Introducción a la Ingeniería del Software
Chapter I: Introduction
Según Somerville los proyectos de ingeniería de software fracasan por dos factores. Primero, el aumento de complejidad del sistema -como los sistemas deben construirse cada vez más rápido, grandes y complejos - los ingenieros tienen nuevos desafíos para construir software que antes se veía como imposible. Segundo, muchas veces se fracasa al no utilizar los métodos de la ingeniería de software. Es fácil no utilizar estos métodos, y como consecuencia a largo plazo el software se puede convertir en más costoso, menos confiable y más difícil de modificar.
Software profesional
La diferencia clave entre software profesional y amateur es que el primero está pensado para ser utilizado por consumidores aparte del desarrollador y un pequeño equipo de individuos con conocimiento sobre el desarrollo del software. Este tiene que ser mantenido y modificado a lo largo de su ciclo de vida. Software engineering tiene técnicas que se aplican a software profesional.
Many people think software is simply another word for computer programs. However, when we are talking about software engineering, software is not just the programs themselves but also all associated documentation, libraries, support web-sites, configurations and data that are needed to make these programs useful.
Los ingenieros de software construyen dos tipos de productos:
Productos genéricos: Stand-alone systems que se venden en el mercado de forma genérica. Ejemplo de estos son apps, programas para PCs, etc. También se incluye aplicaciones diseñadas para industrias y mercados específicos, por ejemplo, el programa Memory.
Customized software: Software que está encargado a medida. Ejemplos de estos son firmware y software para controlar un proceso de negocio especifico.
Una diferencia clave es que, en los productos genéricos, son los desarrolladores los que controlan la especificación. Mientras que en los customized la especificación es controlada por el cliente.
Sin embargo, el software customizable hace que esta línea se vuelva blurred. Por ejemplo, el software de planificación empresarial (Enterprise Resource Planning (ERP), como SAP y Oracle) se basan en un producto genérico base que luego se personaliza.
FAQ
What is software?: Programas de computadora y su documentación asociada. Estos productos se desarrollan para un cliente en particular o un mercado general.
What are the attributes of good software?: Un buen software debe tener la funcionalidad requerida y performance. A su vez, debe ser mantenible, confiable y utilizable.
What is software engineering?: La ingeniería de software es la disciplina que estudia todos los aspectos de la producción de software, desde su concepción a su evolución.
What are the fundamental software engineering activities?: Especificación, desarrollo, validación y evolución.
Difference between CS and Software Engineering?: CS se centra en la teoría, SE centra en las practicidades de desarrollar buen software.
Difference between SE and Systems Engineering?: Systems engineering se centra en todos los aspectos de la computadora (hardware, software, procesos, etc.), software engineering es parte de este proceso más amplio que estudia Systems Engineering.
Key challenges facing SE: Afrontar la diversidad, demandas y tiempos, mientras se desarrolla software confiable.
Costo de la ingeniería de software?: 60% costos de desarrollo, 40% de testing. Para software custom, los tiempos de evolución son mayores a los de desarrollo.
Las mejores prácticas de SE: Depende del sistema. Los videojuegos requieren prototipos mientras que el software de seguridad requiere múltiples sistemas de control y especificaciones.
Atributos esenciales de un buen producto
Acceptability: El software debe estar aceptable para el cliente. Es decir, debe ser comprensible, utilizable y compatible con los demás sistemas que usan.
Dependability and security: Software dependability incluye: reliability, security and safety. Un software dependable no puede causar perjurios en caso de que falle. Tampoco debe permitir que usuarios maliciosos accedan y dañen el sistema.
Eficiencia: El software no debe malgastar recursos como memoria o ciclos de CPU. Eficiencia incluye: responsiveness, tiempo de procesamiento, uso de recursos, etc.
Maintainability: El software debe desarrollarse de tal forma que pueda evolucionar y complacer las necesidades cambiantes de los clientes.
Software engineering
Software engineering is an engineering discipline that is concerned with all aspects of software production from the early stages of system specification to maintaining the system after it has gone into use.
Existen dos aspectos clave. Primero que esta es una disciplina ingenieril. Por lo que se aplican teorías, métodos y herramientas apropiadas según el juicio del ingeniero. Pero también se buscan soluciones y métodos nuevos cuando no se hallan teorías o métodos aplicables. La ingeniería debe trabajar con restricciones de costo y tiempo, y buscar soluciones dentro de estas restricciones. Segundo, la ingeniería de software se centra en todos los aspectos de la producción de software. Es decir, las herramientas, métodos y teorías para realizar un correcto desarrollo del software.
Existen cuatro actividades fundamentales en el proceso de software:
- Especificación: Donde se define el software a construir y las restricciones de su operación
- Desarrollo: Donde el software se diseña y se programa.
- Validación: Se chequea que el software cumple con lo que el cliente requiere.
- Evolución: El software se modifica para reflejar las nuevas necesidades del cliente.
Diferentes tipos de sistemas requieren distintos procesos de software. Por ejemplo, un software de portaaviones tiene una etapa de especificación bien definida con varios controles y protocolos. Mientras que un servicio de e-commerce, la especificación y el desarrollo suelen realizarse de manera simultánea.
En este sentido, existen 4 factores que varían en los distintos tipos de software:
- Heterogeneidad: Cada vez más, los sistemas operan de forma distribuida entre varios dispositivos. Muchas veces se debe integrar sistemas legado en diferentes lenguajes y hardware incompatible. El desafió es aplicar técnicas para construir software confiable que sea flexible para trabajar en ambientes heterogéneos.
- Cambios sociales y empresariales: Muchas técnicas de desarrollo de software consumen mucho tiempo, y terminar un programa lleva más de los esperado. La sociedad y sus necesidades cambian rápido, tiene que haber técnicas de software para acelerar este proceso.
- Seguridad y confianza: Muchas veces ponemos nuestras vidas sobre un programa. Tenemos que asegurarnos que nada pueda salir mal.
- Escala: El software puede ser desde un pequeño firmware para un sistema embebido a un software de gran porte distribuido en servidores por todo el mundo atendiendo a millones de personas.
Software engineering diversity
Uno de los factores que enriquece esta disciplina es la gran cantidad de diferentes clases de sistemas de software y sus diferentes comportamientos. Uno de los factores más importantes para determinar que técnica de software utilizar es saber con qué tipo de sistema estamos construyendo:
- Stand-Alone apps: Aplicaciones que corren en un dispositivo y tienen toda la funcionalidad allí. Por ejemplo: Notepad, cámara de fotos, etc.
- Interactive transaction-based apps: Aplicaciones que se ejecutan en una computadora remota con una terminal cliente. Ejemplo de estos son las aplicaciones web, servicios de e-commerce, servicios en la nube, etc.
- Sistemas de control embebido: Software que administra dispositivos. Software del microondas, control de frenos del auto, etc.
- Batch processing systems: Sistemas que se ejecutan periódicamente para realizar una actividad. Ejemplo: Sistemas de liquidación de salarios.
- Sistemas de entretenimiento: Gran importancia a la interacción del sistema con el usuario. Videojuegos, Netflix, You-tube, etc.
- Sistemas de modelado y simulación: Simular procesos físicos con múltiples agentes. Computacionalmente exigentes y requiere sistemas distribuidos/paralelos.
- Recolección de datos y sistemas de análisis: Sistemas que harvest your data o que tienen muchos sensores. Estos sistemas usan técnicas de Big Data para realizar análisis estadísticos de los datos que capturan.
- Sistemas de sistemas: Sistemas que controlan otros sistemas. Por ejemplo, los sistemas ERP empresariales.
Notar que un software puede gradualmente pertenecer a varias categorías. Cada sistema requiere técnicas de software especializadas por sus características. Por ejemplo, los sistemas embebidos que se cargan en ROMs, resulta costoso modificarlos. Por lo que existe un extenso proceso de verificación y validación antes de la puesta a producción. Sin embargo, los fundamentos de SE siempre se aplican: Utilizar un proceso de desarrollo bien definido, confianza y seguridad en el sistema (no hacer un software queso gruyere), administrar la especificación y requerimientos (conocer las necesidades de los clientes), uso eficiente de los recursos (no reinventar la rueda, reutilizar código).
Internet software engineering
El desarrollo de La Web, permitió a las empresas pasar de aplicaciones que se instalaban en el ordenador del cliente a código que se ejecuta de manera remota en in-house servers. Esto permitió el concepto de Software As A Service (SaaS). El cual nos lleva al current state of affairs donde Microsoft espera que sus clientes paguen mensualmente para utilizar su editor de texto. Algunas consecuencias del software engineering sobre esto:
- Reutilizar software es el dominant approach. Al construir estos sistemas, se parte de componentes y frameworks preexistentes.
- **Se acepta que no es eficiente definir todos los requerimientos del sistema de antemano. Los sistemas web se construyen de manera incremental.
- El software se implementa utilizando service-oriented software engineering donde los componentes de software son stand-alone web services.
- El desarrollo de HTML5 y AJAX permitió la construcción de interfaces de usuario de calidad dentro del navegador web.
Software engineering Ethics
It goes without saying that you should uphold normal standards of honesty and integrity. You should not use your skills and abilities to behave in a dishonest way or in a way that will bring disrepute to the software engineering profession.
Algunos aspectos éticos que van más allá de lo legal son: Confidencialidad (respetar al cliente/empleador), Competencia (ser honesto con mis capacidades), Derechos de propiedad intelectual (Proteger el software que construí), dar mal uso a las computadoras ajenas (minar bitcoin en la máquina del cliente)
Software Engineering Code of Ethics and Professional Practice (ACM-IEEE)
- PUBLIC — Software engineers shall act consistently with the public interest.
- CLIENT AND EMPLOYER — Software engineers shall act in a manner that is in the best interests of their client and employer consistent with the public interest.
- PRODUCT — Software engineers shall ensure that their products and related modifications meet the highest professional standards possible.
- JUDGMENT — Software engineers shall maintain integrity and independence in their professional judgment.
- MANAGEMENT — Software engineering managers and leaders shall subscribe to and promote an ethical approach to the management of software development and maintenance.
- PROFESSION — Software engineers shall advance the integrity and reputation of the profession consistent with the public interest.
- COLLEAGUES — Software engineers shall be fair to and supportive of their colleagues.
- SELF — Software engineers shall participate in lifelong learning regarding the practice of their profession and shall promote an ethical approach to the practice of the profession.
Chapter II: Software Process
A software process is a set of related activities that leads to the production of a software system.
Estas actividades son complejas. Cuando describimos el proceso de software también hablamos de las actividades de este proceso, los productos y resultados de cada actividad, los roles de las personas que integran el proceso. Y las pre y post condiciones de cada subprocess.
Software process models
Un modelo de proceso de software (aka Software development life cycle, SDLC) es una representación simplificada de un proceso de software. Cada modelo representa un proceso desde una perspectiva por lo que aporta información parcial del mismo. Por ejemplo, un process activity model muestra las actividades y su secuencia, pero no los roles de las personas involucradas en el proceso.
Los 3 modelos de proceso genéricos son:
Waterfall model: Toma las actividades de software fundamentales (especificación, desarrollo, validación y evolución) y las representa como procesos separados: especificación de requerimientos, diseño del software, implementación y testing
Desarrollo incremental: Entrelaza las actividades de especificación, desarrollo y validación. El sistema se desarrolla de a incrementos, donde cada uno de estos agrega funcionalidades al incremento anterior.
Integración y configuración: Se basa en la disponibilidad de componentes reutilizables. Se basa en configurar estos componentes y utilizarlos en un nuevo entorno e integrándolos en un sistema.
Ha habido intentos de crear un modelo universal de proceso de software. Un ejemplo de este es el Rational Unified Process (RUP), apoyado por IBM, aunque este nunca tuvo mucha popularidad.
Observar que en sistemas complejos y en la realidad de la empresa se combinan cosas de los 3 modelos. Por ejemplo, el core de un sistema puede aplicarse una estructura waterfall mientras que los demás módulos se desarrollan de manera incremental.
The waterfall model
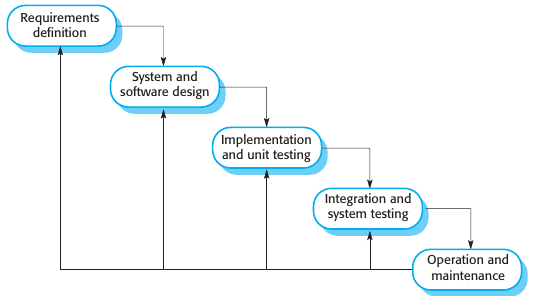
Derivado de los procesos de sistemas militares, representa el proceso de software como un numero de etapas secuenciales. Es un proceso plan-driven, ya que se planean todas las etapas del proceso antes de iniciar el desarrollo del software.
Las etapas de desarrollo son:
Requirements analysis and definition: Se establecen los servicios, restricciones y objetivos del sistema consultando a sus usuarios. Luego son definidos en detalle y funcionamiento como especificación
System and software design: Se analizan los requerimientos de software y hardware, se establece una arquitectura. El diseño de software identifica y describe las abstracciones de software fundamentales y cómo aplicarlas en el sistema.
Implementation and Unit Testing: El sistema se construye como un set de programas. Unit testing trata de verificar que cada unidad cumple con su especificación.
Integration and system testing: Cada unidad individual se integra y se testea en el sistema completo para asegurarse que se cumple con todos los requisitos. Luego de testear, se manda el sistema al cliente.
Operation and maintenance: Bugfixes, mejoras y agregar nuevos servicios a medida que se descubren nuevos requerimientos. Es la etapa más larga.
En un principio en vida etapa se desarrolla una serie de documentos que se van aprobando. No se pasa a la siguiente etapa hasta que una termina. Esto tiene sentido en una fábrica de galletas. Pero en el desarrollo de software existe una importante retroalimentación. Durante el diseño se descubren problemas en los requerimientos, al programar se ven problemas en el diseño, etc. Como resultado, el cliente y el equipo de desarrollo puede prematuramente congelar la especificación, dejado la resolución de los problemas para después, ignorados o resolverlos con alambre. Esto lleva a sistemas mal estructurados con una importante deuda técnica.
Este problema del modelo waterfall hace que este solo sea apropiado para ciertos sistemas:
Sistemas embebidos: donde el hardware inflexible hace que no sea posible realizar modificaciones en la especificación luego de que estas se implementan.
Sistemas críticos: donde se necesita múltiples controles de seguridad y análisis exhaustivo de la especificación y diseño. En estos sistemas la especificación y diseño debe estar completo para poder someterlo al análisis. Hacer modificaciones a futuro resulta más costos.
Grandes sistemas de software con equipos de desarrollo desconectados: Debe quedar bien definido todo para que los equipos de desarrollo no se pisen entre sí y todo pueda conectarse correctamente.
Por otra parte, este modelo no está cool cuando existe comunicación informal entre los equipos de cada proceso. Los modelos iterativos y ágiles son mejores en estos sistemas.
Una variante del waterfall es el formal system development, donde se construye un modelo matemático que sustenta al sistema y luego se define un programa de computadora en base a este. Estos procesos, como los basados en el modelo B, se utilizan en los sistemas más críticos. Para demostrar a las reguladoras que se siguen los estándares de seguridad. Tienen un alto coste.
Incremental development
Incremental development is based on the idea of developing an initial implementation, getting feedback from users and others, and evolving the software through several versions until the required system has been developed
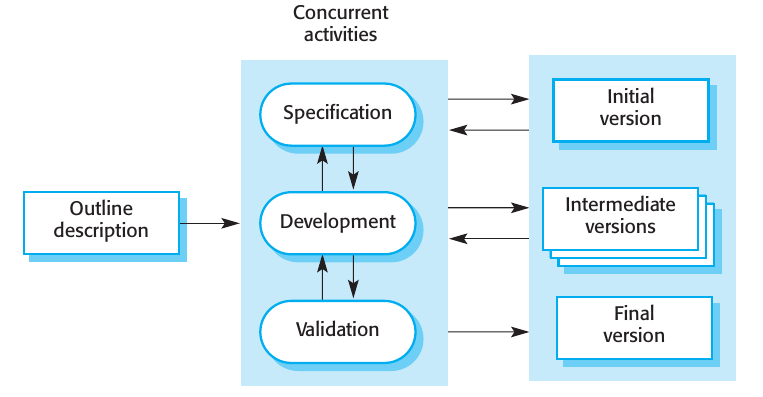
Este approach es el más común actualmente. Puede ser plan-driven, agile o una mezcla de estos. En plan-driven los incrementos se identifican de antemano, en el agile se miran los incrementos iniciales y los próximos se definen dependiendo de cómo va saliendo la cuestión.
El sistema incremental es mejor que el waterfall cuando los requerimientos podrían llegar a cambiar durante el proceso de desarrollo. Como nunca se trabaja en una solución completa es más fácil hacer cambios a medida que se desarrolla el software.
Otra ventaja es que el cliente puede ver el sistema en sus etapas tempranas y aportar feedback.
Las 3 ventajas centrales del modelo incremental son:
- El costo de implementar cambios es reducido. La cantidad de documentación a rehacer se reduce significativamente.
- Es más fácil obtener feedback. El cliente le es más difícil dar feedback de documentación.
- Es posible hacer beta delivery del software.
Desde un punto administrativo, los problemas del modelo incremental son:
El proceso no es 100% visible. Los gerentes necesitan ver el resultado de cada iteración con un "deliverable". Y si se quiere reducir los costos, no tiene sentido documentar cada iteración de forma exhaustiva.
La estructura del sistema se degrada en cada interacción. Es como tener un edificio que cada 1 mes le construimos una habitación nueva. ¿Es posible que este no se transforme en un monstruo si no le aplicamos técnicas de refractor?
Desde un punto administrativo, no es claro el costo que va a tener el software. En el modelo cascada está todo bien definido en este no. Esto puede generar problemas en modelos de compra tipo licitaciones.
The problems of incremental development become particularly acute for large, complex, long-lifetime systems
Integration and Configuration
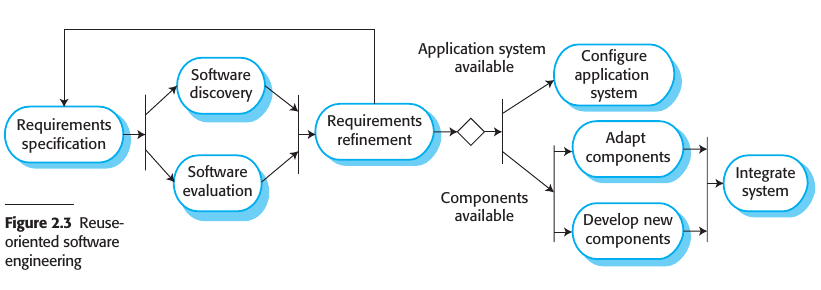
In the majority of software projects, there is some software reuse. This often happens informally when people working on the project know of or search for code that is similar to what is required. They look for these, modify them as needed, and integrate them with the new code that they have developed.
Esto no es nada nuevo, pero últimamente hay más foco en reutilizar software existente y modificarlo a la realidad y depender de un framework que permita reutilizar los distintos componentes.
Ejemplos de estos componentes son:
- Aplicaciones stand-alone, muchas features que deben ser adaptadas para cada caso específico.
- Colecciones de objetos dentro de un framework. Por ejemplo, Java Swing
- Web services estandarizados disponibles over the internet.
Las etapas de este proceso son las siguientes:
- Especificación de requerimientos: Se proponen los requerimientos iniciales.
- Software discovery and evaluation: Dado los requirements, se hace una búsqueda de los componentes y sistemas que proveen las funcionalidades que se piden. Se evalúan los componentes candidatos.
- Refinamiento de requerimientos: Se refinan los componentes utilizando la información de los componentes reutilizables que se descubrieron. Se modifican los requerimientos para reflejar los componentes disponibles. Si no es posible hacer modificaciones, se debe buscar alternativas en la actividad de component analysis.
- Application system configuration: Se hay disponible una app que cumple los requerimientos, se configura para utilizarla en el nuevo sistema
- Component adaptation and integration: Si no hay un off-the-shelf system, se modifican los componentes y se desarrollan nuevos. Luego se integra todo en el sistema.
La ventaja obvia de este proceso es reducir la cantidad de software a desarrollar, reduce costos y riesgos. Sin embargo, es casi imposible no hacer compromisos. Llevando a que los sistemas no hacen exactamente lo que los usuarios quieren.
El modelo de integración y configuración se puede aplicar tanto con un enfoque ágil como plan-driven.
Process Activities
Los cuatro procesos básicos (especificación, desarrollo, validación y evolución) se organizan distinto según el modelo de desarrollo de proceso. En waterfall, es secuencial, mientras que en el incremental están entrelazados. Estas actividades de desarrollan dependiendo de la experiencia de los desarrolladores, el producto per se y el tipo de organización que desarrolla el software.
Software Specification
Software specification or requirements engineering is the process of understanding and defining what services are required from the system and identifying the constraints on the system’s operation and development.
Esta es una parte critica del proceso, ya que errores en esta etapa inevitablemente trasladan los errores en las siguientes etapas de diseño e implementación. Antes de iniciar el proceso puede hacerse un estudio de mercado si el concepto general de producto tiene sentido.
El proceso de requisitos tiene como objetivo producir un conjunto de requerimientos aceptados que especifican el sistema y satisfacen los requerimientos del cliente. Estos se presentan en dos niveles de detalle, uno para los clientes en alto-nivel y otro para los desarrolladores en alto detalle.
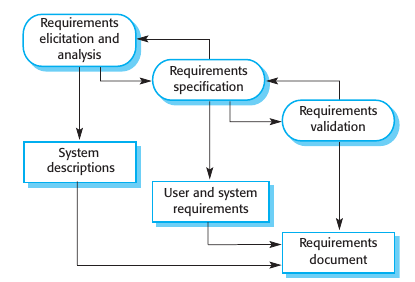
Las tres actividades de este proceso son:
Relevamiento de requisitos y análisis: Se relevan los requerimientos a través de sistemas existentes, discusiones con los clientes, análisis de tareas, etc. Puede involucrar el desarrollo de modelos del sistema y prototipos.
