Notas libro GPU
Existe una diferencia clave entre run on host (CPU y RAM) y run on device (GPU y su memoria). Una función que ejecuta en un device se le llama kernel.
Versión vainilla de hello world en una GPU:
#include <iostream>
__global__ void kernel(void){ }
int main(void) {
kernel<<< 1,1 >>>();
printf("Hello world \n");
return 0;
}
El qualifier __global sirve para indicarle al compilador que esa función debe correr en un device y no en el host.
El compilador para compilar en cuda es nvcc.
One of the benefits of CUDA C is that it provides this language integration so that device function calls look very much like host function calls.
Es necesario alocar memoria para realizar trabajo en el device. Incluso para retornar un valor al host. Para alocar memoria se usa la función cudaMalloc() que es similar al clásico malloc() de C. El primer parámetro es un puntero que apunto al puntero al cual se quiere guardar la dirección de la memoria alocada. El segundo es el tamaño de la memoria a alocar.
Es importante aclarar que el puntero de cudaMalloc no debe usarse para leer/escribir desde el host, pero si se pude pasar como argumento, aplicar aritmética de punteros, etc.
Para liberar memoria alocada con cudaMalloc, debemos usar cudaFree();. Este se comporta exactamente igual al querido free().
Para acceder a la memoria (más bien pasar de un lado para el otro dato) de un device desde el host o viceversa utilizamos cudaMemcpy(). Esta se comporta igual a memcpy a menos de que se incluye un parámetro para indicar cuál de los dos punteros refiere a un puntero del device. Estos parámetros son cudaMemcpyDeviceToHost y cudaMemcpyHostToDevice. El primer puntero es el destino, el segundo la source.
cudaGetDeviceCount() nos sirve para obtener la cantidad de dispositivos cuda en la PC. Luego hacemos cudaGetDeviceProperties(&prop,id) para obtener un struct con las propiedades del dive. prop es del tipo cudaDeviceProp. Este incluye un name, memoria global, nros de registros, clock, cantidad de multiprocesadores, concurrent kernels, etc.
There is no guarantee that the CUDA runtime will choose the best or most appropriate GPU for your application.
Kernel launch
Un kernel serial se ejecuta como << 1,1 >>.
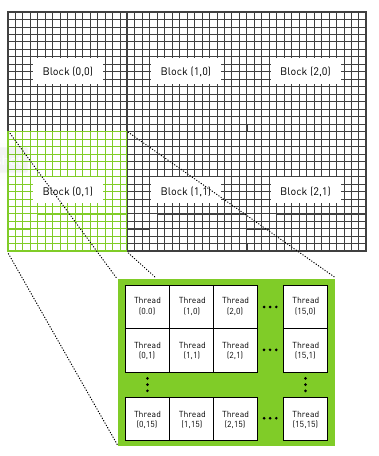
La primera entrada es la cantidad de bloques en paralelo que queremos que ejecuten dicho kernel. Cada invocación se le llama block. kernel << 256,1 >>() estaríamos corriendo 256 bloques en paralelo en la GPU.
Para poder modelar el comportamiento en cada bloque, existe una variable local a cada bloque: blockIdx.x. Esta tiene la id del bloque que está ejecutando el kernel. .x es porque podemos definir un grupo de bloques en varias dimensiones (la cantidad de dimensiones depende de la versión de CUDA, las más nuevas soportan 3). Esto es conveniente en problemas en varias dimensiones como matrices.
Know that using two-dimensional indexing can sometimes be more convenient than one-dimensional indexing. But you never have to use it. We won’t be offended.
Cuando hacemos << N,1 >> estamos pidiendo una colección de N bloques paralelos. A esta colección se le llama grid. Al escribir un escalar (1) el runtime entiende que estamos pidiendo una grid de 1 dimensión con N bloques. Cada uno de estos hilos va a tener valores variando entre 0 y N-1.
2d grid
Para encapsular tuplas de varias dimensiones, CUDA provee la estructura dim3:
dim3 grid(N,M)
kernel<<<grid,1>>>(ptr);
dim3 es una tupla en 3 dimensiones. si queremos usar solo dos dimensiones simplemente aclaramos que la tercera dimensión tiene valor 1. (Si se inicializa con 2 valores, la 3ra dimensión se inicializa con valor 1, como es en este caso.) Este struct se lo pasamos al operador <<< >>> para construir la grid multidimensional. En el kernel, para acceder a las dimensiones podemos hacer blockIdx.x, blocIdx.y y blockIdx.z
Por otra parte, la variable gridDim nos devuelve las dimensiones de la grid del kernel que fue lanzado. Podemos obtener las dimensiones con los atributos x,y,z.
when coders and APIs fight, the API always wins.
