construyendo un grafo de espera. Si encontramos un ciclo... encontramos un deadlock!!
Soluciones para Deadlocks
Existen los protoclos que previenen deadlocks: El 2PL conservador (aunque NO funciona en la practica 😞 ). Y los protoclos basados en TimeStamp. La idea de estos es: Cada transacción tiene asociado un timestamp único que permite discernir que transaccion empezó antes que otra. Si asumimos que T_i quiere un lock que tiene T_j, se pueden seguir las siguientes estrategias:
- Wait-die: Si TS(T_i) < TS(T_j) entonces T_i está autorizada a esperar. Si TS(T_i) > TS(T_j), T_i aborta y comienza más tarde con el mismo timestamp
- Wound-wait: Si TS(T_i) < TS(T_j) entonces T_j aborta y es recomenzada más tarde con el mismo timetamp. De lo contrario, T_i espera.
Estas soluciones pueden producir re-inicios y abortos innecesarios.
Otras técnicas de deadlocks son:
Detección
Mantener un grafo de espera y si hay un ciclo, seleccionar una victima para que aborte. Utilizado para transacciones pequeñas. Si estas fuesen largas o trabajan sobre muchos items se genera mucho overhead y la prevencion es mejor
Timeout
Si una transacción espera mucho tiempo, el sistema la aborta sin importar si hay un deadlock o no.
Problemas de locks: Starvation
Una transacción no puede ejecutar ninguna operación por un período indefinido de tiempo. Esto puede suceder, por ejemplo, si siempre se elige a la misma victima en la detección de deadlocks. es decir, un mecanismo de selección de victima equivocado. Las soluciones que se hacen son con estructuras similares a las utilizadas en SO:
- FIFO
- Manejo de prioridades
Las estrategias con timestamp wait&dia y wound&wait no tienen este problema.
Control de concurrencia basado en ordenación de timestamps
Cada transacción tiene 1 timestamp. Cada item X tiene 2 timestamps, Read_TS(X) y Write_TS(X) que tienen el timestamp de la transacción más joven que leyó/grabó el ítem. La idea consiste en ejecutar las R/W de acuerdo al orden de los timestamps, si se viola el orden se aborta la transacción.
- Si T trata de hacer w(X): Si Read_TS(X) > TS(T) o Write_TS(X) > TS(T), T aborta y luego se reinicia con un nuevo timestamp. Else, se actualiza el WriteTS(X) por TS(T)
- Si T trata de hacer r(X): Si Write_TS(X) > TS(T) se aborta y luego se reinicia T con un nuevo timestamp. Else, se ejecuta R(X) y se calcula Read_TS(X) como el maximo entre TS(T) y Read_TS(X) previo.
Control de concurrencia multiversion
Los algoritmos anteriores muchas veces demoran las lecturas innecesariamente por locking o abortos en cascada. Una solución es mantener varias versiones de cada item y para cada transacción elegir la correcta. Esto acelera las lecturas pero tiene como desventaja que se precisa almacenamiento adicional para las versiones de cada item. La idea básica es que antes de cualquier modificación a un item X, se guarda una varsion X_i del mismo, generando para cada X una sucesión de versiones \((X_1,\dots,X_k)\) . Cada versión está formada por un valor de X, el Read_TS(X) y el write_TS(X) para ese valor en concreto.
Hay dos reglas para asegurar la seriabilidad:
Sea X_i la version de X con máximo Write_TS:
- w(X): Si T tal que \(Write_TS(X_i) \leq TS(T) \le Read_TS(X_i)\), T aborta. En cualquier otro caso se crea \(X_j\) con \(Read_TS(X_j)=Write_TS(X_j)=TS(T)\)
- r(X): Se busca X_i tal que \(Write_TS(X_i)\) es el mas grande menor o igual que TS(T), se devuelve el valor de \(X_i\) a T y se asigna \(Read_TS(X_i)\) el maximo de \(TS(T)\) y \(Read_TS(X_i)\)
Granularidad
Que es un ítem? Este puede ser una tupla, un valor de una tupla, una tabla entera o incluso al base de datos completa! Cuanto mayor es el grado de granularidad, menor es el nivel de concurrencia permitido. Sin embargo, cuanto menor el grado de granularidad, mayor va a ser ekl overhead que e le impone a l sistema. Si las transacciones acceden a pocos registros es mejor una baja granularidad, si las transacciones acceden a tables enteras, es mejor una granularidad alta.