Especificación de requisitos: Es la actividad de transcribir la información obtenida de la etapa anterior y transformarla en un documento que define un conjunto de requerimientos. Existen dos tipos de requerimientos: User requirements que son requerimientos abstractos del sistema según el cliente y System Requirements que son una descripción más detallada de la funcionalidad a proveer.
Validación de requisitos: Chequear los requerimientos si son realistas, consistentes y completos. Aquí se descubren errores en los requerimientos, solicitando su modificación.
Requirements analysis continues during definition and specification, and new requirements come to light throughout the process. Therefore, the activities of analysis, definition, and specification are interleaved.
Software Design and Implementation
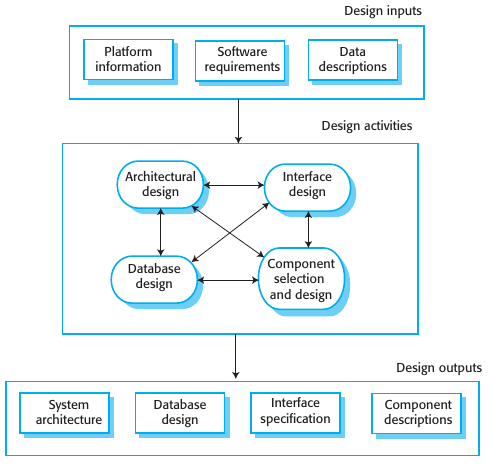
A software design is a description of the structure of the software to be implemented, the data models and structures used by the system, the interfaces between system components and, sometimes, the algorithms used.
La implementación consiste en obtener un programa ejecutable.
Las actividades del proceso varían según el sistema. Algunas de las actividades que pueden formar parte del proceso de diseño son:
Architectural design: Identificar la estructura del sistema , sus componentes principales, sus relaciones y como se distribuyen
Database design: Definir las estructuras de datos y como estas van a ser representadas
Interface design: Definición de las interfaces que conectan los componentes. Esta especificación no debe ser ambigua para el desarrollo independiente de los componentes.
Selección de componentes y diseño: Búsqueda de componentes reutilizables y diseño de nuevos componentes. El modelo de diseño puede utilizarse para automáticamente generar una implementación.
Estas actividades generan "design outputs" (ver imagen).
Luego todo esto se programa. Esta es una actividad individual y no existen lineamientos específicos.
Software Validation
Software validation, o de forma más general: Verification and Validation (V&V) tiene como objetivo mostrar que un sistema sigue su especificación y alcanza las expectativas del cliente. El testing, donde el programa se testea con datos simulados es la principal forma de validación. Otras técnicas son las inspecciones y reviews en cada etapa de desarrollo.
Existen tres etapas en el proceso de testing:
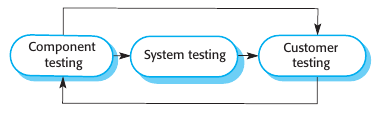
Component testing: Se testea cada componente individualmente. Aquí es donde están los test automation tools como JUnit.
System testing: Se integran todos los componentes y se prueba el sistema en su integridad. Pueden aparecer errores de interacciones no previstas entre distintos componentes y sus interfaces. También es necesario para mostrar que el sistema cumple con sus requerimientos funcionales y no funcionales.
Se testea con clientes reales, aka beta testers. Aquí se pueden revelar errores u omisiones en la definición de requerimientos. Ya que los datos reales sacan a luz cosas que los datos simulados no. También muestra si el sistema cumple realmente con los requerimientos de los usuarios o no.
Programmers make up their own test data and incrementally test the code as it is developed. The programmer knows the component and is therefore the best person to generate test cases.
En un approach incremental, en cada incremento se debe realizar el testing. En test-driven development se realizan los tests junto a los requerimientos antes del proceso de desarrollo. En un plan-driven software process (i.e critical systems), el testeo se maneja con sets de planes de testeo. Equipos independientes de testers ponen en práctica estos planes.
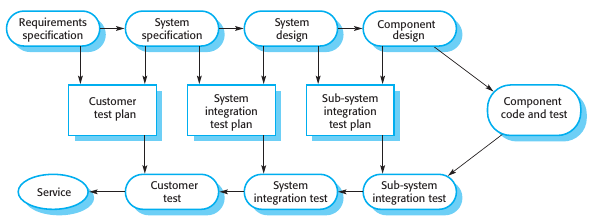
La siguiente imagen muestra la relación entre el testing y el desarrollo en las distintas actividades. Este se le llama el modelo V. Muestra las actividades de validación en el waterfall process model.
Software Evolution
Hoy en día, la diferencia entre desarrollo del software y su mantenimiento esta más blurry. Ahora con las metodologías incrementares el software está en un constante estado de evolución, que varía con las necesidades del cliente con el tiempo. Ya no hay una clara línea divisoria entre el desarrollo hasta obtener un working system y el mantenimiento de este.
Coping with Change
El cambio es inevitable. Las necesidades de los negocios cambian y esto implica un cambio en su software. El cambio agrega costos, ya que es trabajo adicional. El costo del retrabajo puede ser mayor o menor en medida de cómo está diseñado el sistema.
Existen dos approaches para reducir el costo del retrabajo:
Anticipación al cambio: El proceso de software tiene actividades que pueden anticipar o predecir posibles cambios antes de tener que rehacer trabajo de forma significativa. Ejemplo de esto es el prototipo de key features para enseñar a los clientes. Estos pueden experimentar con el prototipo antes de confirmar un requerimiento
Tolerancia al cambio: Diseñar el proceso y el software de tal forma que se pueden hacer fácilmente cambios al sistema.
La noción de refactoring (mejorar la estructura y organización de un programa) es también un mecanismo importante que contribuye a la tolerancia al cambio.
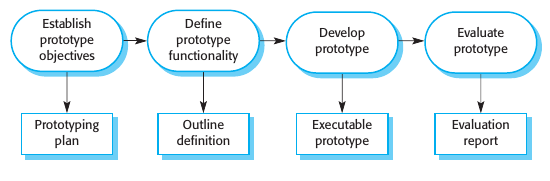
Prototyping
A prototype is an early version of a software system that is used to demonstrate concepts, try out design options, and find out more about the problem and its possible solutions.
Un prototipo puede ayudar a dilucidar la validación en el proceso de requerimientos del sistema. En la etapa de diseño un prototipo puede servir para explorar soluciones de software y en el desarrollo de una interfaz de usuario para el sistema.
Un prototipo permite a los usuarios ver que tan bien el sistema cumple su trabajo, obtener nuevos requerimientos y encontrar fortalezas y debilidades en el software. Se puede utilizar para ver si un diseño de software es feasible. Si un diseño de base de datos cumple sus requerimientos.
Es importante que al inicio del proceso los objetivos del prototipo estén claros, si se muestra un prototipo sin explicación previa puede generar confusión en sus usuarios. Luego de definir los objetivos, se debe definir que funcionalidades deben integrar el prototipo (y cuales no). Esto es importante para reducir costos. Luego de desarrollar el prototipo este debe evaluarse. ¿Qué cosas aportó el prototipo?
Incremental Delivery
Incremental delivery is an approach to software development where some of the developed increments are delivered to the customer and deployed for use in their working environment.
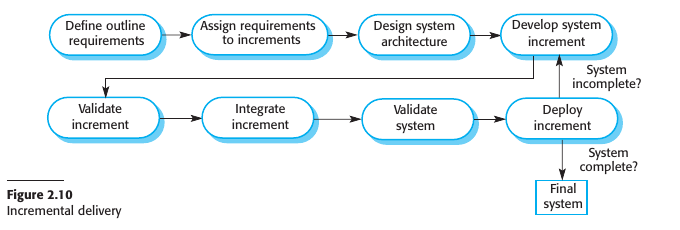
En este modelo el cliente define las funcionalidades más importantes en orden. Luego un numero de entregas del software se definen donde cada uno agrega nuevas funcionalidades. Es como que se van agregando nuevas versiones que se les da al cliente. Cuando un nuevo incremento se envía, el cliente lo puede probar y aportar su feedback para los siguientes incrementos.
Las ventajas de esto son:
- Los clientes pueden utilizar los primeros incrementos como prototipos del sistema para los próximos requerimientos del sistema
- Los clientes no deben esperar a que el sistema entero esté pronto para comenzar a utilizarlo
- El proceso mantiene los beneficios de que es relativamente fácil incorporar nuevos cambios al sistema
- Como las funcionalidades críticas se implementan primero, las funcionalidades más importantes son las que reciben indirectamente más testeo.
Las desventajas:
Incremental delivery es problemático para sistemas que remplazan a otros. Ya que es incómodo para el usuario utilizar un sistema incompleto cuando este espera que el nuevo programa haga exactamente lo mismo o mejor.
La mayoría de los sistemas tienen un core básico que debe estar presente. Como los requerimientos no se definen en detalle hasta que se implementa un incremento, es difícil identificar dicho core de componentes.
La esencia de los procesos iterativos es que la especificación se desarrolla en simultaneidad con el software. Esto está en conflicto con modelos de compra de varias organizaciones (Licitaciones gubernamentales, por ejemplo).
Process Improvement
Process improvement means understanding existing processes and changing these processes to increase product quality and/or reduce costs and development time
Existen dos approaches a la mejora de procesos:
The process maturity approach: Se centra en mejorar los procesos de administración e introducir buenas prácticas de software engineering. Se busca la mejora de la calidad del producto y la predictibilidad del proceso.
The agile approach, se basa en el delivery rápido de funcionalidades y la responsividad a cambios del cliente. La filosofía de mejora es que los mejores procesos son aquellos con menor overhead, y los ágiles son los que logran esto.
El process maturity tiene bastante overhead ya que introduce actividades que no sea alienan directamente con el desarrollo del programa. Agile approaches se centran en el código desarrollado y minimizan la formalidad y documentación.
El proceso de mejora de procesos tiene 3 fases: Measure, Analysis and Change. Primero se debe medir atributos del proceso de software, luego estos se analizan y se proponen realizar ciertos cambios.
Esta es una actividad a largo plazo y muchas veces resulta difícil a las empresas obtener datos para poder medir el proceso de desarrollo.
En cuento al process maturity, se observan 5 niveles:
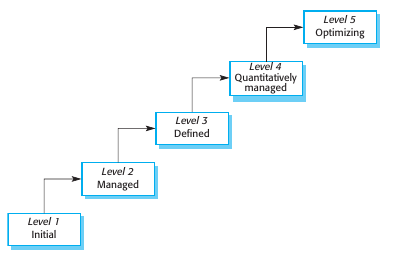
Initial: Esta definido el proceso y lo que se debe hacer con todos los miembros del equipo.
Managed: Existen políticas organizacionales para definir qué proceso de software debe usarse. Debe haber planes y documentación de los objetivos del proyecto. Deben haber resource managers y process monitoring procedures.
Defined: Organizational standardization and deployment of processes. Cada proyecto tiene un proceso administrado y adaptado a sus requerimientos a partir de un conjunto de procesos organizacionales.
Quantitatively managed: Existe una responsabilidad organizacional de utilizar métodos estadísticos para el control de subprocesses.
Optimización: Nivel más alto. La organización utiliza las mediciones de los procesos para mejorar los procesos. Se analizan tendencias se adaptan los procesos a las necesidades del negocio.
Chapter III: Agile Software Development
Key Points
Agile methods are iterative development methods that focus on reducing process overheads and documentation and on incremental software delivery. They involve customer representatives directly in the development process.
The decision on whether to use an agile or a plan-driven approach to development should depend on the type of software being developed, the capabilities of the development team, and the culture of the company developing the system. In practice, a mix of agile and plan-based techniques may be used.
Agile development practices include requirements expressed as user stories, pair programming, refactoring, continuous integration, and test-first development.
Scrum is an agile method that provides a framework for organizing agile projects. It is centered around a set of sprints, which are fixed time periods when a system increment is developed. Planning is based on prioritizing a backlog of work and selecting the highest priority tasks for a sprint.
To scale agile methods, some plan-based practices have to be integrated with agile practice. These include up-front requirements, multiple customer representatives, more documentation, common tooling across project teams, and the alignment of releases across teams.
Los métodos ágiles surgen de un cambio global en la industria del software. A medida que se requieren proyectos con respuesta rápida y que sus requerimientos pueden cambiar frecuentemente, las técnicas de plan driven software fallan. El desarrollo de técnicas para el desarrollo de software rápido se comenzó a conocer cómo agile methods. Estos comparten características:
El proceso de especificación, diseño e implementación están entrelazados. No hay una especificación definida, y la documentación es mínima. Los requerimientos del usuario es un punteo de las características más importantes del sistema.
El sistema se desarrolla de a incrementos. Cada incremento es evaluado por el usuario final y proporcionando feedback.
Fuerte uso de herramientas para apoyar el proceso de desarrollo. (Configuration management, system integration, automation,etc.)
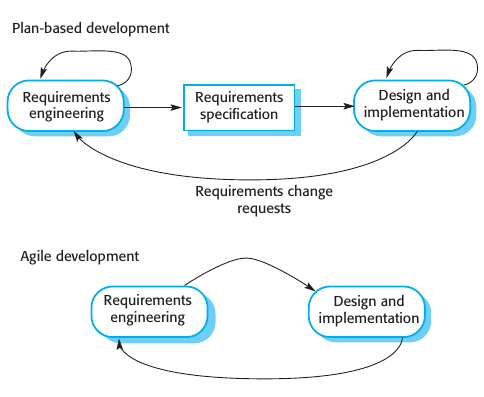
El overhead del plan driven software se justifica en sistemas críticos, donde se deben coordinar múltiples equipos, y cuando muchas personas van a estar encargadas de mantener el software a lo largo de su ciclo de vida. Pero cuando el mismo approach se aplica en proyectos más pequeños, el overhead se vuelve tan grande que domina el proceso de desarrollo.
More time is spent on how the system should be developed than on program development and testing.
Principios

We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.
Los sistemas ágiles son exitosos en:
Desarrollos de software donde el proyecto es un producto a vender al cliente de mediano-chico porte. La mayoría de los productos y apps utilizan agile approach.
Custom system development de una organización, donde hay un claro interés del cliente en estar metido en el proceso de desarrollo y existen pocas regulaciones que afecten el proceso de software.
La idea es que el equipo de desarrollo y el cliente ahora son amigos y trabajan juntos. Desaparece esa necesidad de mediación, contratos y clara definición del trabajo a realizar en un marco de tiempo definido.
Métodos Ágiles
Extreme Programming (XP)
El primer método ágil que surge es el llamado Extreme Programming (XP), este viene de llevar al extremo las mejores prácticas de desarrollo (cómo el desarrollo iterativo). En XP, los requerimientos son escenarios que se cuentan como historias. Estas historias son un caso de uso que el cliente puede relatar con simpleza y tiene un funcionamiento claro. En XP, los programadores trabajan de a pares y se sigue una metodología test-driven. Esto es, primero se definen los test y luego se programa el software. Solo se completa el incremento cuando el software construido pasa todos los tests. Cada incremento es pequeño. Es el cliente el quien evalúa y da feedback de la calidad de los tests.
Los principios de Extreme Programming son:
- Collective Ownership: Debido al pair programming, el código es soulless. Anyone can change anything. No islands of expertise.
- Continuous integration: las tareas finalizadas se integran al sistema, tras previamente pasar los tests
- Incremental planning: Los requerimientos son "story cards".
- On-Site Customer: Existe un representante del cliente en el proyecto trabajando con los desarrolladores. Es el responsable de traer los systems requirements.
- Pair programming: El chequeo del trabajo del otro aumenta la calidad del código.
- Refactoring: Se espera que los desarrolladores hagan refactoring del código continuamente. Keep the code simple and maintainable.
- Simple design: Simple design to meet the requirements and no more.
- Sustainable pace: No large amounts of overtime because it reduces code quality.
- Test First development.
Al final como que nadie implementó esto del todo xd. No se puede integrar con las practicas ya existentes y con la cultura organizacional. Al final, cada compañía toma las técnicas y prácticas de XP que les parece más conveniente y las aplica en su propio proceso de desarrollo. Por lo general estas prácticas se usan en conjunto con un método orientado a la administración como Scrum.
La idea de las stories está muy buena. Ya que muchas veces ilustra mejor cual es el comportamiento del sistema que las tecnicidades y descripciones abstractas. Los usuarios experimentados de un sistema por lo general están tan acostumbrados a su uso que se olvidan de cosas al describirlo. El único problema del método de las stories es que es difícil asegurar la completitud de una función o comportamiento esperado a través de un único ejemplo.
Anticipating for change is often wasted effort.
Esta forma de ver el mundo hace que se haga el mínimo refactoring y generalizaciones. Como consecuencia de esto es que la calidad del sistema se degrada con el tiempo si no se hace un refactoring general de vez en cuando. Es difícil encontrar el momento de hacer el refactoring ya que este no está bien definido en el proceso.
El test driven esta bueno ya que te hace ponerte a pensar sobre el comportamiento del sistema y, por ejemplo, las carencias de una historia aparecen (problemas de especificación) antes de implementarla. Así reduciendo el tiempo perdido. El problema es que un programador le re embola esto de testear y muchas veces se hace trampa a si mismo haciendo test poco comprensivos o irrelevantes. A su vez, muchos tests no se pueden hacer de forma incremental. ¿Como puedo testear el “workflow”? A su vez, es difícil asegurar la completitud y correctitud de los tests. Para este trabajo del testing es esencial las herramientas de integración continua.
Pair programming hace que te quede el código soulless (nadie es responsable de nada), actúa como proceso de code review, fomenta el refactoring ya que todo el equipo se beneficia del ya que todos van a trabajar sobre el código, ahora o en el futuro. Es discutido actualmente la eficiencia de pair programming, es bastante positiva entre programadores no muy hábiles.
Agile Project Management
Los gerentes necesitan saber si un proyecto va bien o no. Plan-driven approaches surgieron para cumplir con esto. Se traza un plan y se sigue. La planificación informal y pobre documentación de los métodos ágiles reduce la visibilidad externa del proyecto. Para resolver esto se diseñó el método Scrum. El cual es un framework para organizar proyectos ágiles y darles visibilidad a los mismos. Como Scrum no es un método convencional de project management se inventó un nuevo vocabulario para sus conceptos:
- Development Team (developers): Un grupo autoorganizado de desarrolladores. Pequeño, max 7p. Responsables de hacer software.
- Potentially shippable product increment: El resultado (incremento) de un sprint. La idea es que el resultado sea algo que se pueda poner en producción, no siempre pasa.
- Product Backlog: La lista de "TODO" items que el equipo de Scrum debe considerar. Pueden ser definiciones, requerimientos, historias o descripciones que ilustran lo que se necesita.
- Product Owner: Representación del cliente. Identifica las features o requerimientos que se necesita, prioriza los que se deben realizar en el siguiente sprint. Hace review del Product Backlog para asegurarse que sigue sus business-needs.
- Scrum: Reunión diaria del equipo para revisar el progreso y lo que se hará en el dia. Idealmente corta y face-to-face
- ScrumMaster: Es el responsable de que se haga el proceso Scrum. Es la interfaz entre el equipo de Scrum y la compañía, reporta al gerente de los progresos.
- Sprint: Una iteración. Por lo general duran de 2 a 4 semanas.
- Velocity: Cuanto Product Backlog se puede completar en un sprint. Entender la velocidad de un Scrum Team permite trazar con mayor precisión los planes de trabajo.
Scrum is an agile method insofar as it follows the principles from the agile manifesto. However, it focuses on providing a framework for agile project organization, and it does not mandate the use of specific development practices such as pair programming and test-first development.
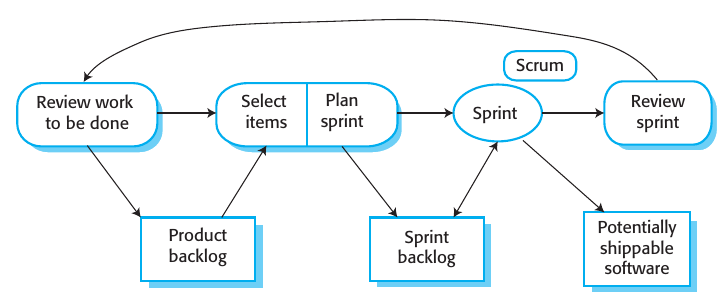
El inicio de un ciclo de Sprint es el input del product backlog. El product owner prioriza los elementos del backlog que deben trabajarse con mayor prioridad. Luego todo el equipo decide cuantas/cuales de esas prioridades pueden realizarse en este print. Para ello se tiene en cuenta la velocity. Esto crea el Sprint Backlog que es lo que se debe hacer en un sprint. El equipo se organiza para definir quien trabaja en que.
Durante el sprint se hacen reuniones diarias (Scrums) para revisar el progreso y prioridades. Se comparte información, los problemas que surgen y se buscan soluciones. De esta manera todos participan en el short-term planning y conocen el estado del proyecto.
Al final de cada sprint hay una review meeting con todo el equipo. Ahí se revisa como trabajo el equipo con el afán de mejorar el proceso y se actualiza el Product Backlog para el siguiente sprint.
Si bien el scrum master no tiene que ser el project manager suele serlo, y es quien le reporta a los de arriba en la organización del avance del proyecto.
Distributed SCRUM
Se deben tener algunas consideraciones adicionales en el caso de que los equipos se encuentren distribuidos en el mundo y se trabaje de manera remota:
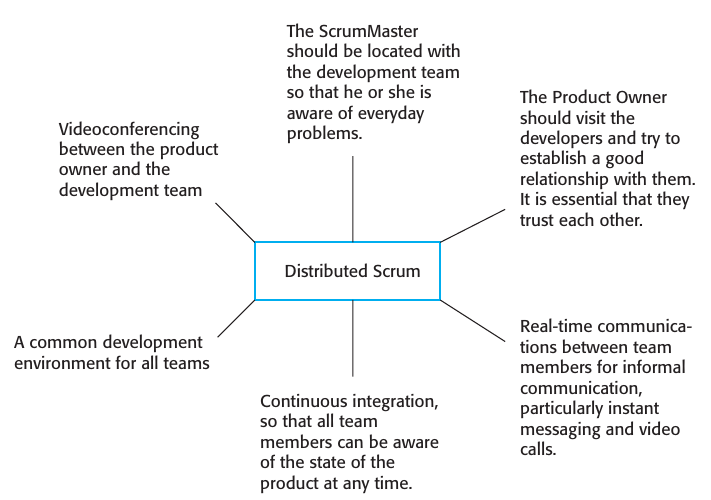
Las principales características de un multi-team scrum son:
- Role Replication: Cada equipo tiene un product owner y un scum master. Puede haber un product owner y scrum-master principal para todo el proyecto.