__ device __ qualifier
el calificador device permite indicar que una función se va a ejecutar desde el device yt no desde el host. Por ello, estas funciones solo van a ser invocables desde el device (por ejemplo, desde otra función o kernel).
Si definimos un struct, recordar incluir __ device __ en los constructores, sino no los vamos a poder utilizar en la tarjeta.
Threads
CUDA permite dividir cada bloque de ejecución en múltiples threads. El segundo argumento del operador <<< >>> permite especificar la cantidad de threads a ejecutar en cada bloque.
Para referirnos a un thread en el kernel basta con utilizar el struct threadIdx (con atributo x por ejemplo).
Hay muchos menos threads por bloque que la cantidad de bloques en una GPU. Este número máximo de threads por bloque está en la variable: maxThreadsPerBlock.
Podemos indexar de a bloques y threads con una sola id: int tid = threadIdx.x blockIdx.x blockDim.x.
Blockdim tiene la cantidad de threads en cada dimensión del bloque donde se está invocando. Es similar a gridDim, la cual indicaba la cantidad de bloques en cada dimensión de la grid.
CUDA runtime allows you to launch a 2D grid of blocks where each block is a 3D array of threads.
Un patrón de diseño es tener una cantidad fija de threads por bloque. Luego, lanzar la cantidad necesaria de bloques para cumplir con la paralelización. A su vez, en la función de kernel ponemos guardas para asegurarnos de que, si invocamos threads de más, estos no hagan nada.
Por otra parte, si la cantidad de threads necesaria es mayor a la cantidad de threads en todos los bloques de la grid. Tenemos que iterar en el kernel. Un patrón común para esto es hacer tid += blockDim.x * gridDim.x.
Un ejemplo de lanzamiento de kernel para una imagen dividida en bloques:
dim3 blocks(DIM/16,DIM/16);
dim3 threads(16,16);
kernel<<< blocks, threads >>>f();
Luego en el kernel:
int x = threadIdx.x + blockId.x * blockDim.x
int y = threadIdx.y + blockIdx.y * blockDim.y
int offset = x + y *blockDim.x * gridDim.x
Shared memory and Synchronization
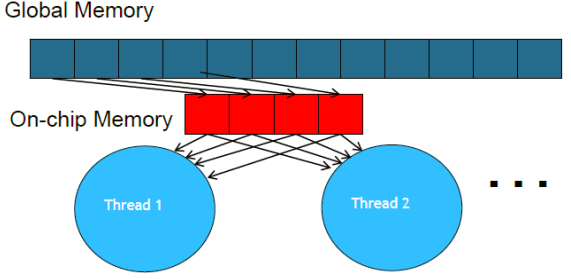
Existe un espacio de memory compartida en la tarjeta. Para ello se agrega el qualifier __ shared __ en las variables. Las variables shared se copian en cada uno de los bloques de la grid, por lo tanto, provee un mecanismo de cooperación entre threads. Esta memoria reside dentro de la GPU. La shared memory es útil como una memoria/cache compartida por bloque.
Para poder declarar de forma dinámica la memoria shared necesito agregar extern de forma previa.
Por ejemplo, para tener un array de tamaño la cantidad de threads: __ shared __ float cache[threadsPerBlock]
La memoria compartida se divide en módulos del mismo tamaño llamados bancos. En CC>3.X el direccionamiento de los bancos es de 32 bits. Los bancos se acceden simultáneamente a nivel de wrap. Por lo tanto, si las lecturas o escrituras se hacen sobre bancos distintos, estas se pueden hacer en simultaneo. Es decir, cada banco puede atender una sola solicitud por ciclo. Sí hay más de una solicitud se serializa. Cada banco es de 32 bits (4byte).
El acceso se ve potenciado cuando cada hilo accede a un banco distinto o a la misma palabra de un banco. Se pierde performance cuando se precisan palabras distintas de un mismo banco.