Inserción y Eliminación.
Locking.
Al eliminar se hace un lock en forma exclusiva. En timestamp hay que garantizar que ninguna transacción posterior a la que elimina el registro haya leído o escrito el elemento.
Inserción
Al hacer una inserción se crea un lock, se inserta un registro y se libera en el momento adecuado según el protocolo. Para timestamp se asigna el TS(X) como WriteTS(X) y ReadTS(X)
Ghost Locking
Un problema que puede pasar con esto de los lockeos es que una transacción T' accede a registros que cumplen una condición X que fue insertada por una tarnsacción T. Si T' lockea estos registros antes de que se inserte X, X se convierte uen un registro fantasma ya que T' no conoce a X a pesar de necesitarlo. La solución a esto es implementar un lock sobre indíces.
Recuperación de Información
En un sistema, se pueden dar fallas que pongan en riesgo la integridad y la existencia misma de la base y por lo tanto de los datos. El DBMS tiene la responsabilidad de poder recuperar la base d3e datos a un estado consistente y conocido.
Log
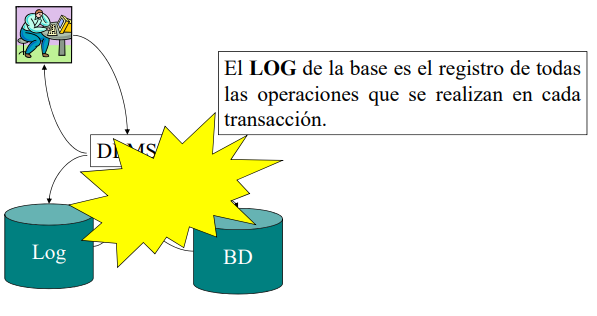
Es un registro de la actividad sobre la DB. Típicamente sus entradas cuentan con:
[start_transaction_T]
[write_item,T,X,v_old,v_new]
[read_item,T,X]
[commit,T]
[abort,T]
Cada vez que una transacción va a realizar una operación sobre la base, se agrega un registro en el log. Tipicmante esta actualizancon la hace en un buffer en memoria. Por lo que cuando una transacción T confirma, se baja todo el log de T que no esté guardado, se actualiza la DB con los efectos de la transacción. Si se pierde la base y el log a la vez marchamos. Por lo que deberían encontrarse en espacios (computadores e incluso discos) distintos. (Y respaldos!)
Algoritmos de recuperación
Si hubo un desastre (perdida de disco) entonces se debe recuperar el ultimo respaldo de la base, recuperar el LOG hasta donde se pueda. Y se debe haber el redo de todas las operaciones indicadas en el log desde el momento en que se hizo el respaldo a la base.
Si la falla fue menor (corte de energía), puede ser que haya que deshacer (undo) cambios ya realizados o rehacer cambios que no se hayan confirmado.
Actualización diferida e inmediata
Si la falla no fue catastrofica hay dos técnicas básicas de recuperación:
- Actualización diferida: Cada transacción trabaja en un area local de disco o memoria y recién se baja al disco después que la transacción alcanza el commit. (Si hay una falla o abort, no es necesario hacer redos o undo)
- Actualización inmediata: La base es actualizada antes de que la transacción alcance el commit, si hay un abort o falla deben hacerse los redos necesarios.
Siempre se graba primero el log para garantizar la recuperación.