- Product architects: Cada equipo escoge a un arquitecto que se reúne con los arquitectos de los demás equipos para discutir la estructura global del sistema.
- Release alignment: Los resultados de los sprints están sincronizados para que el resultado sea un sistema funcional y completo.
- Scrum of Scrums: Hay un daily scrum meeting entre los representantes de cada equipo para discutir problemas globales y lineas generales de trabajo. En cada equipo a su vez hay scrums internos.
Scaling Agile Methods
Un problema de los métodos ágiles es que no escalan muy bien en las grandees organizaciones con muchos controles de calidad, burocracia , mecanismos rígidos y una fuerte cultura organizacional. Las ventajas de los métodos ágiles deben combinarse con un mínimo de plan-driven para poder tener éxito.
Algunos problemas son:
- The informality of agile development is incompatible with the legal approach to contract definition that is commonly used in large companies.
- Agile methods are most appropriate for new software development rather than for software maintenance. Yet the majority of software costs in large companies come from maintaining their existing software systems.
- Agile methods are designed for small co-located teams, yet much large software development now involves worldwide distributed teams.
Los problemas para mantener software con métodos ágiles son la falta de documentación, mantener al cliente involucrado, y la continuidad del equipo de desarrollo (fuga de recursos humanos).
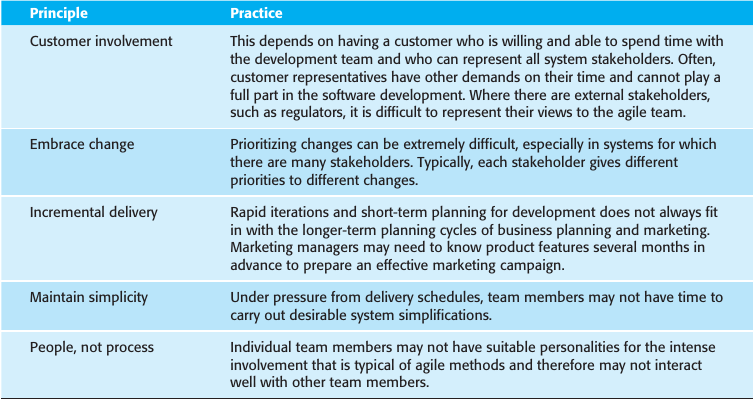
Los problemas del método ágil se ilustran en este cuadro:
Los factores que se ponen en consideración para elegir el nivel de plan-driven o agile development:
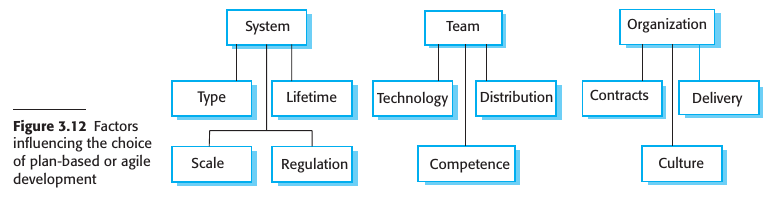
De la imagen anterior salen los key issues:
- Que tan grande es el sistema? Cuanto más grande el equipo menos eficiente es este método y se requiere de un plan driven approach.
- Tipo de sistema? Los sistemas que requieren mucho análisis, o son críticos requieren de documentación y diseño mas cuidadosos. Es mejor un plan driven approach.
- Duración del sistema? Un sistema que tiene que durar para toda la vida tiene que tener documentación. No importa si por momentos está desactualizada (mi opinión)
- Regulaciones externas? Los controles de calidad o testeo hace que la organización hace que el equipo se vea forzado a generar documentación para que se apruebe el software.
Como regla general, en las grandes organizaciones se requiere un mínimo de etapa de ingeniería de requisitos previa (especificación) antes de iniciar el proceso de implementación.
También se requiere un poco de organización previa y factores a considerar en el equipo:
- Que tan buenos son los programadores? Si son muy malos el Scrum no va a andar muy buen, en ese caso un Pair programming tipo co-tutela puede andar.
- Como se organiza el development team? Si es distribuido se va a necesitar documentos para poder comunicarse entre los distintos nodos.
- Que tecnologías tenemos para apoyarnos? Necesitamos una buena IDE (Supongo que se referirá a métodos de integración continua, automatización y workflow).
En grandes compañías, en la gestión se debe considerar:
- Contratos? Puedo verme forzado a tener que seguir procedimientos y generar documentación.
- Es realista esperar feedback del cliente? Va a estar el cliente presente en el proceso?
- Cultura organizacional? Si todos estamos cómodos trabajando así, por qué cambiar?
Software developers should be pragmatic and should choose those methods that are most effective for the type of system being developed, whether or not these are labeled agile or plan-driven.
En sistemas grandes y complejos los factores principales que complejizan el desarrollo son:
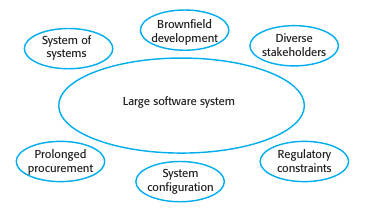
- Systems of systems: Colección de sistemas que trabajan entre sí, cada uno con su equipo de desarrollo independiente. Es imposible que alguien sepa todo, y cada uno termina preocupándose por lo suyo.
- Brownfield systems. Esto es, cada sistema interactúa entre ellos. Cambiar una cosa puede alterar el equilibrio de todo. ¿Como puedo proponer modificar algo de un sistema que no es el mío a pesar de que es claro que es lo mejor? Problemas de gestión.
- System configuration: Cuanto más complejo cada vez tiene más peso la configuración del sistema más que su desarrollo. Esto no es compatible con el desarrollo incremental.
- Mantener un equipo a lo largo del tiempo, los sistemas largos tienden a perdurar, sus desarrolladores no.
- Muchos stakeholders con diversos intereses. ¿A quien escuchar?
Existen métodos para escalar los métodos ágiles como el de IBM Agile Scaling Model.
Chapter IV: Requirements Engineering
Apuntes OpenFing
Los requisitos de un sistema son descripciones de lo que debería hacer el sistema - los servicios que provee y las restricciones de su operación.
El proceso de descubrir, analizar, documentar y chequear esos servicios y restricciones es llamado ingeniería de requisitos (Requirements engineering)
Un error en los requisitos sale más caro según la etapa en que estoy. Si en RE sale 1, en diseño sale 5, en implementación sale 10, en prueba unitaria 20 y en producción 200.
Un requisito puede ser desde un dibujo a una especificación matemática. Un requisito puede ser la base para la oferta de un contrato, por lo que debe ser escuchado. Y este puede ser la base para el mismo, por lo que debe detallarse bien.
Existen dos tipos de requisitos:"
- Requisitos de usuario: Declaraciones en lenguaje natural del sistema, sus servicios y sus limitaciones operativas. Lo escriben los clientes.
- Requisitos del sistema: Documento estructurado con descripciones detalladas de las funciones y restricciones del sistema. Define lo que se debe implementar, puede ser lo que va en el contrato.
Los stakeholders son todos los interesados en el sistema. Estos van más allá de los clientes y los usuarios, son también los diseñadores, verificadores, gerentes de negocio, etc. Por ejemplo:
- Pacientes cuya data se registra en el sistema
- Personal de TI que instala en las pc el sistema
- Gerentes de salud que obtienen la data del sistema
- El gobierno que financia la licitación del sistema
Tipos de información de requisitos:
Requisitos de dominio: Se derivan del dominio de la aplicación y no de las necesidades del usuario. Por ejemplo, si se quiere hacer un software constable este tiene que poder calcular el IVA.
Requisitos de negocio: Un objetivo de alto nivel de una organización que desarrolla el producto o de un cliente que lo compra: Por ejemplo, si trabajo en la facultad, todo software que haga debe ser open source.
Regla de negocio: Una política, guía o estándar que define algún aspecto del negocio: Por ejemplo, en el sistema del EVA, los usuarios son docentes XOR profesores.
Requisito de interfaz externa: Describe como debe ser una conexión entre distintos sistemas o usuarios. Por ejemplo, este POS se conecta al servicio VisaNET para confirmar la compra. Existen distintos niveles de detalle.
Característica (feature): Capacidades relacionadas de forma lógica que proveen valor al usuario y son descrita como un conjunto de requisitos funcionales. Ejemplo: Favoritos del navegador.
Requisito funcional: Una descripción de lo que el sistema debe hacer y bajo qué condiciones
Requisito no funcional: Descripción de una propiedad o característica que el sistema debe poseer o una restricción que debe respetar. Por ejemplo, una operación debe demorar menos de 5ms en completarse. No más de 10 clicks para completar un requerimiento funcional.
Atributo de calidad: Tipo de requisito no funcional que describe una característica del servicio. Poe ejemplo, full encrypted.
Requisitos funcionales y no funcionales
Requisitos funcionales
Los requisitos funcionales son declaraciones de los servicios que el sistema debería proveer, como el sistema debe reaccionar a ciertos inputs y cómo comportarse bajo ciertas condiciones. También puede indicar lo que NO debería pasar. Dependen del tipo de software, las expectativas de los usuarios y el enfoque en el cual se escriben los requisitos.
Estos requisitos pueden ir desde lo que debe hacer el software a como se hace el trabajo localmente en una organización. Si vamos a comprar SW los requisitos deben indicar la información que necesitan los stakeholders para modelar la casuistic de los procesos que queremos que se implementen.
La falta de precisión en los requisitos es la causa de muchos problemas en la industria. Los requisitos pueden ser ambiguos. Por ejemplo, "el usuario puede buscar en los listados de citas de todas las clínicas". Hay múltiples maneras de implementar esta búsqueda.
Se busca que los requisitos sean completos (todos los requisitos requeridos están definidos) y consistentes (entre los requisitos no hay conflictos o definiciones contradictorias). Esto es un imposible que se busca.
En cambio, los no funcionales, son restricciones a los servicios y funciones provistas por el sistema. Como restricciones de tiempo, sobre el proceso de desarrollo, estándares, etc. Por lo general se aplican sobre el sistema entero y no sobre un servicio o función particular.
Requisitos no funcionales
Definen las propiedades y restricciones del sistema. Estas pueden ser la confiabilidad, tiempo de respuesta o requisitos de almacenamiento (NO-SQL database). Las restricciones pueden ser la capacidad de dispositivos I/O (Funcionar solo en Ubuntu 18), representaciones del sistema, etc.
Estos requisitos pueden llegar a ser críticos al punto de que si no se cumplen el sistema será inútil. Por ejemplo, un sensor de movimiento con delay de 1 min.
Es más difícil identificar los componentes que implementan un requisito no funcional que los de los funcionales. Esto se debe a que estos engloban toda la arquitectura del sistema y no de componentes particulares. Y un requisito no funcional, por ejemplo, de seguridad, puede derivar varios requisitos funcionales que definen servicios del sistema.
Los requisitos no funcionales pueden ser muy difíciles de precisar haciéndolos difíciles de verificar. ¿Como pruebo que una interfaz es fácil de usar? Aparece el concepto de objetivo: Es una intención del usuario o cliente. Esto lo tenemos que traducir a un requisito funcional verificable. Por ejemplo, el objetivo de ser fácil de usar lo puedo verificar haciendo pruebas estadísticas con niños y ancianos (???). Los objetivos son útiles ya que trasmiten las intenciones que tiene el usuario con el sistema.
Tipos de requisitos no funcionales
Requisitos del producto: Especifican el comportamiento del producto (por ej. tiempo de respuesta)
Requisitos organizativos: Son consecuencia de las políticas y procedimientos de la organización. Por ejemplo, implementar todo usando Java.
Requisitos externos: Surgen de factores externos al sistema y su proceso de desarrollo, por ejemplo, requisitos de interoperabilidad, legislativos, etc. Por ejemplo, un software de facturación debe comunicarse con DGI para reportarla por temas legales.
Problemas con los requisitos
La mayor consecuencia es el retrabajo.
Ejemplos de los problemas que pueden surgir son:
- Poco involucramiento con los usuarios. Luego sucede que cuando el producto está entregado se quejan de que el producto no sirve.
- Planes inadecuados: Utilizar requisitos muy vagos para crear planes de trabajo.
- Recortes en los requisitos del usuario. En el medio te dicen, perdón, pero te debemos pagar la mitad.
- Requisitos ambiguos.
- Gold Plating: Requisitos que creemos que el usuario va a amar, pero nadie nos pidió que lo hagamos. ¿Por ejemplo, por que me voy a poner a implementar fuzzy search si el usuario no me lo pide ni estaría dispuesto a pagar por ello?
- No identificar correctamente a los usuarios. La persona que representa al cliente es alguien que nunca va a usar el software o no le interesa el proceso de desarrollo.
Proceso de ingeniería de requisitos
Varían ampliamente dependiendo del dominio de la aplicación, las organizaciones y las personas. Sin embargo, hay una serie de etapas que se identifican:
- Estudio de factibilidad
- Relevamiento u obtención y análisis de requerimientos
- Validación de requisitos
- Gestión de requisitos
El primero es algo que antes no se hacía mucho. Trata de estudiar la falibilidad de la propuesta. Ver si algo es posible de hacerse o no. El segundo es el intercambio con el cliente para obtener requisitos y su análisis para ver si tienen sentido. Luego la verificación consiste en mostrarle al cliente el resultado del análisis y preguntarle: "Está correcto"? Gestión es como hacer frente al cambio de los requisitos, saberlos manejar a lo largo de la evolución del proyecto. ¿Qué hago si de la nada el cliente no quiere algo que ya está implementado? Este proceso (a menos del estudio) es bastante iterativo y ocurre durante todo el ciclo de vida del software.
Este proceso puede verse como un espiral (elícitar, especificar, validar, elícitar, especificar, validar, ...):
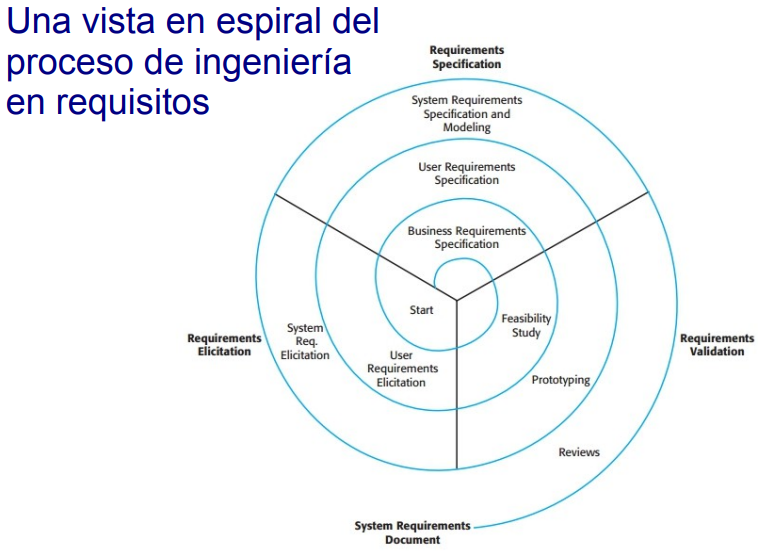
Las dificultades comunes en este proceso pueden ser:
- Los stakeholders no saben lo que quieren
- Los stakeholders expresan los requisitos en sus propios términos (me lo dicen a mí y no entiendo nada)
- Conflicto de intereses entre los stakeholders
- Factores organizacionales y políticos (por un cambio político, cambian las personas, pero el cliente cambia y tiene otras necesidades)
- Los requisitos pueden cambiar (en forma y prioridad)
Estudio de factibilidad
Tiene como objetivo averiguar si vale la pena implementar el sistema y si es posible implementarlo dadas las restricciones (presupuesto, calendario, tecnología, etc.). Recibe como input un conjunto de requisitos de negocio y una descripción del sistema. El output es un informe recomendando o no la realización del proyecto. Recordar que un sistema que no cumpla con los objetivos del negocio al final no tiene ningún valor.
Relevamiento u obtención y análisis de requerimientos
Los ingenieros trabajan con una variedad de stakeholders para obtener información del sistema y del dominio. Las etapas de este proceso son:
- Obtención de requisitos (descubrimiento, relevamiento).
- Clasificación y organización de requisitos.
- Priorización y negociación con el cliente.
- Especificación de requisitos.
Muchas veces el usuario quiere todo porque no sabe lo que cuesta.
Requisitos - Fuentes
- Metas - High level objectives
- Conocimiento del dominio
- Stakeholders
- Reglas del negocio
- Ambiente operacional (Hay empresas que quieren que toda la información este en toda la pantalla, otros prefieren cosas más minimalistas)
- Ambiente organizacional (Si el "Alta factura" lo hacen 3 personas, entonces no puede ser que haya una sola pantalla para hacerlo.)
Fuentes :: Técnicas de obtención
- Entrevistas
- Investigar antecedentes (Ver si X ya lo hizo alguien antes)
- Workshops
- Focus groups
- Observaciones
- Cuestionarios
- Análisis de interfaces del sistema
- Análisis de la interfaz del usuario
- Análisis de documentación
- Tormenta de ideas
- Escenarios
- Casos de uso
- Prototipos
- Modelado de procesos
- Historias de usuario
Entrevistas
La manera más obvia de averiguar qué quiere el cliente: Preguntarle. Sirve para entender el problema del negocio, el ambiente de operación, evita omitir requisitos y mejora las relaciones con el cliente.
Las ventajas es que está orientado a las personas, es interactivo/flexible y un proceso enriquecedor. Lo malo es que puede ser costoso y depende de las habilidades interpersonales.
Venís a mi chacra el fin de semana para contarme lo que precisas? Trae a tu familia.
Existen dos tipos de entrevistas. Entrevistas cerradas basadas en una lista de preguntas determinadas y abiertas donde se exploran varios temas con los clientes.
Para tener una entrevista efectiva hay que tener la mente abierta, evitar preconcepciones de los requisitos y saber escuchar. Utilizando una pregunta como trampolín se pueden llegar a lograr una propuesta de requisitos o trabajar en un prototipo del sistema.
Algunas preguntas genéricas que se realizan en una entrevista:
¿Dónde se inicia el proceso? ¿Como se va a utilizar la funcionalidad x? ¿Que debe cumplir la funcionalidad x? ¿A quién le puedo preguntar más sobre x? ¿En casos se puede usar x? ¿Cuándo no se podría usar x? ¿Hay otras maneras de hacer x? ¿La funcionalidad x cumple con todas las necesidades de negocio vinculadas a esta?
Algunas de las recomendaciones son: Establecer una buena relación, presentarse, revisar agenda, proponer objetivos y responder dudas. Mantener el foco de la discusión en los objetivos, preparar preguntas y maquetas (a las personas le es más fácil criticar que idear). Definir ideas (muchas veces los clientes no saben lo que es posible y lo que no). Escuchar activamente: paciencia, feedback, aclarar puntos confusos.
En la práctica, las entrevistas son una mezcla entre cerradas y abiertas. Son buenas para obtener una comprensión global de lo que quiere el cliente, pero no son buenas para entender el dominio del problema (el cliente no le es fácil/ es reluctante en explicar el entorno al cual está acostumbrado).
Investigar Antecedentes
Copiar, reusar, ver lo que ya está hecho (ctrl+c,ctrl+v)... ver los programas de facturación ya existentes.
Buena forma de comenzar un proyecto. Puede ser interna (Buscar en la estructura de la organización, documentos, políticas y procedimientos, documentación de sistemas) o externa (Publicaciones de la industria, visitas y literatura existente).
Las ventajas son ahorro de tiempo de trabajo, prepara enfoques y puede hacerse desde afuera de la organización. Lo malo es que a veces la perspectiva es limitada, lo que se releva puede estar outdated y ser demasiado genérico.
Workshop
Es una reunión estructurada en la cual un selecto grupo de interesados y expertos trabajan en conjunto para definir, crear, refinar y acordar documentos y modelos que representan los requisitos del usuario. Se precisa un facilitador el cual explica las reglas y objetivos al comienzo y luego mantiene la cohesión del trabajo a lo largo de la sesión así como la motivación.
Muchas veces se precisa sacar a las personas del ambiente. Nos reunimos todos un sábado en la casa del jefe, comemos y discutimos este problema.
Se recomienda mantener grupos pequeños, tiempos fijos para cada tema y tener una lista de temas a encarar.
Es una técnica efectiva para resolver desacuerdos entre los stakeholders pero es costosa tanto en tiempo como en recursos (pueden incurrir un sábado entero).
Focus Group
Son grupos de usuarios que participan en una actividad de obtención de requisitos para dar contribuciones e ideas. Se necesita un facilitador.
Agarras gente de distintos grupos de usuarios y los invitas a la sesión. (Es una práctica común en la política)
Las ventajas es que son útiles para explorar actitudes, impresiones, preferencias y necesidades de los usuarios. Es un encuentro rico cuando no es fácil acceder a los usuarios finales del producto. Lo malo es que los resultados son subjetivos, la información obtenida sirve para evaluar y priorizar requisitos.
Prototipado
Implementación parcial de un requerimiento. Permite al usuario y desarrollador entender mejor los requisitos, que es lo necesario y deseable, acotar riesgos. Es una práctica común para definir la apariencia de las interfaces due usuario, arquitecturas y aspectos críticos del proyecto.
“If a picture is worth 1000 words, then a prototype is worth a 1000 meetings ”
Es tomar una pisada en el espacio de soluciones. Soluciona el problema de la intangibilidad del problema, pone a tierra algo que se puede comparar, testear y criticar.
Da un feedback temprano (detecto problemas lo antes posible).
El usuario prefiere jugar con algo a que leer un documento aburrido.
Los prototipos de software pueden ser diseños estáticos o modelos dinámicos: simulaciones, scripts, prototipos de trabajo, maquetas, etc.