La shared memory al ser más rápida que la global también se utiliza como caché intermedio de la memoria global o cuando se van a hacer accesos no coalesced a memoria global. Se carga de a fragmentos parte de la memoria global a la shared. Esta actividad se le llama tiling (la memoria global se divide en tiles).
Esquema general de tiling:
- Identificar
La directiva __ syncthreads() la podemos ejecutar dentro del kernel para hacer que todos los threads de un bloque se sincronicen al llegar a esta instrucción. Es importante observar que esta directiva fuerza a todos los hilos a esperar que estén todos juntitos en esta instrucción, por lo que si algún thread no llega a la instrucción syncthreads (ya sea por una terminación temprana o estructuras condicionales), el programa falla.
Constant memory and events
With hundreds of arithmetic units on the GPU, often the bottleneck is not the arithmetic throughput of the chip but rather the memory bandwidth of the chip.
Existe una memoria muy eficiente llamada constant memory. Como indica su nombre, esta memorita no puede cambiar durante la ejecución del kernel. Usar esta memoria reduce el consumo de bandwidth de la tarjeta.
Para esto, se utiliza la directiva __ constant __ . Notar que las variables con esta directiva se tienen que alocar de manera estática (no malloc).
Para mandar algo desde el main a la memoria constante necesito la función cudaMemcpyToSymbol(). Es análoga a cudaMemcpy es que esta copia a la memoria constante.
Beneficios
¿Y cuál es la ventaja de la memoria constante? Existen dos puntos clave:
- Un thread que hace read a una memoria constante realiza un "broadcast" de la lectura a sus threads "cercanos"
- La memoria constante se cachea, reads consecutivos a la misma dirección no generan tráfico adicional.
¿Que significa “threads cercanos”? Los threds se encuentran agrupados en warps. Por lo general son 32 threads. Esta división está dada porque los threads se encuentran fisicamente en una misma estructura (fabric). Estos warps están entrelazados y se ejecutan en lockstep: En cada línea del programa, cada thread ejecuta la misma instrucción (literalmente) pero con diferentes datos.
El hardware de NVIDIA brodcastea la lectura a memoria constante en cada half-warp. Por lo tanto, si el halfwarp es de 16 threads, solo se va a hacer un 1/16 de las lecturas que se harían con memoria normal.
Por otra parte, el hardware cachea los datos constantes en la GPU, ¡otros half-warps que piden la misma address van a hacer un caché hit!
Sin embargo, existen drawbacks en el uso de memoria constante. Se puede perder performance significativamente (de usar memeoria normal) si los accesos a memoria constante de los threads en el half-warp son a diferentes direcciones. Esto se da en esencia porque los accesos se serializan, mientras que los a memoria global, si bien consumen bandwidth, se pueden hacer en paralelo.
Measuring performance
¿Como puedo verificar que los cambios que hago mejoran o empeoran al programa? Se podría hacer el profiling con el timer del sistema operativo. Pero este tiene latencia del SO, scheduling, etc. A su vez, si la computación también incluye trabajo del host es difícil determinar el trabajo de la tarjeta. Por ello, se va a utilizar CUDA event API para hacer el profiling.
Un evento en cuda es una GPU timestamp. Para iniciar un timer y detenerlo:
cudaEvent_t start,stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start,0);
//... work on GPU
cudaEventRecord(stop,0);
Las kernels calls de CUDA son asynchronous, es decir cuando hacemos la call, la GPU trabaja, pero la CPU continua ejecutando la siguiente línea de instrucciones.
Por ello, cuando ejecutamos una instrucción en realidad la estamos encolando en la lista de ejecución de la GPU, por ello no podemos leer el stop de una tras invocar la instrucción, ya que la GPU puede seguir estando trabajando. Para ello, existe una función de sincronización cudaEventSynchronize(stop) la cual permite esperar a que todo el trabajo antes del evento haya terminado.
Para medir la diferencia de tiempo, hacemos cudaEventElapsedTime(&float, start, stop);
Los eventos deben liberarse de memoria: cudaEventDestroy(start);
Texture memory
La texture memory se beneficia considerablemente de la caché, particularmente tiene beneficios cuando existe una cierta coherencia espacial en los datos. (Por ejemplo, hacer computaciones con los pixeles cercanos en una imagen 2D). En estos casos, utilizar memoria gráfica trae mejor performance. Esta memoria inicialmente fue concebida para el pipeline gráfico de la tarjeta.