BeFore IMage y AFter IMage
Para que el mecanismo de recuperación sea viable, es necesario considerar dos valores para cada item. Se tienen al menos dos valores:
- Before Image (BFIM): El valor del item antes de ser actualizado por la transacción
- After Image (AFIM): EL valor del item después de ser actualizado por una transacción
De esta forma, los registros del Log pueden estar clasificados en:
- Tipo Undo: Contienen la operación y el BFIM
- Tipo Redo: Contienen la operación y el AFIM
- Combinados: Contienen la operación y los dos valores. Permiten estrategias UNDO/REDO
Write Ahead Logging (WAL)
Es una estrategia en la cual esl mecanismo de rtecuperazion garantiza que el BFIM está en el Log y el Log está en disco ANTES que el AFIM actualiza el BFIm en la base del disco.
Un protocolo WAL podría ser:
- Un AFIM de X no puede actualizar el BFIM de X hasta que todos los registros del Log de tipo Undo para esta transacción hayan sido escritos en disco. Nunca se puede completar el commit de una transacción haya que todos lso registros de Log hayan sido escruitos ene el disco. Para esto se lleva un lista de transacciones activas, confirmadas y abortadas.
Checkpoint
Registro del log que indica que todos los buffers modifcados de la base fueron actualizados al disco. Ninguna transacción T tal que [commit,T] aparece en el Log antes que [Checkpoint] necesita redo.\ Para esto se tiene que:
- Suspender la ejecución de todas las transacciones
- Grabar todos los buffers modificados en el disco.
- Registrar el checkpoint en el log yt grabar el log en el disco.
- Permitir la continuación de las transacciones
Rollback
Se debe realizar cunado una transaccion aborta o hay una falla inesperada.
Es la recuperación de todos los BFIM 's de los items que modificó esa transaccion y de todas las transacciones que leyeron de la que abortó (abortos en casacada). Los abortos (rollbacks) en casacada pueden consumir mucho tiempo por l oque deben evitarse garantizando historias EAC o estrictas.
Algoritmos
Cualquier algoritmo de recuperación debería implementar las siguientes operaciones:
- Recuperación: Indica cual es al estrategia general de recuperación
- Undo: Indica como se debe hacer el undo de una operación
- Redo: Indica como se debe hacer el redo de una opearción
Es fundamental que el redo sea idempotent. Por lo genearl se asume que las historias generadas son estrictas y serializable.
Actualización diferida
Demorar la escritura de la base en el disco hasta que la transacción alcance el commit. Para esto, la actualización se realiza en el Log y en los buffers o en una area local de la transacción. Las dos reglas básicas del protocolo son:
- Los cambios realizados por la transacción T nunca son grabados en el disco hasta que la T alcanza el commit.
- Una transacción T nunca puede alcanzar el commit hasta que grabó todas sus operaciones de actualización en el Log y este fue grabado a disco.
Actualización inmediata
Grabar en disco sin esperar el commit usando kas estrategia WAL (grabar log antes). Existen dos tipos
- Undo/No-Redo: Hay que garantizar que todas las modificaciones efectivamente fueron grabadas a la base.
- Undo/Redo: (Mas complex), no hay que garantizar nada.
Se asume que las historias son estrictas y serializables.
Recuperación basada en Shadow Paging
Idea básica: La base de datos es un conjunto de paginas con un directorio con una entrada para cada pagina. Cada transacción que modifica algo mantiene dos copias: una que no modifica nunca y otra que modifica cada vez que modifica una pagina, creando una nueva.
Las ventajas de esta técnica: La recuperación se limita a elegir con que version de directorio se actualiza la base, en rollback se actualiza con el shawdow,, en commit se actualiza con el actual. Si se trabaja en un ambiente monotarea, no se precisa Log. La desventaja es que las paginas cambian de lugar, por lo que las estrategias de manipulacion en el disco son mas complejas, se debe implementar garbage collecting y que hay implementar de forma atomica la actualización del directorio.