El alcance de un prototipo:
Mock ups: Bosquejos: Prototipo horizontal, se enfoca en porciones de UI, permite explorar comportamientos específicos del producto. Solo luce como se hiciera el trabajo. Validan la interfaz de usuario
Pruebas de concepto: Prototipos verticales, implementan una porción funcional de la aplicación, permite resolver incertidumbres sobre la factibilidad de la arquitectura propuesta. Funciona como un sistema real.
Desechables: Sirven para responder preguntas/ resolver incertidumbres, precisar requisitos. Conviene hacerlos los más rápidos y baratos posibles (no hacer más de lo necesario). Mucho cuidado con la calidad al incorporar algo de un prototipo desechable al producto final. (Ejemplo: Wireframes)
Evolutivos: Proveen una base arquitectónica sólida para desarrollar el producto de forma incremental mientras los requisitos se clarifican con el tiempo. Deben ser construidos con calidad en el código desde un principio, y debe contemplarse un rápido crecimiento y una mejora frecuente. Son una buena elección para aplicaciones que crecerán a lo largo del tiempo (eg. website). Las metodologías ágiles son un ejemplo de prototipación evolutiva: se construye un producto a lo largo de una serie de iteraciones utilizando feedback para ajustar los siguientes ciclos de desarrollo.
Los prototipos pueden adoptar muchas formas:
- Prototipos en papel: De baja fidelidad, pero es una forma rápida y barata de explorar como lucirá un producto. Involucra herramientas simples (papel, tarjetas, post-its). La idea es explorar posibles alternativas de comportamiento sin perderse en los detalles y especificaciones. Facilitan una rápida interacción y se utiliza para refinar una UI frecuentemente. Ejemplo: Storyboards.
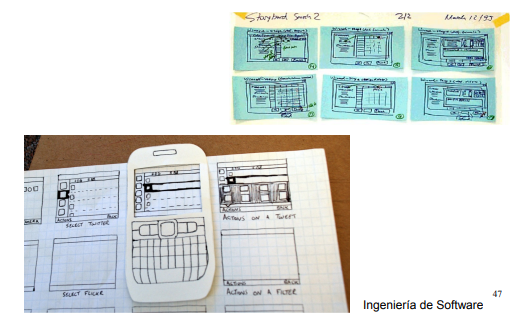
- Prototipos electrónicos: Alta fidelidad, existen herramientas de apoyo (Visio, PowerPoint, simuladores, canvas). La interacción con una versión similar a la final es un mecanismo valioso para estudiar el comportamiento de los usuarios.

Los prototipos deben evaluarse con el target-public adecuado. Para mejorar la evaluación se pueden realizar guías (ej. defensa de laboratorio, los casos de prueba a seguir). Hay que evitar explicarle a la persona como se debe usar el prototipo, debería ser intuitivo. Documentar todo lo ocurrido.
Se aprende más observando a los usuarios trabajando con el prototipo que preguntado qué piensan de él
En cuento a los riesgos. Uno de ellos es que el cliente piense que este es el producto final, o quiera una versión para probarlo más allá de la evaluación. Uno puede perderse en los detalles del prototipo e incluso generar expectativas irreales, por ejemplo. Un sitio estático va a responder casi de forma instantánea a diferencia de cuando está haciendo un trabajo real. Puede pasar que se invierta demasiado esfuerzo en el prototipo del que se debería.
Para utilizar la herramienta de prototipos exitosamente:
- Deben ser incluido en el plan de trabajo (no es algo extra, sino que forma parte de la etapa de requisitos).
- Se debe establecer claramente cuál es el objetivo de prototipo.
- Planificar la construcción de varios, tener varias versiones para mostrar.
- Hacer prototipos desechables tan rápido y barato como sea posible.
- No incluir detalles como validaciones, control de excepciones, manejo de errores, etc.
- No prototipar requisitos que no se entendieron (no hacer algo que no se hacer).
- Que sea cercano a la realidad.
- No sustituir el escribir requisitos por prototipar.
Etnografías
Implican observar a los usuarios mientras realizan sus actividades (ver a los cirujanos operar). Puede ser una actividad activa o pasiva. Esto sirve cuando los usuarios no son muy precisos al describir sus actividades. Están tan familiarizados o es algo muy complejo que es difícil de explicar.
Las ventajas es que es confiable (veo literal lo que hacen), experiencia rica y desarrolla empatía (el otro se hace amigo). El problema es que es costoso, sufre del efecto Hawthorne (Si observo a la gente, la gente va a tratar de hacer las cosas bien (actuar normal)). Hay que tener cuidado de no generalizar (las cosas que vi del cirujano x, no implican que todos los cirujanos hagan lo mismo).
Observar el comportamiento de la empresa, sin embargo, oculta la innovación de procesos mejores y más eficientes. Por ejemplo, muchas veces un proceso implica remover puestos de trabajo o reemplazar personas, al observar la dinámica de trabajo se trata de adaptar el software al proceso actual en detrimento de posibles mejoras de eficiencia.
Cuestionarios / Encuestas
Sirve para estudiar grandes grupos de usuarios. Previamente hay que determinar la información que se precisa, definir el tipo de formulario (abierto, cerrado, combinado, múltiple opción, orden relativo, etc.), desarrollar el cuestionario, probarlo y analizar su resultado. Es muy útil para obtener datos estadísticos sobre preferencias.
Las ventajas es que es económico, cómodo para el que contesta y las respuestas pueden ser anónimas. Lo malo es que no es un análisis muy seguro, puede darse de que el que contesta no se esfuerza o no responda ciertas preguntas.
Algunas recomendaciones para preparar las encuestas:
- Proveer opciones para todas las posibles respuestas.
- Hacer las opciones mutuo-excluyentes.
- Utilizar preguntas cerradas para análisis estadístico y abiertas para recolectar ideas/necesidades nuevas.
- Probar el cuestionario antes de mandarlo.
- No hacerlo muy largo.
Análisis de las interfaces del sistema
Implica examinar los otros interfaces con que se conecta el sistema (valido para sistemas no autónomos). Revela requisitos funcionales relativas al intercambio de datos y servicios entre el sistema.
Es bastante utilizado como un complemento a otras técnicas. Y es útil para realizar la validación de que no falta nada.
Se identifican los sistemas con que me debo de comunicar y describo las funcionalidades que puedan generar requisitos. Estos requisitos suelen ser lo que las otras interfaces esperan de mi/ y lo que yo recibo de ellas. (Pensar en un sistema de facturación.)
Análisis de la interfaz de usuario
Implica estudiar sistemas existentes para determinar requisitos de usuario y funcionalidades. (Por ejemplo, si quiero renovar una página web exploro la vieja para ver las cosas que esta hace, a su vez discuto con el cliente sobre los aspectos que deberían mejorar del sistema ya existente.). Sin embargo, no toda funcionalidad presente en el sistema que estoy analizando tiene que estar presente en el que voy a crear. O mantener una interfaz de usuario similar.
Análisis de documentación
Contempla examinar toda la documentación existente en busca de requisitos potenciales del software. La documentation más útil puede ser especificación de requisitos, procesos de negocio, manuales de usuario, aplicaciones existentes, etc.
Es una forma "rápida" de introducirse a un nuevo dominio. No molesto al cliente con reuniones innecesarias (para él).
Se puede pedir por ejemplo un modelo de la base de datos existente para saber con los datos e información que se tiene que trabajar y migrar.
Tormenta de ideas (brainstorming)
Ayuda la participación de todos los involucrados. Reglas: no se critica ni se debate, generar tantas ideas como sea posible, mutar y combinar ideas.
Hay una fase de generación donde se generan ideas (tirar pelotazos), luego en la fase de reducción se filtran las ideas según su validez y prioridades.
Sirve para innovar, encontrar nuevos productos, necesidades y modelos de negocio.
Historias y escenarios.
Las historias y los escenarios describen cómo se puede utilizar el sistema para una tarea en particular. Describen que hacen las personas, información que usan y producen y que sistemas utilizan en el proceso. Utilizan un texto narrativo que describen a alto nivel el uso del sistema. Tienen una información estructurada:
- Descripción de la situación inicial
- Descripción del flujo normal de eventos
- Una descripción de lo que puede salir mal
- Información sobre actividades concurrentes
- Descripción del estado cuando finaliza el escenario.

Los casos de uso son una técnica dentro de los escenarios. Un caso de uso puede ser un conjunto de escenarios. Es una técnica de UML. Un conjunto de casos de uso describe todas las posibles interacciones con el sistema, se identifica cada tipo interacción y los distintos actores. Tienen un modelo gráfico de alto nivel. Un diagrama de casos de uso ilustra todos los casos de uso y los actores que participan en cada uno:
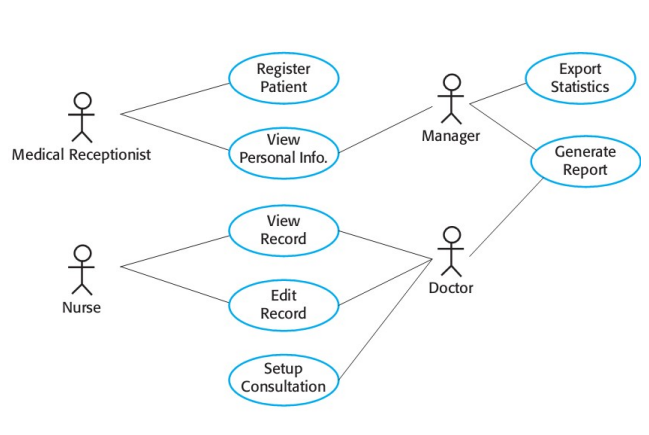
Es un formato simple y estructurado donde los usuarios y developers pueden trabajar juntos. No son de gran ayuda para identificar aspectos no funcionales. Mientras se definen los CU, puede ayudar definir las pantallas u objetos con que el usuario interactuará (por ejemplo, definir un formulario o campo y que tiene que tener, armar un prototipo). Podría llegar a ser utilizado en el diseño y testing del sistema.
Las ventajas son que permiten visualizar la interacción del sistema con los actores, muy util si en la implementación y diseño se utiliza UML y programación orientada a objetos. Las desventajas pueden darse en sistemas que no tiene usuarios/pocas interfaces ya que no resulta muy útil esta técnica, tampoco modela adecuadamente requisitos no funcionales.
Por otra parte, las historias de usuario refieren a descripciones cortas y de alto nivel de las funcionalidades expresadas en términos del cliente.
"As a < role >, I want < goal > so that < benefit > "
Pretenden contener justo la información necesaria para que los desarrolladores pueden producir una estimación razonable del esfuerzo para su implementación.
La idea es evitar perder demasiado tiempo relevando detalles de requisitos que luego cambian demasiado o son desestimados.
Modelado de Procesos
Permite entender el trabajo con múltiples pasos y entidades. Event-driven, incluye actividades manuales, automáticas y condicionales. Pueden volverse complejos si no se estructuran con cuidado. Los procesos complejos se pueden descomponer para ayudar a su entendimiento
Permite tener una visión de más alto nivel del proceso de negocio. Permite visualizar mejor los flujos de información.
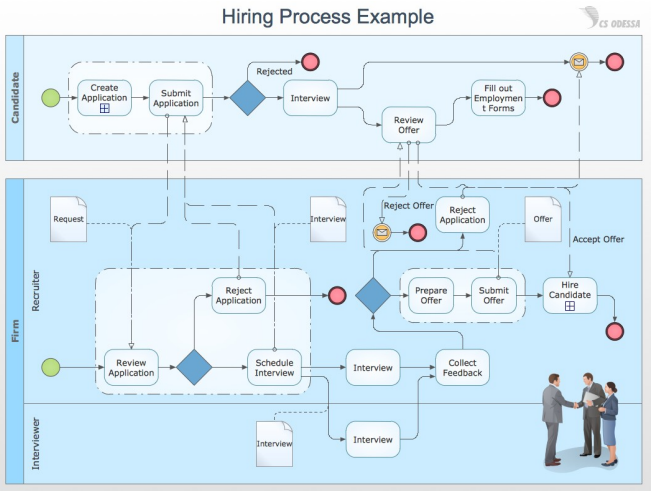
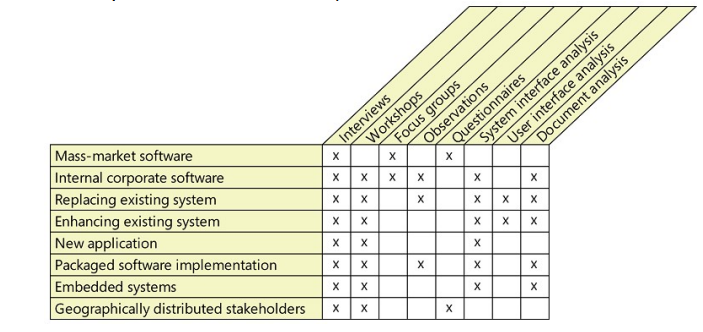
Selección de técnicas a utilizar:
Las técnicas que se pueden utilizar están estrechamente relacionadas con la realidad del proyecto. Weigers realiza un cuadro con ciertas sugerencias:
Consideraciones generales
Se recomienda organizar los requisitos según viewpoints (stakeholders), módulos, o sub-sistemas (arquitectura). Sin embargo, en la última ya estoy pensando cómo va a ser el diseño del sistema.
No esperar a que los clientes presenten una idea completa, corta y sin ambigüedades.
Casos de Uso: En detalle
Un caso de uso describe una secuencia de interacciones entre un sistema y un actor externo que resultan en un resultado de valor para el actor. Cada escenario comprende una instancia de uso del sistema, un caso de uso contempla un conjunto de escenarios relacionados.
Esto es independiente de los métodos de diseño o lenguajes que se usarán en la implementación.
Actor es una entidad que interactúa con el sistema para realizar los casos de uso. Un diagrama de casos de uso provee una rep. de alto nivel de los requisitos del usuario.
Los actores persona van con muñeco, los sistemas van con cuadrado y un arquetipo << actor >>
Es importante que cada caso de uso tenga:
- Identificador (nombre único)
- Breve descripción: Descripción breve de alto nivel del caso de uso y su flujo de acciones.
- Postcondiciones: Estado del sistema tras haber realizado el caso de uso.
- Precondiciones: Cosas que se deben cumplir antes de iniciar el CU.
- Lista enumerada de pasos que ilustran la secuencia de interacciones entre el actor y el sistema.
Además del flujo principal de pasos al realizar el caso de uso, se pueden tener varios flujos alternativos, estos describen otro escenario alternativo al principal (por ejemplo, en el caso de excepciones).
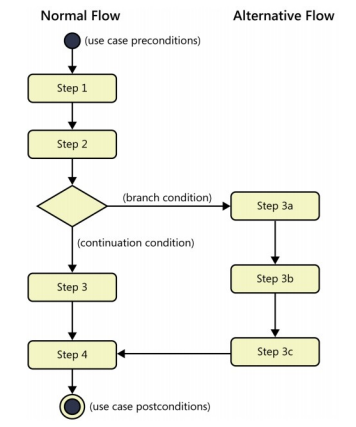
Por ejemplo:
8 .SYS: Listas las cuentas del usuario
9. SYS: Pide al usuario que seleccione la cuenta de origen de la lista o que la ingrese manualmente
10. USUARIO: Selecciona cuenta de origen de transferencia de la lista
10.A. El usuario desea ingresar manualmente el número de cuenta de origen
10.A.1. USUARIO: Selecciona ingresar manualmente el nro. de cuenta
10.A.2. SYS: Pide al usuario que ingrese el nro de cuenta
10.A.3. USUARIO: Ingresa nro de cuenta
10.A.4 Vuelve al punto 5
11. Pide al usuario que seleccione cuenta de destino
...
Los flujos alternativos se pueden anidar, se puede omitir la notación del flujo si se indenta correctamente:
1.
2.
2.A: COND X
2.A.1
2.A.2
2.A.2.B: COND Y
1.
2.
2.A.3
3.
...
Cuando el caso de uso solo incluye una descripción y pre/pos condiciones (sin flujo principal), a este se le llama CU de alto nivel, cuando se incluye los flujos alternativos (y los flujos normales), se le llama caso de uso expandido.
Relaciones entre casos de uso
Existen casos de uso que "ejecutan" otros casos de uso. El caso que incluye a otro se le llama caso base y al otro incluido. Se pueden incluir casos de uso tanto en flujo principal como alternativo.
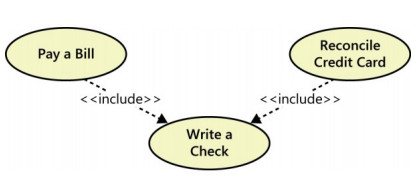
Por ejemplo, en el flujo:
1. El usuario ingresa al sitio.
2. <<Include>> "Autenticar usuario"
3. Ofrecer menú de servicios
...
A su vez, los casos de uso se pueden extender. Es decir, se agregar comportamiento a otro caso de uso. Se puede utilizar para describir mecanismos alternativos complejos.
Una extensión solo se ejecuta cuando se cumple una condición particular en un punto especifico del caso de uso a extender.

Ejemplo:
CASO DE USO RETIRAR DINERO
Flujo principal:
...
6. CA envía código de Tarjeta, PIN, cuenta y monto al SC
7. El SC contesta: OK
8. El Cliente pide dispensar el dinero
9. El CA dispensa el dinero
Puntos de extensión:
Retiro de monedas: En el punto 8 del flujo principal.
Identificar casos de uso
Se pude ir de general a especifico (identificar los actores, luego los procesos soportados por el sistema y por último definir los casos de uso para las actividades en las cuales actúan los actores) o de especifico a general (crear escenarios específicos para ilustrar cada proceso de negocio, luego generalizar en casos de uso e identificar actores).
Se recomienda identificar eventos externos a los cuales el sistema debe responder, luego como se debe reaccionar a tales eventos y quien lo hace permite identificar los actores y casos de uso.
También sirve identificar el flujo de datos. Los datos que deben entrar y salir del sistema, actualización y borrado...
Consideraciones
No tratar de forzar a que todos los requisitos sean contemplados por CU. Algunos no tienen valor hacerlo. Ser concreto y mantenerse dentro de los límites del caso de uso al hacer el flujo.
No escribir demasiados casos de uso, evaluar si todos son necesarios o si alguno corresponde a distintos escenarios de un mismo CU.
No crear casos de uso muy complejos, no se tienen que incluir checks o validaciones de datos triviales.
Los caos de uso no tienen que definirse con total especificidad o completitud la primera vez. No vale la pena detallar un CU si luego va a cambiar en unos meses.
No incluir detalles de la interfaz gráfica, pueden agregarse en otros documentos.
No incluir casos de uso que no son atendidos por los usuarios (actores).
Análisis de requisitos
No es una tarea que se da independiente de la obtención y especificación. (Concepto de Espiral), Es algo que se da naturalmente... Si bien no hay una definición o técnica exacta, se puede entender como:
- Resolver y detectar conflictos entre requisitos.
- Descubrir las fronteras del software y como debe interactuar con el ambiente
- Elaborar los requisitos del sistema (las necesidades de cómo trabajan los usuarios por fuera del software) para derivar los requisitos del software.
Actividades que se incluyen en el análisis:
Clasificación de requisitos: Utilizando categorías, prioridad, alcance y estabilidad de los requisitos (que tanto varían las ideas en cada reunión, puedo tratar de ayudar al cliente a estabilizarlo o centrarme en los otros).
Modelado conceptual: Realizar modelos resulta clave. Ayudan a entender la situación en la cual ocurren los problema o necesidades (modelo de prototipos, conceptual).
Diseño de la arquitectura y asignación de requisitos: Si bien solo me pregunto el QUE? y no el COMO? En la realidad ya vamos pensando en cómo se podría, así podemos decirle al cliente si algo es viable o no. Parte del análisis implica ir intuyendo la solución para satisfacer los requisitos
Negociación de requisitos: Resolución de conflictos. Priorización (definir cuáles son las cosas centrales).
Análisis Formal: Lógica de predicados. Definir formalismos de nuestro sistema.
Solo en análisis formal yo puedo probar que la especificación es correcta.
Especificación de requisitos
Especificación corresponde a escribir los requisitos.
- Es el proceso de escribir requisitos de usuarios y del sistema en un documento de requisitos.
Los req. de usuario deben ser entendidos por el usuario, mientras que los del sistema son más detallados y están pensados para los desarrolladores (Voy a hablar con muh api en muh electron).
Los requisitos pueden ser parte de un contrato para el desarrollo del sistema. Por lo tanto, se debe intentar que sean lo más completos y claros posibles.
Para escribir una especificación de requisitos existen 5 formas:
- Lenguaje natural (la de antaño). Los requisitos son escritos usando frases numeradas escritas en lenguaje natural.
- Lenguaje natural estructurado: Lenguaje natural, pero con una estructura/plantilla definida. Por ejemplo: Nombre: Pre: Pos: Flujo:
- Lenguaje de descripción de diseño: Este enfoque usa un lenguaje como un lenguaje de programación, pero con características más abstractas para especificar requisitos con definiciones. Se usa raramente, aunque puede ser útil para interfaces.
- Notaciones gráficas: Modelos gráficos complementado con notaciones de texto. Ejemplo: UML.
- Especificaciones matemáticas: Notaciones basadas en conceptos matemáticos como máquinas de estado, predicados, etc.
Requisitos en lenguaje natural
En la especificación en lenguaje natural los requisitos tienen la ventaja de ser expresivos e intuitivos (los mismos usuarios lo entienden).
Algunas recomendaciones para escribir requisitos naturales:
- Crear un formato estándar para todos los requisitos
- Usar el lenguaje de manera consistente. El lenguaje usado para los requisitos obligatorios debe ser el mismo para los requisitos deseables (tiempos verbales)
- Utilizar subrayado para identificar partes clave
- Evitar el uso de jerga informática
- Incluir explicación (lógica) de por que existe este requisito.
Los problemas más claros del lenguaje natural son:
- Falta de claridad. Es difícil precisar exactamente un sistema sin que sea difícil de leer
- Confusión de requisitos. Los requisitos funcionales y no funcionales se confunden.
- Requisitos mezclados. Varios requisitos diferentes podrían expresarse juntos.
Especificaciones estructuradas
Es una aproximación a los requisitos donde la libertad del escritor es limitada, los requisitos se leen de manera estándar. Funciona bien cuando todos los requisitos se pueden escribir de una maneara similar, permite chequear que no falte nada de forma más fácil.