Un ejemplo claro de coherencia espacial:
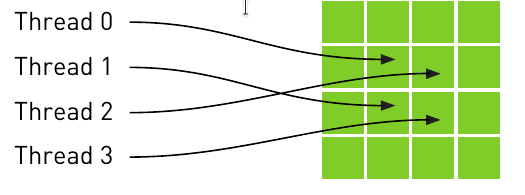
En la caché de CPU, las 4 direcciones no son consecutivas. ¡Pero en la texture memory si!
Definir variables en la textura de memoria se realiza a través de referencias genéricas: texture<float> texIn,texOut;
Luego de definir las variables, se debe bindear estas referencias a memoria con la llamada cudaBindTexture(NULL,texIn,data.dev)inSrc,SIZE).
Para leer una dirección en la texture memory tenemos que utilizar métodos de accesso especiales: tex1Dfetch(reference,index) (texture 1 dimensión fetch)
Las referencias a texturas deben declararse de forma global en el archivo. tex1Dfetch no es realmente una función, pero una ayuda del compilador. Por lo que reference no es un argumento sino un parámetro que se escribe de forma estática, es decir, el compilador sabe de antemano la referencia antes de compilar.
La memoria de textura también puede instanciarse en 2D: texture< float,2 > texIn;. En este caso hay que cambiar la forma de acceder a esta: tex2D(texIn,x,y); y las binding calls:
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>();
cudaBindTexure2D(NULL, texIn, data.dev_inSrc, desc, DIM, DIM, sizseof(float)*DIM);
Atomics
¿Como puedo hacer un read-modify-wirite atómico en GPU?
CUDA API nos provee la función atomicAdd(ptr,inc) la cual nos permite incrementar una variable de forma atómica. Notar que esto puede impactar negativamente en la performance y paralelismo. Ya que fuerza a encolar los accesos a una dirección de memoria por los distintos threads.
Coalesced memory
Coalesced memory access or memory coalescing refers to combining multiple memory accesses into a single transaction. On compute capability > 2.0, every successive 128 bytes (32 single precision words) memory can be accessed by a warp (32 consecutive threads) in a single transaction. However, the following conditions may result in uncoalesced load, i.e., memory access becomes serialized:
- Memory is not sequential.
- Memory access is sparse.
- Misaligned memory Access.
Una forma de aprovechar la coalesced memory cuando iteramos sobre structs es utilizar estructuras de datos struct of arrays en vez de la clasica array of structs. Esto es:
Array of structs: persona[1].casa; persona[1].nombre; persona[1].edad; Struct of arrays: personas.casa[1] personas.nombre[1]; personas.edad[1];
Transferencias a memoria
No paginable
Para pasar datos de la CPU a la GPU la memoria tiene que estar en NO-Paginable. CUDA avisa que la memoria esta en este estado para.
Appendix
Math indexing:
Un truco esencial para obtener el menor múltiplo de x que sea mayor o igual a N es realizar la cuenta: \((N+(x-1))/x\)
Ray Tracing
Ray Tracing es una técnica para producir una imagen 2D de una escena 3D. Es una técnica alternativa a la tradicional técnica que utilizan las GPU's: rasterización. La idea de ray tracing es simple: En cada pixel nos imaginamos que hay un ojo, el resultado del pixel es determinar la luz que producen los objetos al llegar al ojo.
En su implementación, es más simple pensarlo al revés: El ojo larga un rayo, la idea es determinar que objetos impactan en los rayos que tiene el ojo. La computación del ray tracing es la intersección de estos rayos con los objetos de la escena. Sin embargo, esto se complejiza: Los rayos se puden reflejar, transparentar, refractar, etc.
Volatile
La keyword volatile previa a una variable sirve para indicar que la misma puede cambiar en cualquier momento sin ninguna de las acciones que el compilador considera que están en el scope de la variable.
NVCC
Nvcc es el compilador CUDA. Una de las banderas de este es para especificar que la arquitectura a compilar es de una compute capability definida. Por ejemplo, para exigir compute capability mínima 1.2 se compila con la bandera: nvcc -arch=sm_12
Observar que no es lo mismo la versión CUDA que la compute capability de una GPU, las versiones de cuda soportan GPUs con distintas compute capabilities. CUDA es la API, está en ella soportar la Comp. Capabilities de las distintas GPUs.