Posibles secciones:
- Definición de la función o entidad.
- Descripción de las entradas y de dónde vienen.
- Descripción de las salidas y a donde ir.
- Información acerca de los datos necesarios para el cálculo y otras entidades utilizadas.
- Descripción de las acciones a tomar.
- Pre y post condiciones.
- Efectos secundarios.
Es importante saber el origen de los requisitos. ¿De dónde los saqué? Es esencial para mediar requisitos o para confirmar que es una necesidad real: Quien me pidió esto? ¿Quién lo necesita?
La especificación estructurada es la generalización de la técnica de los escenarios.
Especificación tabular
Escribo los requisitos en un estilo tabular donde si se cumplen condiciones realizo acciones. Ej:
Condition | Action
SugarLevel < N --> CompDose = 0
SugarLevel is stable --> CompDose = 0
SugarLevel increasing --> CompDose = round(r1/2.23) if round resulto 0 then CompDose =1 else Explode
Requisitos y diseño
Muchas veces es imposible excluir el cómo? de la pregunta del que? Por ejemplo, si el cliente quiere específicamente que sea una arquitectura web, ya me veo condicionado en el diseño. Algunos aspectos que influencian esto son:
- La arquitectura del sistema puede ser diseñada para estructurar los requisitos.
- El sistema puede interactuar con otros sistemas que generan requisitos de diseño.
- El uso de una arquitectura específica para satisfacer requisitos no funcionales.
Características deseables
Características deseables de un requisito
- Completo: Contiene toda la información para entenderlo.
- Correcto: Describe de forma precisa una necesidad y de forma clara la funcionalidad a desarrollar.
- Factible: Es un problema que es posible implementar según las limitaciones operacionales (Muchas veces lo escribo igual para luego negociarlo más adelante).
- Necesario: Tiene valor para el negocio.
- Priorizado: Fue priorizado según su importancia, utilizando la perspectiva de los stakeholders.
- No ambiguo.
- Verificable: Se pueden realizar pruebas para determinar si se encuentra presente en un producto o no.
Características deseables de conjunto de requisitos
- Completo: No hay información innecesaria o de requisitos ausentes
- Consistente: No hay conflictos entre ellos
- Modificable: Es posible reescribir un requisito sin que se rompa todo
- Trazable: Puedo rastrearlo para atrás para ver quien me pidió eso y para adelante para poder verificar si está presente en el producto.
Guías para la escritura de requisitos
Perspectiva del sistema o del usuario
Se escriben plantillas a reemplazar:
[ Optional precondition ] [ Optional trigger event ] the system shall [ expected sys response]
Si el químico se encuentra en el almacén, el sistema mostrara una lista de todos los contenedores con ese producto
The[ user class or actor name] shall be able to [ do sth ] [ to sth ] [ qualifying conditions, response time or quality statement]
El químico-farmacéutico deberá ser capaz de volver a ordenar cualquier producto que ha ordenado en el pasado, para lo cual podrá editar y recuperar una orden antigua.
Estilo de escritura
- Tratar de incluir la frase clave al principio (¡como en inglés!). Luego los detalles accesorios.
- Evitar utilizar voces activas y pasivas de forma intercalada, se recomienda siempre voz activa.
- No utilizar sinónimos para un mismo concepto.
- Escribir frases completas con correcta gramática y ortografía.
- Mantener las oraciones y los párrafos concisos.
- Hacer un requisito por párrafo.
Nivel de detalle
Se deberá ser detallado si:
- El trabajo lo hará un cliente externo.
- El desarrollo o pruebas será tercerizado.
- Los miembros del proyecto están distribuidos.
- Las pruebas del sistema se basan en los requisitos.
- Son necesarias estimaciones precisas (Para los contratos).
- Trazabilidad de los requisitos es importante .
Puedo incluir menos detalles si:
- Los clientes están muy involucrados.
- Los desarrolladores tienen mucha experiencia en el dominio.
- Se dispone de precedentes (software a reemplazar).
- Se usará una solución empaquetada (i.e software adaptado).
- No todos los requisitos tienen que tener el mismo nivel de detalle. Aunque se recomienda ser consistentes.
Evitar la ambigüedad
- Utilizar términos de forma consistente (glosario).
- Evitar adverbios importante!!. Nada de Generalmente...
- Escribir por la positiva.
Evitar incompletitud
- Incluir operaciones simétricas (si puedo guardar, lo tengo que poder recuperar).
- Revisar en búsqueda de las excepciones faltantes.
Ingeniería en requisitos en Procesos Ágiles
La diferencia clave entre la ingeniería de requisitos entre procesos basados en planes y los métodos ágiles es en qué momento se emplea. En el de planes se da todo al principio (principalmente), en el iterativo se da a lo largo de todo el ciclo de vida del desarrollo.
En los procesos en planes hay que escribir en forma rigurosa y en los ágiles es más informal. Se trata de centrarse en los requisitos más prioritarios.
¡¡¡En los proyectos basados en planes el cambio de requisitos implica retrabajo, en los ágiles no!!! El cambio es lo esperado y no hubo trabajo previo ya que no se habían especificado todos los requisitos.
Generalmente los requisitos o características del producto se especifican como historias de usuario.
Los requisitos que se toman en las iteraciones más cercanas van a tener un mayor nivel de detalles que en las más alejadas en el tiempo.
Historias de usuario (HU)
Una HU describe una funcionalidad, que por sí misma aporta valor al usuario
Representación de un escrito de manera simple y sencilla. Son una forma rápida de administrar los requisitos cambiantes de un proyecto.
Una historia de usuario se compone de tres elementos:
Card (FICHA). Descripción breve de la historia de usuario, utilizada como recordatorio y para planificar.
Conversación: Comunicación cara a cara que intercambia no solo info sino también pensamientos, opiniones y sentimientos. (El intercambio ente cliente/developer )
Confirmación: Detalles de la historia de usuario para que el equipo sepa lo que tienen que construir y lo que la contraparte espera. Se conoce como criterios de aceptación. Este punto es el que crece en detalle a medida que se acerca su momento de implementarlo.
Redacción de Historias de Usuario
Mike Cohn sugiere escribir con el formato: Como [ rol ] quiero [ funcionalidad ] para [ beneficio ]. Los beneficios de esto son: Primera persona (me deja pensar como el otro), priorización (conocer necesidades) y propósito (conocer las necesidades del cliente. Saber para que el usuario hacer x. ). También permite al equipo de desarrollo plantear alternativas que cumplan con el mismo propósito.
Cuando una historia de usuario es demasiado grande se le denomina épica. (No necesariamente en redacción sino en abstracción, ser muy general). Generalmente estas historias épicas se clasifican en:
- Historia de usuario compuesta: Contiene múltiples historias de usuario
- Historia de usuario complejas: No se pueden separar fácilmente en un conjunto de historias de usuario.
La determinación final de si una historia tiene el tamaño adecuado se basa en el equipo, capacidades y tecnologías en uso.
Criterios de Aceptación HU
Los criterios de aceptación ayudan a entender mejor como se espera que un producto se comporte frente a ciertas situaciones. Ayudan a resolver ciertas expectativas y permiten que el desarrollo sea más fluido, claro y con menor incertidumbre para el equipo.
Ejemplo: HU: Visualizar locales de comida con delivery. Como: Cliente habitual. Quiero: Ver un listado de locales de comida. Para: Evaluar distintas propuestas.
Criterios de aceptación: Los locales de comida estas ordenados según la valoración y la cercanía con el usuario. Para cada local de comida con delivery se muestra nombre, foto y distancia con respecto al usuario y tiempo estimado de entrega. Si el usuario selecciona un local de comida con delivery, se despliegan las comidas que vende el local: nombre, precio y descripción.
Existen diversas técnicas para escribir criterios de aceptación:
Técnicas de comportamiento: Dada una condición, cuando ocurre el evento X, entonces sucederá Y. Así se consigue una estructura consistente de fácil testeo. Por ejemplo: Si el cliente tiene el GPS apagado, se muestra la última ubicación del celular y se repliega un listado con las 10 opciones de delivery según esa ubicación
Técnicas de escenarios: Suele definir el escenario normal o usual y escenarios alternativos de la funcionalidad en cuestión. Se debe describir como el usuario ejecutaría los diferentes pasos en cada uno de los trayectos (escenarios). La forma más normal de escribirlos es con el lenguaje específico para las descripciones de comportamiento de software llamado Gherkin. La sintaxis de Gherkin: Dado que [ ctx ] y [ ctx] , cuando [ evento ], entonces [ resultado/comportamiento esperado ]. Por ejemplo: Dado que el GPS esta activado, cuando se despliegue el listado de delivery entonces el sistema desplegara una lista con todos los deliverys ordenados.
INVEST
Las HU deben cumplir las reglas mnemotecnias INVEST:
- Independiente: En lo posible, se debe tener cuidado en la introducción de dependencias entre las historias de usuario
- Negociable: Los detalles de la historia de usuario se negociarán e un una conversación cliente/developers.
- Valiosa: Para los usuarios
- Estimable: Que no sea difícil medir su trabajo. Esto se da cuando la HU es muy grande, hay poco conocimiento funcional/técnico en el equipo.
- Small (en esfuerzo).
- Testable: Tiene que poder comprobarse para ser confirmada.
Requisitos no funcionales
Newkrik y Martin (2001) recomiendan la práctica de anotar una historia con la palabra CONSTRAINT en un POST-IT para cualquier historia que debe ser obedecida pero no implementada de forma directa.
Historias de usuario de tipo SPIKE
Son historias de usuario que hay que investigar para poder realizarlas. Por ejemplo, investigar, explorar, comprender mejor un requisito, o aumentar la fiabilidad de una estimación de alguna HU.
Suelen ser de tipo técnico (se utilizan para determinar viabilidad), o funcional (para determinar funcionalidad). Es cuando no tengo muy claro que es lo que hay que hacer y hay que ponerse a investigar. Hay que acotarlas en el tiempo. Por ejemplo, se asignan dos semanas para relevar esta historia de usuario SPIKE para generar nuevas historias de usuario (refinamiento).
Modelado del sistema
El modelado del sistema es el proceso de desarrollar modelos abstractos del sistema, en cada modelo se presentan diferentes perspectivas. Ayuda a los analistas a entender las funcionalidades del sistema y facilita la comunicación entre clientes. Actualmente, esta actividad se basa primordialmente en notación UML (En la práctica profesional no tanto xd)
Los modelos de sistemas existentes se utilizan durante la ingeniería de requisitos. Ayuda a comprender que hacen y pueden ser usados para discusiones acerca de sus fortalezas y debilidades.
Los modelos de nuevos sistemas son usados durante la ingeniería de requisitos para ayudar a explicar los requisitos propuestos a los otros stakeholders del sistema. También se pueden discutir propuestas de diseño.
Es un proceso de ingeniería guida por modelos: model-driven. Es posible generar una representación casi total del sistema.
Perspectivas
Se pueden tener varias perspectivas de como modelar el sistema.
- Externa: Se modela el contexto/entorno del sistema. En UML: Diagramas de casos de uso. Diagrama de estados.
- Interacción: Se modelan las interacciones entre sistemas y su entorno. En UML: Diagramas de casos de uso.
- Estructural: Se modela la organización del sistema o la estructura de los datos que procesas en l sistema. En UML: Diagrama de clases.
- Comportamiento: Se modela el comportamiento dinámico del sistema y la forma en que responde a los eventos. En UML: Diagramas de actividad.
IIS no trata de cómo usar una herramienta X sino de cuando hay que utilizarla.
Uso de modelos gráficos
Pueden ser utilizados para facilitar la toma de decisiones acerca de sistemas existentes o propuestos. Ya sea completos o incompletos sirven para aportar algo a la discusión.
Son una manera de documentar un sistema existente: Su representación debe ser exacta y correcta pero no necesariamente completa.
Sirven para idear una descripción detallada para luego generar una implementación del sistema.
Modelos de contexto
Son utilizados para ilustrar el contexto operacional del sistema. Temas sociales y organizacionales pueden afectar la decisión sobre donde situar los límites del sistema.
Limites del sistema: Que cosas son las que van y que es lo que no. Definir esto tiene un efecto profundo sobre los requisitos del sistema.
Modelos de interacción
Me permite modelar la interacción con usuarios, sistemas y componentes.
Modelar la interacción con los usuarios ayuda a identificar requisitos. Modelar la interacción con otros sistemas permite identificar posibles problemas de interfaces. Modelar la interacción entre componentes permite entender si la estructura es apropiada para los requisitos no funcionales establecidos.
En UML, podemos modelar la interacción de un sistema utilizando un modelo de casos de uso y diagramas de secuencia.
Un diagrama de secuencia muestra la secuencia de interacciones que tienen lugar en un caso de uso particular o instancia de caso de uso.
Modelos estructurales
Disponen la organización del sistema en términos de componentes que lo componen y sus relaciones.
Pueden ser modelos estáticos con la estructura del sistema diseñado o dinámicos los cuales muestran la organización del sistema mientras se ejecutan (recordar instancia de cajas de objetos en uml). Sirven para discutir la arquitectura del sistema.
Un ejemplo de esto son los diagramas de clase:
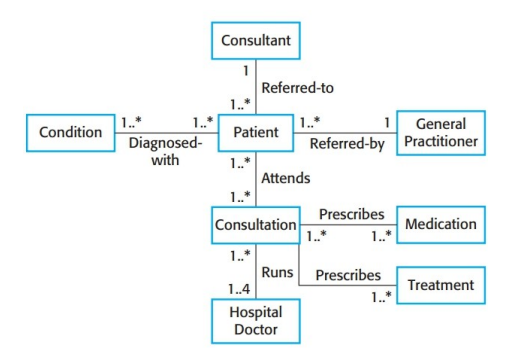
En las fases tempranas de desarrollo los objetos representan objetos (conceptos) de la realidad.
Modelos comportamiento
Modelan el comportamiento dinámico de un sistema en ejecución. Muestran qué sucede o qué debe suceder cuando un sistema responde a los estímulos de su entorno.
Los estímulos pueden ser datos (las cosas que entran y salen) o por eventos (que sucede en el sistema/ situaciones).
Esto hace que haya dos formas de modelar: data-driven y event-driven.
En data driven: Se muestran los datos que entran y los que salen. Modelar el flujo de datos a través del sistema. UML no soporta de forma natural estos modelos de flujo, pero pueden utilizarse diagramas de secuencia para ello.
En event driven: Muestra como un sistema responde a eventos. Se basa en que el sistema tiene un numero finito de estados y existen estímulos que hacen que el sistema pase de un estado a otro. En UML se pueden utilizar diagramas de estado.
Piensen, por ejemplo, el estado de una factura. Mantengo el estado en una tabla y ese estado condiciona las acciones que se pueden hacer sobre ellas.
Model Driven Engineering
Es un enfoque para el desarrollo de software donde los modelos (no los programas) son los protagonistas del proceso de desarrollo. Los programas se generan de forma automática a través de los modelos. Es una idea bastante utópica y todavía no es claro si es el futuro permitirá realizarla.
Otros modelos de requisitos: Weigers
Los modelos visuales ayudan a identificar requisitos faltantes o inconsistencias. Los modelos sirven tanto para explorar requisitos como para diseñar soluciones. No hay que interpretar que los clientes saben interpretar un modelo. En general, no se puede modelar todo el sistema, lo mejor es modelar las porciones del sistema más riesgosas/críticas.
El diagrama de flujo de datos de Weigers se utiliza para ilustrar la idea del flujo de datos. Es bastante flexible... era bastante popular en los 80 xd.
Otro tipo de diagramas bastante utilizado (precursor a los casos de uso) son los diagramas de andariveles, y son fáciles de entender para el cliente.
Los diagramas de estados de Weigers, no son UML, por lo que son más simples de entender para el cliente. Nos permite ver cómo nos movemos de estado a estado. En los casos en que los estados son simples, también podemos utilizar una tabla de estados. La cual es más "fácil" de entender. Nos permite chequear la completitud de las transiciones entre estados, ya que chequeo explícitamente las distintas combinaciones.
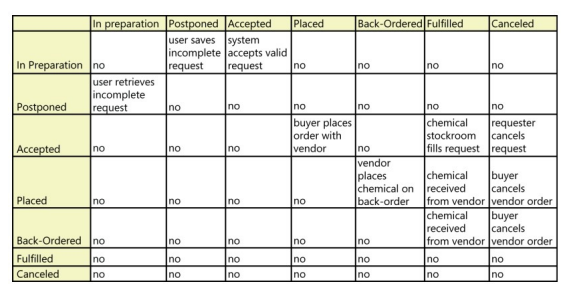
Los mapas de dialogo son una forma de modelar cuales son los diálogos que le van a aparecer al usuario a medida que navega por el sistema. Cada evento nos lleva a un dialogo distinto (transición). Es bastante útil para quienes trabajan con interfaces de usuario o diseñadores.
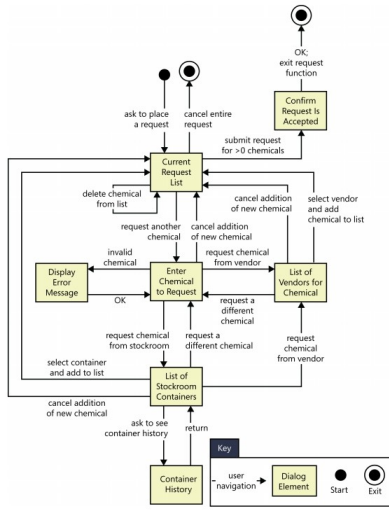
Otra herramienta cool son los árboles de decisión (o tablas). Nos permite visualizar de forma clara algoritmos que se basan en condiciones. Esta bueno porque lo entiende cualquiera.
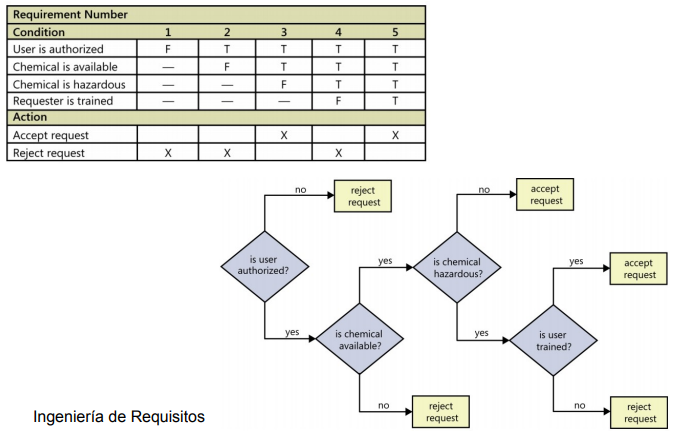
Otro tipo de diagrama son las tablas de evento respuesta. (Por lo general se representan mejor con proceso de negocio...) es bastante complejo y no se usa mucho. Permite representar la respuesta del sistema a los posibles eventos que pueden ocurrir. Un evento es un cambio o actividad que tiene lugar en el ambiente de usuario que estimula una respuesta en el sistema.
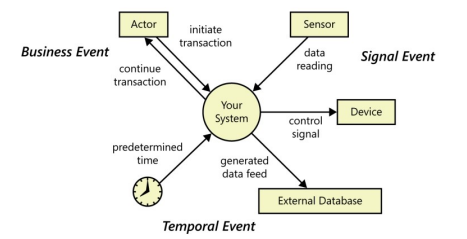
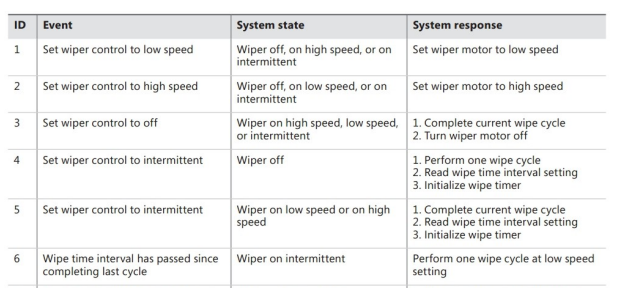 ]
]
Documento de requisitos
Los requisitos no se dejan por ahí sueltos, sino que se estructuran en un documento. El SRS (Software Requirements Specification) es como la declaración oficial de los requisitos. Hay muchos estándares que lo modelan...
Se hace el documento... y luego esto es lo que va a ser...
El documento de requisitos de software (SRS Software Requirements Specification) es una declaración oficial de los que se requiere de los desarrolladores del sistema. Puede incluir una definición de los requisitos del usuario y una especificación de los requisitos del sistema. No es un documento de diseño, se debe indicar lo que el sistema hará, pero no cómo lo hará.
Las metodologías ágiles prefieren, en lugar de construir un documento formal es recolectar requisitos de forma separada. Por ejemplo: Extreme Programming (XP).
¡A diferencia, las metodologías ágiles son tipo... si! Yo te voy haciendo lo que precisas... hasta que te quedes sin dinero :)).
Los usuarios de un documento de requisitos son varios:
- Clients: Especifica los requerimientos y se fija que satisfaga sus necesidades.
- Managers: Usa el documento de requerimientos para definir costos/precios y planear el proceso de desarrollo
- System engineers: Usa el documento para entender cómo desarrollar el sistema
- Testers: Usa los requerimientos para desarrollar tests de validación
- Janitors: Usa los requerimientos para entender el sistema, sus relaciones y como debe funcionar.
Se tiene que hacer un compromiso sobre todas estas partes.
Estructura del documento
Prefacio: Definir los lectores esperados, historial de versiones, justificación de dicha versión y resumen de cambios realizados en cada versión.
Introducción: Definir necesidades y funciones del sistema y explicar cómo actuará en concordancia con su ambiente. También debe explicar como el sistema se ajusta a los objetivos del negocio o a los planes estratégicos de la organización.
Glosario: Definición de términos técnicos utilizados en el documento
Definición de requisitos del usuario: Descripción de los servicios prestado para el usuario. También se deben especificar los requisitos no funcionales del sistema. Esta descripción puede ser en lenguaje natural, diagramas u otra notación entendible para los clientes. Las normas del producto y proceso deben estar bien especificadas
Arquitectura del sistema: Visión de alto nivel de la arquitectura. Mostrando distribución de funciones sobre los módulos del sistema.
Se menciona la arquitectura del sistema (más o menos) porque es difícil cobrar algo sin decirte lo que voy a hacer de forma un poco más concreta...
Especificación de requisitos del sistema: Describir con más detalles los requisitos funcionales y no funcionales. Así como interfaces con otros sistemas.
Modelos del sistema: Incluir modelos gráficos que muestra la relación del sistema entre sus componentes y su entorno.
Evolución del sistema: Describir los supuestos fundamentales en el que se basa el sistema y cualquier cambio previsto debido a la evolución del hardware, necesidades de los usuarios, etc. Esto es útil para que los diseñadores del sistema puedan prepararse para el cambio. (decisiones de diseño).
Apéndice: Información relacionada con la aplicación a desarrollar, hardware, descripción de database, etc.
Índice: Pueden ser índices de distinto tipo...
Existen estándares de la IEEE para la definición y estructura de los documentos. En el curso no se ven en detalle...
Las consideraciones que hay que tener para este documento son obvias: Correcta, no ambigua, completa, consistente, ordenada por importancia y/o estabilidad, verificable, modificable, trazable, factible y comprensible.
Priorización de requisitos
Todo proyecto que tenga recursos limitados necesita definir prioridades en los requisitos. Priorizar ayuda a entregar el mayor valor de negocio tan rápido como sea posible con las restricciones existentes.
Hay que tener en cuenta que los clientes pueden estar reluctantes para priorizar pensando en que lo no prioritario nunca sea hará. Y los programadores no les gusta mucho porque da la impresión que no son capaces de hacer todo.
Se debe elegir un nivel de abstracción para los requisitos (por casos de uso, historias de usuario o maybe flujos en cada caso de uso...)
Se deberá tener en cuenta las necesidades de los clientes, la importancia de los requisitos para los clientes, las relaciones de precedencia entre los requisitos (para ver factura tengo que poder crearla), requisitos que deben estar todos juntos (los programadores prefieren que ciertas cosas vayan todas juntas, es más rápido), el costo de satisfacer cada requisito (si en un mes puedo poner 100 usd, tengo que priorizar con esto en cuenta).
2/3 de las funcionalidades de todos los sistemas de software se usan raramente o nunca.
Observación: Si terminamos el proceso de priorización con todos los requisitos con la misma prioridad entonces no hemos hecho nada xd.
Hay que evitar dos situaciones de priorización. Por decibeles: Los que gritan más son los que se le asignan mayor prioridad. Por amenazas: Los más poderosos es a los que consiguen que se prioricen las cosas. Las prioridades de los poderosos o de los que más gritan no necesariamente lleva a la mejor situación de las prioridades del sistema de manera objetiva.
Existen algunas técnicas interesantes para priorizar requisitos...
- Adentro y fuera: Se nombra cada requisito y se decide si queda en el alcance o no (¿esto va o no va?). También puede ser por iteraciones/ versiones del sistema.
- Comparación por pares y ranking: Se hace un ranking generan de todos los requisitos comparando de a pares.
- Escala de 3 niveles: Se utilizan dos dimensiones:
}}){kind=link}
- 4 niveles (debe, debería, podría, no va.)
- 100 dólares. (¡Muy popular en agile dev!): Asignar dinero disponible y luego "invertirlo" en los requisitos a priorizar.
- Producción basada en valores, costos y riesgos:
}}){kind=link}
Validación de requisitos
Es el proceso por el cual se determina si los requisitos relevados son consistentes con las necesidades del cliente.
Verificación: Determina si el producto de alguna actividad cumple con los requisitos (hace las cosas bien).
Validación: Evalúa si el producto satisface las necesidades del cliente (hace la cosa correcta).
En el proceso hay que planificar quién (que stakeholder) va a validar qué (artefacto de software) y cómo (técnica). Siempre que se evalúa tiene que haber un registro con reporte de validación y firma del stakeholder.
Un problema común en el software es que con el tiempo las expectativas del cliente suben (el cliente se queda maquinando en lo que pidió y como se lo imagina) y las expectativas del desarrollador bajan (el desarrollador va investigando y cada vez le parecen más triviales las cosas que quiere hacer). Si no se hace nada al respecto con esta disparidad de expectativas, al entregar el producto final pueden haber malas situaciones como la frustración del cliente y que este piense que el trabajo final es una "porquería", no era lo que esperaba y que se reúse a pagar o exija más trabajo del acordado.
Para evitar esta diferencia de expectativas, lo que se hace es tener encuentros de contacto con el cliente, donde se muestra el trabajo se da opinión y se aclaran conceptos. De esta forma mantiene un gap máximo entre las expectativas. Esta idea se ilustra en:
Chequeo de requisitos
Se debe chequear:
- Validez: El sistema provee las funcionalidades que mejor soportan las necesidades del cliente?
- Consistencia: Hay algún requisito en conflicto?
- Completitud: Está todo lo que el cliente me pidió?
- Realismo: Los requisitos pueden ser implementados con mis capacidades?
- Verificabilidad: Como puedo verificar que lo que hice está bien.
Ahora bien, los requisitos no funcionales son más difíciles de evaluar. Para ello, se debe acordar con el cliente medidas cuantitativas (métricas) para probar de forma objetiva que el requisito está presente (ideal). Es difícil especificar de forma cuantitativa un requisito no funcional de parte del usuario.
Técnicas de validación
Algunas de las técnicas son:
- Revisión de requisitos: Me siento con el cliente y me pongo a leer si esta todo bien los requisitos
- Prototipado: Uso un modelo ejecutable para ver si el cliente le parece bien cómo va la cosa.
- Generación de casos de prueba: Muestro el resultado de ejecutar el sistema para esta situación, a ver si es lo que el cliente esperaba.
Ejemplo de esto son:
- Manuales: Lectura de documentación por el cliente, recorrida rápida de la documentación con stakeholders. Entrevistas. Chequeo manual de ref. cruzadas. Validación formal (revisiones e inspecciones formales con stakeholders), listas de comprobación (checklists), escenarios, generación de casos de prueba.
- Automatizado: Chequeo automático de ref. cruzadas, ejecución de modelos para verificar funciones y relaciones, construcción de prototipos y simulaciones.
Realizar verificación y validación me permite ahorrar trabajo en las etapas posteriores a la implementación. Lo que genero al principio puede usarse al final. Esto es justamente el proceso V de desarrollo:
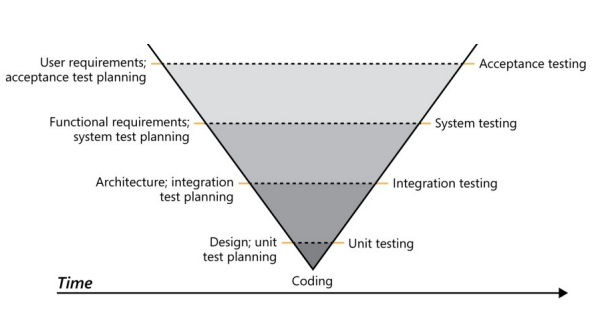
Criterios de aceptación
Dado que el cliente es el que tiene la decisión final sobre el producto, la idea es establecer (de forma complementaria a la def. de los requisitos) los criterios de aceptación por los cual se aceptarán los requerimientos.
Los criterios de aceptación no son pruebas funcionales o unitarias, son condiciones que debe cumplir el sistema: Las pruebas son más completas y prueba todos los flujos funcionales, excepciones, etc.
Gestión de requisitos
¡Es el proceso donde ya tengo los requisitos... pero me pueden surgir cambios! Incluso cuando ya estoy construyendo.
Por ello, es esencial mantener una trazabilidad de los requisitos y referencias entre estos. Esto me permite realizar un análisis de impacto ante posibles cambios.
Más allá de la metodología de desarrollo, se recomienda que haya un proceso formal de control de cambios.
Los cambios se dan porque la realidad del sistema cambia (nuevo hardware, nuevas interfaces, prioridades del negocio), existen diferencias entre los requisitos de los stakeholders y puede haber conflictos.
Por lo tanto, es importante tener un plan de gestión de requisitos.
Algunas de los puntos de la gestión de requisitos son:
- Identificación de requisitos: Cada requisito debe ser identificado de modo que pueda referenciarse con otros.
- Proceso de gestión de cambios: Es un conjunto de actividades que evalúan el impacto y costo de los cambios.
- Políticas de trazabilidad: Como registrar relaciones entre los requisitos y el sistema diseñado.
- Soporte de herramientas: Las herramientas que se utilizará n para implementar esto (planillas, software de gestión, etc.).
El proceso de cambio para decidir si un cambio debe aceptarse o no son requiere un análisis previo de especificación (¿el cambio es válido?), calcular los costos de cambiar el análisis (se tiene que evaluar el efecto (trazabilidad y estabilidad del sistema), definir si proceder o no). Si se pasan los chequeos, se implementa el cambio.
}}){kind=link}
Cambios en procesos ágiles.
Cuando un usuario propone un cambio, no se pasa por un proceso formal de gestión. El usuario debe definir la prioridad de dicho cambio y se es de alta prioridad debe decidir qué características quitar de la iteración para dar espacio a implementar dicho cambio. ¿Pero... qué pasa si ya empezamos? ¿Queda para la siguiente iteración? En un sistema con múltiples stakeholders los cambios no benefician necesariamente a todas las partes interesadas. En situaciones complejas puede ser bueno tener una autoridad independiente de los stakeholders que equilibre las necesidades de los mismos (counselling).
Material Complementario
Is the clock an actor?
Una situación bastante usual es la necesidad de modelar procesos que están basados en eventos que suceden cada cierto tiempo de forma automática. Una discusión inicial era poner al tiempo como actor principal. Esto es incorrecto. Hay que buscar la persona que realmente es la que obtienen beneficio de este evento. El tiempo se puede modelar como un actor secundario o con un mecanismo para capturar el tiempo. (El tiempo aparece en la arquitectura del sistema)
Diseño de Software
Principios del diseño de software
El diseño de software es una actividad creativa donde se identifican los componentes del software y sus relaciones, basados en los requisitos del cliente. (Sommerville)
A veces hay una etapa de diseño separada donde se modela y documenta, otras veces el diseño está en la mente del programador y son bosquejos.
Es la respuesta a como resolver un problema, siempre existe el proceso de diseño.
Si quiero hacer un edificio y en seguida comienzo a colocar ladrillos, el resultado no va a ser bueno.
A veces en el software se desprecia el diseño (ahh, esto en 2 horas en Ruby queda pronto)... cuál es el resultado?
Para una empresa, lo más caro es elaborar su software, por ello siempre se trata de reutilizar. Cuando el software se compra, existe una instancia de diseño cuando se configura y se planea como se va a adaptar.
Definición
Proceso de definición de la arquitectura, componentes, interfaces y otras características de un sistema o componente y el resultado de este proceso.
Como proceso, el diseño de software es una actividad del ciclo de vida del software donde se analizan los requisitos para producir una descripción interna del software que servirá como base para su construcción (Es diseñar los planos...)
Como resultado, es describir la arquitectura del software (como está organizado en componentes y sus interfaces). (El plano en sí mismo).
Existen dos actividades clave en el diseño del software:
Diseño arquitectónico (alto nivel): Desarrollar estructura, organización de los componentes a alto nivel.
Diseño detallado de software: Especificación detallada de cada componente para facilitar su construcción.
Sistema Correcto
Se entiende que un sistema es correcto si satisface los requerimientos del sistema. Sin embargo, el objetivo del diseño de software no es encontrar él diseño correcto but rather encontrar el mejor diseño posible dentro de las limitaciones impuestas por: (requerimientos, ambiente físico del sistema, ambiente social donde este opera, etc.).
Un diseño correcto debe tener necesariamente las siguientes características:
- Verificable (Puedo probar que funciona)
- Completo (Implementa todas las specs)
- Rastreable (Puedo encontrar donde se implementa cada requisito)
Sin embargo, también es esencial que el diseño sea eficiente y simple. En sistemas complejos, esto último es muy complejo. Ya que no existe un manual con los pasos a seguir ya que es una actividad creativa. Pero existen guías...
Manejar la complejidad implica una reducción en los costos de diseño y menos probabilidad de introducir defectos en el sistema.
Proceso de diseño de software
Es un proceso creativo. En esencia consiste en:
- Postular una solución
- Construir un modelo de dicha solución.
- Evaluar modelo contra requisitos
- Elaborar modelo para producir especificación detallada de la solución
Principios
Abstracción
Ver un objeto desde un punto de vista particular, ignorando el resto de la información que no importa.
Herramienta fundamental del programador para diseñar componentes olvidándose de las implementaciones.
Acoplamiento
Medida de interdependencia entre módulos. Cuanto más acoplamiento más difícil de entender y modificar los módulos es.
Cohesión
Cuanto más sentido tenga un módulo, más fácil de comprender y modificar
Descomposición y modularization
Se basa en dividir un software grande en mini componentes que tienen interfaces bien definidas y describir las interacciones entre ellas. El objetivo es colocar diferentes funcionalidades y responsabilidades en diferentes componentes.
Un sistema se considera modular si consiste de componentes que se pueden implementar separadamente y un cambio en un componente afecta mínimamente (o idealmente nada) a los demás componentes.
Encapsulation
Empaquetar detalles internos de la abstracción y hacer estos invisibles para entidades externas.
Separar interfaz de implementación
Especificar interfaz publica, después como se implementa es cosa del componente.
Suficiencia, integridad y primitivism
Suficiencia implica que un componente capture todas las características necesarias de la abstracción y nada más (def forma integral). Primitivismo refiere a que el diseño se basa en patrones fáciles de implementar.
Separación de intereses
concentrarse en cada aspecto del sistema de forma separada. Por ejemplo, el tiempo, ciclo de vida , cualidades, eficiencia, etc.
Dividir y conquistar
Clásica técnica para solucionar problemas...
Reutilizar
La reutilización puede ser a varios niveles:
- Abstracción: Se utiliza conocimiento de abstracciones exitosas en el diseño (Design patterns)
- Objeto: Se reutilizan objetos disponibles en lugar de reescribir código
- Componente: Reutilizar colecciones de objetos (librerías)
- Sistema: Reutilizar un software entero.
Existe un costo de pensar el reúso a futuro, suele implicar hacer programas más robustos, sí sé qué lo que hago se reutilizará, tendrá que estar mejor hecho. Los beneficios del reúso son:
- Mayor confianza: Yo sé que esto funciona, esto se usa y fue testeado.
- Reducción del riesgo del proceso: Es más fácil medir el costo del software existente que el que no existe
- Uso eficaz de especialistas: Los especialistas pueden reutilizar componentes y tienen conocimiento de las herramientas que este proporciona
- Conformidad estándares: Los estándares pueden muchas veces implementarse con componentes que ya existen (más fácil)
- Desarrollo acelerado: Es más fácil hacer import numpy que perder el tiempo construyendo funciones matemáticas.
Sin embargo, también existen problemas:
- Aumentan costos de mantenimiento: Si no tengo el código fuente, puede que los elementos reutilizados sean muy incompatibles con los cambios que el sistema requerirá y esto tendrá alto costo.
- "Crear, mantener, usar" vs "Encontrar, comprender, adaptar": Puede ser costoso asegurar que los developers aprendan a usar una librería.
- Síndrome de no inventado aquí: Esa necesidad del programador de reinventar la rueda, de no estar conforme con una función e implementar la suya de cero. Orgullo del desarrollador, pensar que lo puede mejorar.
Aspectos clave del diseño de software
- Concurrencia.
- Manejo de eventos y control.
- Persistencia de datos.
- Distribución de componentes.
- Manejo de excepciones y errores.
- Interacción y presentación.
- Seguridad.
Wicked problems
Se dice que el proceso de diseño de software es un wicked problem.
Se usa este término para referirse a que existe una resistencia a la solución. El problema que trata de resolver es incompleto, contradictorio, cambia con el tiempo y es difícil de reconocer los requisitos cambiantes.
Más aún, encontrar una posible solución al problema genera un cambio en el problema, por lo que al final no lo termino nunca resolviendo. (Creo un software, aparecen nuevas necesidades/problemas).
"A problem whose social complexity means that it has no determinable stopping point"
Algunos puntos claves de esto son:
- No existe formulación definitiva.
- No existe una regla de detención (He aquí he terminado mi trabajo).
- No hay soluciones verdaderas o falsas. Solo buenas o malas (el software es una basura, pero igual sirve.).
- No existe una prueba definitiva de la solución (correr unos tests y si dan OK done.).
- No hay oportunidad de aprender por ensayo y error. Cada solución propuesta cambia el problema.
- No hay un conjunto enumerarle de soluciones.
- Cada problema wicked es en esencia, único.
- Cada problema wicked es síntoma de otro problema. (Esto refiere a que muchos problemas se dan porque hay un problema en otro lado. ¿Por ej., por qué tengo que hacer esto así? Es porque X le gusta así. El problema es síntoma de una necesidad irracional de otro).
Arquitectura de software
Responde a cómo debe organizarse un sistema y como tiene que ser su estructura global. El resultado es un modelo arquitectónico que describa la forma en que se organiza el sistema y su conjunto de componentes.
El desarrollo de las arquitecturas no es incremental (usually). Incluso en los métodos ágiles, el cambio de la arquitectura no se permite. Aquí se define algo llamado sprint 0, donde se define la arquitectura del sistema.
En cierto sentido el proceso de software se asemeja a la construcción de un edificio, cuanto más cerca estamos de terminarlo, más costoso y difícil es este de modificar.
Diseño Arquitectónico
Este concepto responde as como debe organizarse un sistema y diseñarse su estructura global. La salida de este proceso es un modelo arquitectónico que describe en qué forma se organiza el sistema.
Es una etapa temprana del proceso de diseño. Es el link entre la especificación y los procesos de diseño. Aquí se identifican los principales componentes del sistema y sus relaciones.
A veces esto se realiza en paralelo con otras actividades (como requisitos finales, gestión de proyecto, comunicación, etc.)
Diseño de Software
El diseño de software puede dividirse en dos bloques:
Arquitectura en alto nivel: Arquitectura de sistemas complejos que incluyen otros sistemas, programas y componentes.
Arquitectura detallada: Tiene que ver con la arquitectura de los programas individuales. Aquí nos preocupamos de que un programa se descomponga en varios componentes.
Las ventajas de explicitar la arquitectura son varios:
Mejor comunicación con los participantes (se facilita la discusión)
Análisis del sistema superior (se contextualiza los requisitos funcionales y es más fácil negociar requisitos)
Posible software reutilización a gran escala.
Reutilización de Arquitectura
Los sistemas de un mismo dominio (ej. sistemas de facturación), suelen tener arquitecturas similares que responden a la realidad del dominio. Por ello, resulta conveniente relevar si es posible utilizar las soluciones de arquitecturas ya existentes para un dominio del problema.
La arquitectura de un sistema puede ser diseñada en torno a uno o más patrones de arquitectura / estilos. Estos capturan la esencia de la arquitectura y pueden instanciar de diferentes maneras.
Efectos de la arquitectura
El estilo y estructura de la arquitectura dependerán de:
- Seguridad (Toda comunicación bajo cifrado)
- Rendimiento (10ms de respuesta en todas las ops.)
- Protección (Hmm)
- Disponibilidad (disponible 24/7 vs usos puntuales)
- Maintainability (sistema que durará 10 años vs 100)
Es decir, la arquitectura esta fuertemente ligada a los requisitos no funcionales del sistema
Conflictos en soluciones
Si hay varias soluciones en la mesa, ¿que hacer? Hay que buscar compromisos u optar por diferentes estilos para ciertos módulos del sistema.
Nótese que evaluar cual diseño arquitectónico es difícil ya que la prueba real de como cubre sus requisitos solo se puede hacer cuando este ya está construido!!!
Patrones Arquitectónicos
Un patrón es una descripción abstracta de una buena práctica, la cual ya se utilizó exitosamente en instancias anteriores. Un patrón incluye información de cuando aplicarlo, sus fortalezas/debilidades y explicación de cómo aplicarlo.
Las cinco piezas claves de un patrón son: Nombre, Contexto, Problema, Solución y Consecuencias (+/-)
Utilizar patrones permite tener una solución entendible y probada de una parte del problema. Dado que los patrones son "conocidos", es fácil comunicar las características del sistema. (Ej. Con decirte "singleton" estoy transmitiendo un montón de información...)
Formas de usar un patrón
- Aplicarlo como solución al diseño del sistema.
- Basarse en un patrón y adaptarlo (patrón soluciona parcialmente el problema).
- Utilizar un patrón como inspiración para la solución (La solución no utiliza el patrón, pero puede verse su influencia.)
- Basarse en un patrón como motivación para un nuevo patrón (muy pro) (Al abstraer la necesidad especifica y las faltas de los patrones disponibles, desarrollar una solución y abstraerla a un patrón de diseño).
Patrones
Arquitectura en Capas
- Descripción: Funcionalidad agrupada con cada capa, cada capa provee servicios a la de arriba.
- Cuando: Agregar nuevas facilidades a un sistema existente, desarrollo disperso en varios equipos (cada uno resp. de una cpa), requisito de seguridad multilevel.
- Ventajas: Permite sustitución de capas conservando interfaz, aumenta confiabilidad al incluir controles redundantes en cada capa
- Desventajas: Es difícil dar una separación limpia entre capas. Problemas de rendimiento
La arquitectura en capas soporta el desarrollo incremental, y también es buena para implementaciones multiplataforma (capa dependiente de cada plataforma...)
Arquitectura de Repositorio
- Descripción: Todos los datos del sistema se gestionan en un repo central, todos los componentes acceden a este y no interactúan directamente entre sí.
- Cuando: Grandes volúmenes de información, data-driven systems.
- Advantages: Componentes aislados, cambios se propagan a todos los componentes. Gestión centralizada y consistente de datos.
- Disadvantages: Single point failure, inefficiencies en la comunicación, dificultades al distribuir el repositorio.
Existe una variante llamada pizarrón donde los componentes se activan dependiendo de los datos con que se trabaja:
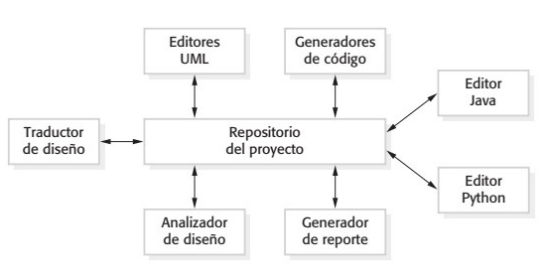
Arquitectura Cliente/Servidor
- Descripción: Funcionalidades basadas en servicio, cada servicio lo atiende un servidor y los clientes los utilizan.
- Cuando: Ingresar a una base de datos compartida desde varas ubicaciones, problemas con carga variable.
- Advantages: Distribuir servidores en una red. No necesita implementarse todos los servicios en un solo servidor.
- Disadvantages: Cada servicio es un punto de falla, el rendimiento también va a depender de red. Problemas administrativos cuando los servidores son propiedad de diferentes organizaciones.
Observación: Si bien uno siempre piensa en un sistema distribuido en la red, todo el modelo lógico puede operar en una sola computadora. (ej. Jupyter notebook). Un beneficio clave es la separación y independencia de cada servicio y la separación entre consumidor y servidor.
Arquitectura Tubería y Filtro
- Descripción: Cada componente recibe un input, lo procesa (filtro) y lo envía a otro componente. Los datos fluyen como una tubería de un componente a otro.
- Cuando: Excelente para aplicaciones basadas en data processing. (Compilador, editor de audio, etc.)
- Advantages: Fácil de entender, reutilizables, coincide con la estructura de flujo del problema. Agregar transformaciones es un proceso discreto, soporta concurrencia.
- Disadvantages: Se debe acordar formatos entre componentes. Diferencias de formatos puede dificultar reutilizar transformaciones (filtros) que utilizan otro formato de datos.
Esta arquitectura es terrible para sistemas interactivos.
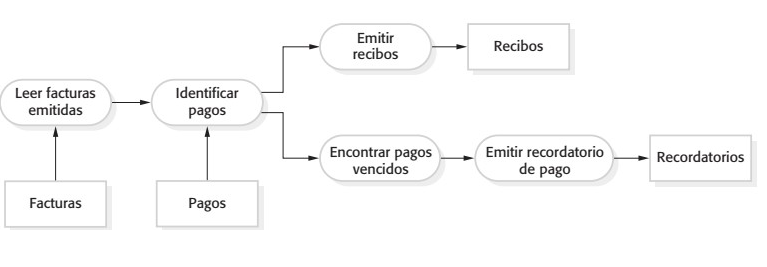
Arquitecturas de Aplicación
Encapsulan las principales características de una clase de sistemas.
El uso de modelos de arquitecturas de aplicación sirve como punto de partida del diseño, es una forma de organizar el trabajo, lista de verificación del diseño, medio para determinar componentes reutilizables y para definir un vocabulario al hablar de ciertos tipos de aplicaciones.
Sistemas de Procesamiento de Transacciones
Procesan peticiones del usuario mediante información o una base de datos. Recordar que una transacción es una secuencia de operaciones que se trata como una sola unidad. i.e la transacción se hace o no se hace.
Estos son sistemas interactivos donde los usuarios hacen peticiones asíncronas de servicios. Pueden organizarse con arquitectura de tubería y filtro.
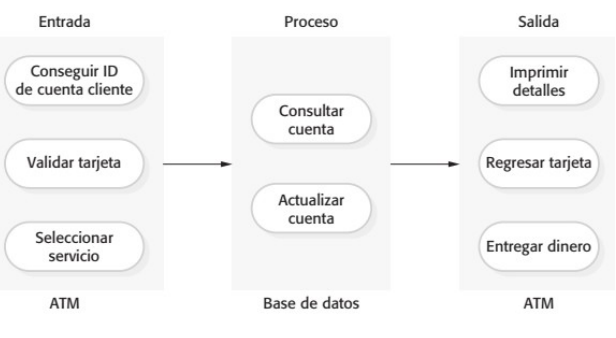
Sistemas de Información
Todo sistema que interactúe con una database se considera un sistema TI.
Permite el acceso controlado a una gran base de información. Existe una tendencia popular a que estos sistemas se basen en Web, con acceso a través del Web Browser. Un modelo clásico de estos sistemas está basado en capas:
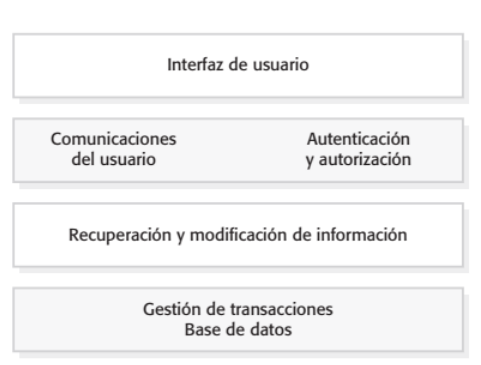
Sistemas de Procesamiento del Lenguaje
Convierten un lenguaje (natural o artificial) en otras representaciones. Ejemplos de esto son compiladores, reconocedores de texto, parsers, etc. Un ejemplo de esto son los compiladores, para estos se utiliza una composición de arquitectura repositorio con tubería y filtro.
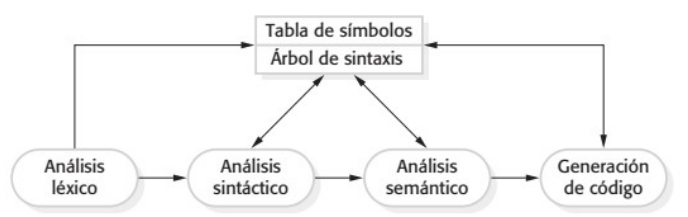
Vistas Arquitectónicas
¿Qué vistas o perspectivas son útiles para diseñar y documentar una arquitectura?
Modelo 4+1
- Vista lógica: Abstracciones clave del sistema (objetos, clases, etc.).
- Vista de proceso: Como interactúan los procesos en tiempo de ejecución
- Vista de desarrollo: Como se descompone el software para desarrollarlo.
- Vista física: Hardware del sistema y como distribuir los componentes de software.
- (+1) Como se relaciona el sistema con los casos de uso/ escenarios.
Las notaciones a utilizar en una vista arquitectónica por lo general son informales (notaciones rápidas/ UML informal).
La idea es que las vistas sean útiles para la comunicación. Sin tener que preocuparse por la completitud (excepto en sistemas críticos).
Para la vista de casos de uso y escenarios podemos utilizar diagrams de caso de uso, para la de proceso: diagramas de actividad o BMPN (Business Process Model and Notation), para la vista lógica diagramas de clase, secuencia y actividad. Para la vista de desarrollo diagrama de componentes y para la vista física un diagrama de despliegue (deploy diagram).
Diagrama de componentes
Un componente encapsula una parte reusable y reemplazable del software. Es como un bloque de construcción. Pueden ser de cualquier tamaño (desde una función hasta un subsistema entero).

Los componentes pueden ofrecer y requerir interfaces para funcionar:
Diagrama de despliegue
Muestra el vínculo entre hardware y software. Cada nodo es una pieza de hardware, dentro de cada nodo se pueden colocar artefactos de software que ejecutan en ese hardware. Cambien se muestra la comunicación entre nodos con líneas e indicando el protocolo de comunicación.
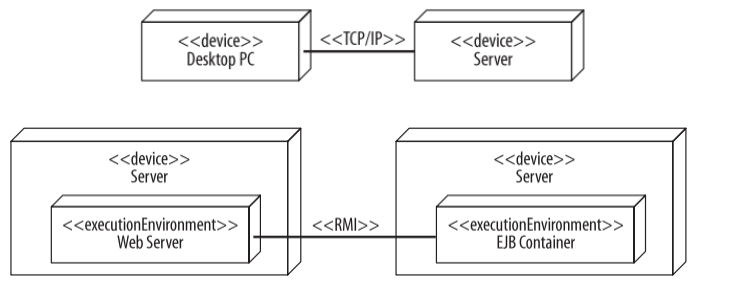
Ingeniería de software basada en componentes (CBSE)
Enfoque para el desarrollo de software basado en la Reutilización de entidades llamadas "software components".
Este enfoque surge del fracaso de OOP (Object oriented programming) para reutilizar clases de forma efectiva: Muchas veces las clases son demasiado detalladas y específicas.
Los componentes son más abstractos que las clases y pueden considerarse proveedores de servicios independientes. Es decir, existen como entidades independientes.
Pilares
Componentes independientes especificados por sus interfaces
Estándares de componentes para facilitar integración.
Existencia de middleware para soportar interoperabilidad de componentes.
Proceso de desarrollo orientado a la reutilización.
Principios de diseño
Los componentes son independientes, no interfieren entre sí.
Las implementaciones de los componentes están ocultas (encapsulamiento)
La comunicación es a través de well defined interfaces
Los componentes pueden ser reemplazables si se mantiene su interface.
Los componentes ofrecen una gamma de servicios estándar.
Sobre los estándares
Si bien la idea de los estándares era que todos los componentes puedan comunicarse entre sí, como todo en la vida aparecieron varios estándares compitiendo entre sí: Enterprise JAVA Beans (EJB), COM, .NET, etc.
La existencia de muchos estándares dificultó la adopción de CBSE, ya que imposibilita que componentes con distintos estándares trabajen juntos.
Ejemplos de componentes: Hibernate de JAVA (espera java beans). Java CFX para implementar SOAP entre componentes, etc.
Ingeniería de Software basada en servicios
Un servicio ejecutable es un componente independiente, tiene una interfaz que "provee" pero no requiere de ninguna interfaz.
Los servicios están basado en estándares para que no haya problemas entre los servicios ofrecidos por distintos proveedores. El rendimiento del sistema puede ser más lento con los servicios, pero reemplaza el enfoque de CBSE. Ver Ch.19
Componentes
Un componente provee un servicio, (no importa en donde se ejecuta o como se programó). Un componente es una unidad ejecutable independiente que puede estar compuesta por uno o más objetos ejecutables.
La interfaz de un componente se publica y todas las interacciones se realizan a través de la interfaz pública.
Las características de esto son: Estandarizado, Independiente (no hay que compilar antes de usar), componible, implementable, documentado.
Un ejemplo: Tener un .exe que hace algún trabajo. Ese .exe es bien conocido, se sabe su interfaz y lo podemos llamar desde otro lado. y es un programa entero!
Interfaces
Los componentes proveen una interfaz (interfaz provista) y tienen una interfaz requerida (la cual son los servicios a los cual el componente tiene que conectarse para su operación correcta).
Acceso a componentes
A los componentes se pueden acceder a través de llamadas a procedimientos remotos (RPC). Cada componente tiene un identificador único (ej. URL) y puede referenciarse por cualquier pc de la red.
Un modelo de componentes es una definición de estándares para implementar, documentar y desplegar componentes. Por ejemplo: EJB (Enterprise Java Beans), COM+ (.NET), COBRA, etc.
Estos modelos especifican como se deben definir las interfaces de los elementos.
Un modelo de componentes entonces tiene los siguientes elementos:
Interfaces: Se especifica como se deben definir las interfaces y los elementos, nombres de operación, parámetros y excepciones.
Uso: Para que los componentes puedan distribuirse, tienen que tener un nombre único o identificador global.
Despliegue: Especificación de como los componentes deben empaquetarse para de su despliegue como unidades ejecutables independientes.
Los modelos de componentes son justamente un ejemplo middleware para soportar el uso de componentes
Una implementación de modelo de componentes debe proporcionar un servicio estilo plataforma que permita la comunicación entre los componentes y proveer servicios de soporte que dichos componentes pueden utilizar. Para utilizar los servicios de una implementación de modelo de componentes, los componentes se encuentran implementados en un contenedor: Conjunto de interfaces para acceder a la implementación del servicio.
Desarrollo para el reúso
La idea central de los componentes es que estos se pueden reutilizar. Si desarrollo un componente especifico, la idea es poder generalizarlo para que sea reutilizable.
Tener en cuenta al reutilizar componentes:
- Reflejar abstracciones de dominio estables (cosas que sé que no van a cambiar el futuro, por lo que puedo reutilizarlas)
- Ocultar representación de estado
- Independencia de componentes
- Publicar exenciones a través de la interfaz del componente
Existe un balance entre reutilización y usabilidad. Cuanto más general una interfaz, mayor reutilizable es, pero es inevitable que se vuelva más compleja y menos utilizable.
Por ejemplo, nadie le interesa una función super genérica que tenga 100 argumentos, el esfuerzo de aprender a utilizarla es mayor al de diseñar una función para el caso.
Cambios para que el componente sea reutilizable
- Eliminar métodos específicos de la aplicación (borrar cosas no genéricas)
- Cambiar nombres y hacerlos genéricos (comprarTaco -> Comprar_comida)
- Manejo de excepciones consistente (Definir un buen modelo de excepciones)
- Agregar una interfaz de configuración para adaptar el componente (mecanismo de configuración permite instanciar un componente más fácilmente)
- Integrar todos los componentes necesarios en un componente grande para reducir dependencias.
- Los sistemas legacy/heredados son buenos candidatos a ser componentes reutilizables, se los empaqueta con un wrapper y quedan prontos para reutilizarse.
Como desarrollar con reúso
CBSE se basa en encontrar e integrar componentes reutilizables.
Es inevitable que sea necesario negociar con el cliente entre los requisitos ideales y los servicios que realmente proporcionan los componentes disponibles. (Por ejemplo, mira cliente, el menú de búsqueda funciona así, espero que sea de tu agrado porque la verdad es que no sabemos cómo modificarlo.)
Esto implica:
- Desarrollo de requisitos de esquema
- Búsqueda de componentes y post modificación de requisitos según la funcionalidad disponible de los componentes
- Búsqueda de nuevos componentes para ver si hay componentes que hagan un mejor fit con los nuevos requisitos revisados
- Componer componentes para crear el sistema final.
Los componentes se pueden componer de tres formas: Secuencial (ejecución de componentes en secuencia), jerárquica (Componente que llama a varios otros componentes) y composición (Dos interfaces de componentes se juntan para formar un nuevo componente).

Los problemas que pueden surgir al componer componentes:
Problemas de adaptabilidad de componentes. La solución a esto es utilizar wrappers.
Para resolver conflictos cuando se componen componentes hay que considerar: Cual es la composición más efectiva que da los req. funcionales del sistema? Que composición es más adaptable cuando los req. cambien? Cuáles serán las prop. del sistema compuesto (rendimiento)?
Es una buena idea aplicar le principio de separación de intereses. Esto es, cada componente tiene un papel claramente definido y los roles de los componentes no se mezclan.
In computer science, separation of concerns (SoC) is a design principle for separating a computer program into distinct sections. Each section addresses a separate concern, a set of information that affects the code of a computer program. A concern can be as general as "the details of the hardware for an application", or as specific as "the name of which class to instantiate". A program that embodies SoC well is called a modular program.
Sistemas Distribuidos
una colección de computadoras independientes que aparece para el usuario como un único sistema coherente. El procesamiento de información se distribuye en varias computadoras en lugar de limitarse a una sola máquina.
Características
- Compartir recursos: Se comparten recursos de hardware y software entre "nodos".
- Apertura: Se pueden utilizar equipos y software de distintos proveedores.
- Concurrencia: Procesamiento concurrente -> Mayor rendimiento
- Escalabilidad: Mayor rendimiento al agregar más recursos
- Tolerancia a fallas: Capacidad de continuar funcionando cuando sucede un error.
Estos sistemas son más complejos que los que se ejecutan en un solo procesador. Esta complejidad surge de manejar varios nodos de forma independiente y la falta de una "autoridad a cargo del sistema".
Aspectos de diseño
Transparencia
¿En que medida el usuario se da cuenta que el sistema es distribuido? Idealmente queremos que sea transparente, pero en la práctica puede haber problemas (ej. problemas en la red), a veces es mejor decirles a los usuarios lo que está sucediendo en realidad (ej. el lobby de Call of Duty, está bueno explicarle al usuario que se perdió conexión con el host).
Apertura
¿El sistema debe seguir protocolos estándar para fácil interoperabilidad o es mejor inventarnos nuestros propios protocolos? Es mejor basarse en estándares aceptados.
Escalabilidad
¿Cómo construyo el sistema para que escale fácilmente? Seguir ofreciendo un servicio de alta calidad al aumentar la demanda. Se pueden tener distintos enfoques de mejora. Cómo agregar más recursos, distribuirlos de forma más eficiente (distribución geográfica de servidores).
Existen dos términos clave:
- Ampliar (Scaling-up): Refiere a mejorar un componente para que soporte más carga
- Escalar (Scale-out): Agregar más componentes al sistema.
Seguridad
¿Como implementar políticas de seguridad? Los sistemas distribuidos tienen muchos más puntos de ataque que un sistema descentralizado, más aún cuando diferentes organizaciones pueden tener control de distintas partes del sistema.
Quality of Service (QoS)
¿Cómo asegurar una calidad de servicio? QoS es la capacidad de entregar sus servicios de manera confiable y con un response time aceptable para los usuarios. Es importante cuando el sistema maneja datos de tiempo crítico como transmisiones en vivo de audio/video.
Gestión de fallas
Cómo detectar/contener y reparar fallas en el sistema? Cuanto más distribuido, mayor la posibilidad de que un componente falle, el sistema debe diseñarse para resistir estas fallas. Si un componente falla se espera que el sistema siga pudiendo entregar sus servicios lo mejor posible.
Modelos de interacción
Existen dos modelos de interacción:
Interacción Procesal: Una computadora llama a un servicio conocido por otra computadora y espera la respuesta. Una implementación de esto es RPC (Remote Procedure Calls), donde las solicitudes se hacen como si fuera un componente local (con ayuda del middleware). En JAVA una implementación de esto es RMI (Remote method invocations). Observar que en este caso el programa se queda esperando la respuesta del servicio el tiempo que sea necesario.
Interacción basada en mensajes: La computadora envía información de lo que requiere a la otra. No hay necesidad de quedarse esperando la respuesta. Los mensajes creados se envían a través de middleware. En este enfoque no es necesario conocer explícitamente a la otra computadora que provee el servicio.
Middleware
Cada componente de un sistema distribuido podría estar implementado en diferentes lenguajes, implementado para diferentes procesadores, tipos de datos y protocolos de comunicación. Necesitamos un software middleware que pueda administrar los componentes y garantice comunicación e intercambio de datos efectivo.
El middleware puede dar un soporte de interacción: Coordinar las interacciones entre los componentes del sistema (No es necesario que los componentes conozcan las ubicaciones físicas de los otros componentes). Y también puede proveer servicios comunes: Servicios que pueden ser utilizados por varios componentes del sistema distribuido proporcionando servicios al usuario de manera consistente.
Patrones Arquitectónicos para Sistemas Distribuidos
Maestro/Esclavo
Es común para sistemas en tiempo real. Un proceso maestro es responsable del "calculo", la coordinación, comunicación y control de los procesos esclavos. Los procesos esclavos están dedicados a realizar acciones específicas.
Cliente/Servidor 2 niveles
Clásico servidor lógico único y cantidad indefinida de clientes. Existen un par de variantes:
- Cliente ligero: La capa de presentación se implementa en el cliente y todo lo demás (datos, procesamiento, database) lo implementa el servidor. Es simple de manejar, fuerte carga en la red y servidor.
- Cliente pesado: El cliente tiene tareas de procesamiento de la aplicación. El servidor se centra en la administración de datos y funciones de acceso a la database. Es adecuado cuando sabemos que habrá grandes cantidades de clientes, gestión tres facile, a veces requiere instalar software en los clientes. Javascript ha hecho esta frontera entre cliente pesado y liviano borrosa.
Cliente/Servidor multilevel
Las diferentes capas del sistema (presentación, data administración, procesamiento, base de datos) son procesos separados ejecutados en diferentes procesadores. Arquitectura super escalable y útil cuando hay varias bases de datos. El procesamiento se distribuye entre los servidores de gestión de datos y los de la lógica de la aplicación (fast response).
Componentes distribuidos
No existe distinción entre cliente y servidor. Cada entidad es un componente que ofrece sus servicios a otros componentes y recibe el servicio de otros. Se precisa un sistema de middleware para la comunicación entre componentes.
Esta cool esto porque permite al diseñador retrasar decisiones de donde y como se deben proporcionar los servicios, es una arquitectura muy abierta que permite agregar nuevos recursos, flexible y escalable. Es posible reconfigurar el sistema de forma dinamice si es necesario.
Lo malo es que son más complejos de diseñar, no hay un middleware estandarizado.
Las arquitecturas orientadas a servicios están reemplazando este tipo de arquitecturas hoy en día.
Entre Pares (Peer to Peer p2p)
Sistemas descentralizados donde el cálculo lo realiza cualquier nodo de la red. Está pensado para aprovechar la capacidad de cómputo y almacenamiento de muchos nodos en una red. La mayoría de estos sistemas son personales, pero existen usos comerciales. Está bueno cuando el cómputo es intensivo y es posible distribuir el procesamiento de la información sin necesidad de que haya necesitad de gestionarla de forma centralizada.
Existen variantes totalmente descentralizadas (todos peers, mucha redundancia y robustez) o semi descentralizadas (existen unos servidores que todos se conectan, reduce la carga de la red).
Software as a Service (SaaS)
Implica alojar el software de manera remota y proveer acceso a él a través de internet.
Compiler online on Github under lock and key.
El software es propiedad y es administrado directamente por el proveedor y no por los clientes que lo utilizan. Permite modelos de negocio como pagar por el software de acuerdo a la cantidad de uso o sistemas de suscripciones mensuales.
El servidor conserva los datos y el estado del usuario durante una larga sesión de interacción. La concepción ideal es que el usuario, con el navegador, utilice el software de igual manera de como lo utilizaría si lo tuviese instalado, pero sin ninguna de las libertades que lo anterior conlleva.
Service Oriented Architecture
SOA es un enfoque de estructuración de sistemas de software como un set de servicios independientes, stateless. Estos lo pueden proporcionar múltiples proveedores y estar distribuidos. Las transacciones entre estos son cortas. En este sentido, SaaS es una forma de entregar funcionalidad a los usuarios mientras que SOA es una tecnología de implementación para sistemas de aplicación (es lo que hay de fondo).
Construcción
Refiere a programar. Es una combinación de codificación, verificación, pruebas unitarias, pruebas de integración, y debugging.
Los fundamentos de la construcción de software son:
Minimizar complejidad: El software lo tienen que entender las personas, la complejidad es algo crítico al momento de hacer las pruebas. Para minimizar la complejidad se debe escribir código simple y legible en lugar de inteligente (the absolute state), utilizar estándares y ser modular.
Anticipar el cambio
Construcción para verificación: Permite encontrar fallas de forma más fácil (escribir pensando en los tests).
Reúso: Construir pensando en reutilizar lo que tengo y generar cosas que sean reutilizables. Existen varios niveles de reutilización: (abstracción/objeto/componente/sistema).
Gestión de la construcción
Lo que se le llama construcción depende del modelo de ciclo de vida de software a utilizar. Existen muchos métodos de construcción que definen el orden en el cual se crean componentes, se integran y se gestiona el trabajo de los recursos humanos (developers).
Consideraciones Generales
El diseño muchas veces puede verse afectado en la etapa de construcción. Se ve un problema en los planos y se hace distinto. Dependiendo de la realidad organizacional se deben crear nuevos planos que reflejen la realidad o dejarlo así. Nunca es recomendado seguir un diseño si se sabe que está mal simplemente por el hecho de que la etapa de diseño del componente ya fue concluida.
Existen múltiples lenguajes para la construcción de software, desde configuración (yaml), programación, notaciones lingüísticas y notaciones formales. Todo esto se utiliza para transmitir ideas del código y construcción a generar.
En el libro le llaman codificar a programar. Una triste traducción del verbo coding en inglés. When coding, se debe considerar:
- Técnicas para crear código fuente, plantillas, convenciones, etc.
- Utilizar clases, enums, variables, etc.
- Uso de estructuras de control (como trabajar con ellas)
- Manejo de excepciones (return -1 o throw ExceptionClassNotFound?)
- Prevención de rupturas de seguridad a nivel de código (¿Acceso fuera de memoria?)
- Como manejar recursos compartidos (semáforos)
- Organizar código (estructura de carpetas)
- Documentar código
- Puesta a punto del código (aka tuning)
Durante la codificación, se sugiere hacer pruebas unitarias y de integración para reducir la brecha temporal entre que se introduce un bug y su posterior detección.
Al construir con reúso y para el reúso se debe pensar como generalizar las estructuras de código con que se está trabajando y el trade-off que esto implica.
Para asegurar una buena calidad en la construcción se deben hacer pruebas unitarias y de integración, el desarrollo debe estar asistido por estas pruebas. También se pueden aplicar tácticas de programación defensiva y el uso de asserts. Inspeccionar el código, someterlo a revisiones técnicas y hacerle un análisis estático (ver que compile) son prácticas, algunas más costosas que otras, que aseguran la calidad del código.
Al integrar el código puedo tratar de juntar todo de una (Big Bang) o ir de a poquito (incremental). Lo último es casi siempre el approach sugerido.
Tecnologías de Construcción
Las tecnologías de construcción refieren a todas las features y abstracciones que nos provee los lenguajes de programación.
Las APIs con las interfaces son una estructura esencial para la programación.
Cuestiones de Orientación a objetos como polimorfismo y reflections (capacidad de modificar/observar su propia estructura de objetos en tiempo de ejecución) permiten llevar ciertas estrategias de programación que son dependientes de estas tecnologías (patrones de diseño).
Los tipos genéricos (definir una clase sin definir los types que utiliza) son otro clásico.
En los sistemas más densos en las clases se implementan aserciones (assert()), diseño por contrato (tener pre y pos condiciones en cada operación) y programación defensiva (comportamiento definido para todos los inputs).
La manera en que un programa maneja los errores afecta su correctitud y robustez. Existen diversas formas de manejar esto: asserts, return 0, logging errors, retornar error codes, shutdown el programa, etc.
Las excepciones son una abstracción para manejar errores o eventos excepcionales: Estructura throw/try-catch. Esto permite realizar programas con tolerancias a fallas: detección y recuperación en caso de errores.
También existen técnicas de construcción basadas en estados (programar pensando en un máquina de estados) o por tablas (se busca para donde ir según una tabla en vez de andar con secuencias if-else).
Existen aspectos de configuración en tiempo de ejecución utilizando archivos de configuración (runtime configuration). También existen técnicas de internacionalización (preparar técnicamente un programa para multiples sitios dependiendo de su geografía). Existen técnicas para cambiar el idioma del programa y que desarrollar esta feature no sea un problema.
Hoy en día también se implementan tecnologías de construcción basadas en las gramáticas, se analiza sintácticamente una entrada y se la traduce a una orden de código. (Ej, hey Siri).
En caso de sistemas multi-hilados se deben utilizar primitivas de concurrencia (semáforos, monitores y mutex).
En el caso de sistemas distribuidos se deben atender cuestiones de paralelismo, comunicación y tolerancia a falla.
En los sistemas heterogéneo (variedad de unidades computaciones especializadas independientes) swe plantean cuestiones del lenguaje a utilizar y aspectos de comunicación.
Finalmente, también existe una etapa de análisis de desempeño (performance) y puesta a punto (tuning). La primera refiere al estudio del programa durante su ejecución, la segunda involucra realizar cambios menores para justar el desempeño del programa con la información obtenida en el análisis de desempeño.
También existen estándares de plataforma, esto permite desarrollar aplicaciones portables que pueden ser ejecutadas en entornos compatibles sin hacer cambios. Por ejemplo, J2EE o los WAR para tomcat.
Test Driven Development refiere al estilo de programación en el cual se escriben pruebas antes que el código mismo del programa.
Middleware
En el contexto de construcción, se entiende al middleware como todo software que provea servicio sobre la capa del sistema operativo y por debajo de la capa de aplicación. Puede proveer contenedores en tiempo de ejecución para los componentes del sistema y proveer un pasaje de mensajes, persistencia y alocación en la red. El middleware moderno orientado a mensajes provee un Enterprise Service Bus (ESB) que sirve para la interacción orientada a servicios.
Cloud Computing
Refiere al nuevo paradigma de ofrecer servicios de computación sur internet. Los dos ejes centrales de este servicio son SaaS y PaaS (Platform as a Service). Este último refiere a la encapsulación de un ambiente de desarrollo y empaquetamiento de módulos o complementos que dan funcionalidades al entorno (persistencia, autenticación, mensajería, etc.) Ej: Microsoft Azure, Amazon EC2, etc. Existen modelos de servicio donde se ofrece un entono de desarrollo y control de la aplicación, en otros no se tiene casi ningún control. Existen modelos PaaS públicos, privados e híbridos.
Otro modelo de negocio es el de Infraestructura as a Service (IaaS) también llamado Hardware as a Service (HaaS), es básicamente alquilar servicios de cómputo por la red. Ejemplo: Amazon Web Services.
El uso de cloud computing conlleva varias ventajas y desventajas en los sistemas y proceso de desarrollo.
Modelos ejecutables
Refiere a esa idea que tiene la gente de se puede tener un modelo de diseño (UML) y este se puede desplegar y ejecutar en varios entornos sin realizar ningún cambio. Idea que no funciona. Ejemplo de estos internos son: xUML, Model-driven architecture y BPMN (Business process Model and Notation)
Herramientas de Construcción
Entornos de Desarrollo (IDE): La elección de un IDE puede afectar la eficiencia y calidad de la construcción del software
GUI Builders. Son herramientas que permiten el mantenimiento y desarrollo de GUIs, es general son de un estilo WYSIWTYG (What you see is what you get), a lo microsoft Word.
Herramientas de pruebas unitarias: Permite automatizar pruebas: Ejemplo JUnit.
Flow
El flujo es un estado donde se encuentra el programador, es un momento de concentración e iluminación, donde estamos totalmente enfrascados con el problema, concentración máxima y pensamiento iluminado.
No todos los roles de trabajo requieren un estado de flujo para ser productivo (code-monkey), pero cualquier tarea de ingeniería como diseño desarrollo o redacción requiere un cierto estado de flujo para que el trabajo vaya bien.
Se requiere unos 15 minutos para entrar en este estado, cuando estamos en el flujo uno es sensible al ruido e interrupción. Por lo que en un entorno disruptivo es imposible alcanzar el flujo.
Estándares de programación
Son buenas prácticas para escribir código fuente en un lenguaje de programación. Dependen fuertemente del lenguaje que se utilice. su esencia se basa en que el software se desarrolla en equipos, por lo que se precisa un marco de entendimiento. Ayuda a la maintainability del software priorizando su legibilidad.
Ejemplo de esto es la selección de nomenclatura para constantes, variables, data-types, funciones, etc.
Otro caso más polémico es el de como indentar el código. Utilizar un único estilo en toda la codebase.
Otras convenciones pueden ser el manejo de mensajes de error/excepciones. Como aplicar estructuras de control (no más de 4 for anidados), como acceder a la database, diseño de menus, comentarios de código (es una buena práctica al escribir el comentario poner el autor y la fecha), espacios y tabuladores en el código fuente, operaciones de bloqueo, criterios de timeout, etc.
Reutilización de código
Reutilizar código en parte es un problema de la administración de conocimiento de una organización. Se debe tener un repositorio de conocimiento donde alojar el código producido para su futura reutilización. En este contexto existen productores de conocimiento y consumidores de dicho conocimiento (identifican lo que puede servir y evalúan si sirve).
Documentación de código
La documentación del código puede ser interna (inline comments) o externa. Esto último refiere a toda la documentación técnica del código, javaDocs, how-to, manuales, etc.
La documentación interna es fundamental para le mantenimiento.
Pair programming
Es la práctica de trabajar de a dos programadores. Uno es el conductor (el que escribe) y el otro es el copiloto (revisa y sugiere). Su éxito depende de la sinergia del par. Es cuestionable si afecta de forma positiva o negativa la productividad. En general estudios han mostrado que para programadores experimentados esta técnica es útil únicamente para partes críticas de un problema o hay restricciones importantes de tiempo.
Debug
Se debe tratar de poder reproducir un bug. Buscar un punto donde el sistema estaba bien y ver cuando empezaba a fallar. Para detectar los bugs unos prints siempre vienen bien. (Pero hoy en dia se recomienda usar aserciones o herramientas del IDE).
Buscar bugs complejos requiere a veces hacer búsqueda binaria (dividir a la mitad y ver en cual parte está el bug). A este problema se le llama a veces arqueología del software.
Los bugs más complicados son los no reproducibles. En estos casos se recomienda llevar un registro del bug, contexto y consecuencias. ¡Si en el futuro vuelven a aparecer problemas quizás se logren unir cabos sueltos para encontrar el bug! Si un problema es grave se debe tratar de tener un ambiente lo más parecido posible para reproducir el problema. (Por ejemplo, pedirle al cliente una copia anónima de la base de datos para ver cómo se comporta el sistema con ella).
Verificación y Validación
Errores, faltas, defectos y fallas. ¡Son todas cosas distintas!
Aspectos Generales
Un error es una equivocación humana durante el relevamiento de requisitos, programación ,etc. Dicha interacción puede provocar una falta o defecto del sistema el cual genera una falla del sistema (se ve el efecto externo). (Se supone que viene del software, las condiciones del hardware son las correctas).

Fallas de Software
El software falla respecto a una especificación.
Es decir, el software falla cuando no hace lo requerido o no hace lo que el cliente esperaba que haga. También puede ser que el requisito no se haya podido implementar, defectos de diseño e incluso de código.
Terminología
Testing: (Probar). Distinto a debugging. Refiere a ejecutar el código. Revisar el comportamiento del software.
Debugging (Debuggear). Distinto a testing. Refiere a la actividad de localizar defectos en el código.
Objetivo de prueba
Tipo de prueba: Propósito de la prueba (load test)
Técnica de prueba: Nombre de la técnica utilizada para ejecutar el test.
Objeto de prueba: Sobre que se va a hacer la prueba (una GUI, una base de datos, etc.). El nombre suele incluir al objeto.
Nivel de prueba: Sobre qué nivel es el test, a nivel de componente, función, módulo, sistema, etc.
Perfil de persona que prueba: Quien ejecuta las pruebas (desarrollador, usuarios)
Grado de prueba: El nivel de profundización de la prueba (full regresión, partial, etc.) Que tantos caminos y cobertura se realizan.
Bases de prueba: Aquello en lo que yo me baso como documentación para construir el caso de prueba.
Caso de prueba: El test en sí. Tiene un objetivo, datos de prueba, objeto de prueba.
Objetivos de V&V
- Ejecutar el programa para provocar fallas (encontrar defectos).
- Ejecutar el programa para medir su calidad.
- Ejecutar el programa para generar confianza. (Esto refiere a una métrica que se llama fallas/tiempo. Si no hay fallas en 1 semana de ejecución entonces podría decirse si el software es confiable). Existen programas que ejecutan una batería de parámetros con una base de datos y template de ejecución para generar pruebas automatizadas para simular el uso del software.
- Analizar/Revisar el programa para detectar defectos (y prevenir fallas)
VvsV
Pero cual es la diferencia entre verificación y validación?
Verificación responde a la pregunta: Estamos construyendo el producto correctamente? Aquí se busca comprobar que el sistema cumple con sus requisitos, se sigue la especificación? El testing busca defectos.
Validación responde a la pregunta: Estamos construyendo el producto correcto? Busca comprobar que el software hace lo que el usuario espera. ¿Cumple las expectativas del cliente? Se realizan testings de validación.
Principios del testing
El testing muestra la presencia de defectos, no la ausencia de ellos.
- El testing exhaustivo no es posible (dominio infinito).
- Las actividades de verificación y validación deberían comenzar lo antes posible. (Cuanto más temprano, menos costo) -Agrupamiento de defectos (defect clustering). Defect clustering means a small number of modules containing most of the defects. Basically, the defects are not distributed uniformly across the entire application, rather defects are concentrated or centralized across two or three functionalities. Por lo tanto, muchas veces aquí es mejor hacer refactoring (o incluso reimplementar que tratar de ir emparchando).
- La paradoja del pesticida: El testing se empieza a oxidar si siempre hago lo mismo. Porque los programadores van a tender a generar código sin las fallas que se verifican, y al cambiar su comportamiento van a generar fallas de otro tipo
- El testing depende del contexto. Works on My Machine
- Decir que el software es útil porque "no hay fallas" es una falacia. ¡No! La utilidad del software viene dada por el usuario y otros atributos de calidad.
Tiene sentido hacer el testing de este módulo cuando yo sé que lo voy a probar con todas estas X demás funcionalidades?
Clasificación de defectos
Los defectos se pueden categorizar y registrar. Sirve como guía para orientar la verificación y mejorar el proceso de desarrollo (si conozco que fase genera muchos defectos, puedo enfocarme en mejorarla.). Existen clasificaciones ortogonales: Tipo de defecto, fuente, impacto, disparador, severidad y criticidad.
Las clasificaciones de defectos se basan en el tipo de falla que provoca un defecto y en los errores humanos que generan defectos.
Verificación y validación en el ciclo de vida del Software
Niveles de prueba
Las pruebas de software se pueden separar en distintos niveles de abstracción
- De módulo/componente/unitaria: Verifica el funcionamiento de los componentes según su especificación.
- De integración: Verifica la interacción entre grupos de componentes. Si f(x) funciona y f(y) también, no tiene por qué funcionar f(x+y).
- De sistema: Se verifica el sistema integrado como un todo, se determina si cumple con los requisitos especificados.
- De aceptación: Verifica que el sistema cumple con los requisitos del cliente de acuerdo a como fueron especificados en el contrato y si el software cumple con las expectativas y necesidades del cliente. La aceptación es el OK del cliente sobre el producto final, la prueba de sistema es más sobre el aspecto técnico de si el sistema funciona de forma integral.
Quien verifica el software
Depende del nivel de prueba, del proceso y del equipo. Normalmente, las pruebas unitarias las realiza el mismo equipo de desarrollo, ya que es bueno tener una relación íntima con el módulo a testear. Ídem para las pruebas de integración, las cuales se necesita conocer las interfaces de los módulos.
Las pruebas de sistema y aceptación son usualmente llevadas a cabo por un equipo especializado (verificadores y testers), los cuales tienen una visión más global del sistema y conocen los requerimientos de este a nivel contractual.
Un equipo especializado para la verificación tiene un impacto muy positivo en este proceso. Estos equipos manejan mejor las técnicas de prueba, tienen una holística de los errores más comunes que realiza el dev. team, saben del modelo de negocio. A su vez, es la solución al problema de la psicología de pruebas, dado que la solución viene del pensamiento, muchas veces si uno mismo hace las pruebas se van a estar cometiendo los mismos errores que no permiten verificar todos los aspectos del módulo. Además existe un interés inconsciente de que el programa esté en un principio libre de errores y pase todas las pruebas.
Pruebas de componentes (unitaria)
Terminología
- Objetos de prueba: Clases, módulos, scripts, etc.
- Entorno de prueba: "Escritorio del programador", donde se está desarrollando el software
- Objetivos de prueba: Comprobar que toda funcionalidad del objeto a probar es completa, tanto funcional como no funcionalmente según su especificación. Se prueba la robustez de componentes (tests negativos), eficiencia (uso de recursos), mantenibilidad (modularidad, estándares, etc.), etc.
Un entorno de prueba puede comprender todos los ítems de desarrollo (librerías, dependencias, etc.), datos específicos, programas, clientes u otros nodos físicos que participan en la prueba, el estado en el cual se encuentra el sistema (ej. env variables), tipos de dispositivos (modelo, marca), sistema operativo, etc. No comprende especificación de componentes de código!
Prueba negativa: La mayoría de las pruebas son positivas, estas consisten en seguir el flujo esperado para realizar un CU. Se hacen los pasos que el cliente habitual hará y se compara los resultados con la salida/comportamiento esperado. En cambio, las pruebas negativas consisten en aplicar la mayor creatividad posible para validar la aplicación contra datos inválidos, así poder verificar como el sistema maneja los errores o si existen fallas en el manejo de datos en la aplicación. Source
Estrategias de prueba
- Pruebas estáticas (analíticas): se analiza el programa para deducir su correcta operación (leer el código)
- Técnicas dinámicas: experimentar el comportamiento de un producto para ver si este actúa como se espera. - White box testing: Se basa en el código fuente del programa, el cual es en el que se basan los casos de prueba - Black box testing: Se basa únicamente en la especificación del programa.
¡Las técnicas test-first development utilizan técnicas de caja negra para realizar las pruebas, sería imposible realizar pruebas caja blanca sí que antes exista código!
Stubs and Drivers
Los stubs y drivers son esenciales para reducir el delay que hay entre implementar y testear el resultado. Los stubs se usan en top-down integration mientras que los drivers en bottom-up.
La diferencia clave es que un driver es un programa que llama al programa que quiero testear. Por ejemplo, un programa que calcula un área, un driver es un programa que utiliza el anterior para verificar que está correcto. Invoca al componente que se quiere testear.
Por otra parte, los stubs son módulos que precisamos para poder testear el software, pero aún no se han implementado.
Por ejemplo, para el módulo B:
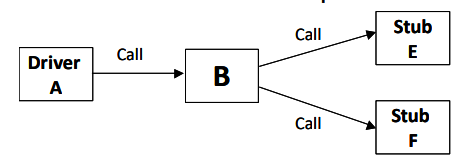
Un stub reúne ciertos parámetros de entrada y salida iguales al módulo faltante, pero con simplificación de comportamiento (realizarlo tiene un coste de todas formas). Si un stub devuelve siempre los mismos valores entonces este no permite hacer un testing adecuado. El stub puede producir resultados leyendo de un archivo, un tester humano, no hacer nada, o cubrir parcialmente un dominio de salida.
Por otra parte, un driver es una pieza que simula el uso de un módulo a testear. Este es más barato que hacer un stub. El driver puede ser quien lee del sistema archivos y datos para dárselo al módulo. Es quien suministra los casos de prueba.
Pruebas de integración
En este segundo nivel de pruebas, el objeto de prueba será un set de clases, módulos, scripts, etc. El entorno de estas pruebas sigue siendo el escritorio del programador, y los drivers y stubs ya desarrollados en las pruebas anteriores. El objetivo de estas pruebas es revelar problemas en la interfaz y ver conflictos entre los componentes integrados.
In most organizations, component integration testing is the responsibility of the developer. However, in organizations that have implemented test-driven development, testers may be involved
Omitir estas pruebas puede traer problemas graves en el diagnostico de problemas en pruebas futuras.
Las pruebas de integración se deben realizar en un orden y frecuencia definidas. El responsable del testing debe elegir una estrategia de pruebas de integración que optimize el tiempo que las pruebas insumen y el coste de mantener este entorno de pruebas.
Las pruebas de integración pueden ser juntar todo al final y ver que funciona todo (también conocida como big bang). O pueden ser pruebas incrementales: Bottom-up (ascendente), va de los módulos más simples a los más complejos; Top-down (descendiente), va de los sets más complejos hasta llegar a los componentes; Por disponibilidad (Ad hoc): Se integran en pruebas a medida que van quedando disponibles e integración backbone (esqueleto), donde se tiene un conjunto de módulos fundamental (backbone) que es sujeto a tests antes, si el backbone está pronto se puede testear con tranquilidad los módulos periféricos.
Big Bang: Se prueba cada módulo de forma aislada y luego se prueba la combinación de todos los módulos a la vez. Lo único bueno es que es muy paralelizable, lo malo es que se precisan stubs y drivers para cada uno de los módulos a ser testeados, es difícil ver el origen de la falla ya que se integraron todos los módulos a la vez, es complicado integrar pocos módulos, los defectos de interfaces no se distinguen fácilmente. Es muy mala idea para sistemas grandes.
Bottom-up: Comienza por los módulos que no requieren de ningún otro para ejecutar (las raíces), va de abajo hacia arriba. Por lo que requiere de drivers pero no de stubs. Es importante la planificación para que los módulos de jerarquías inferiores estén lo más pronto posible. Es fácil crear las condiciones de pruebas, y como no se requieren stubs estas tienen menos costos. Lo malo es que el programa no existe como tal hasta no haber agregado el ultimo módulo.
Top-down: Comienza por el módulo superior de la jerarquía y va hacia abajo. Precisa stubs pero no de drivers. Resulta fácil la representación de casos de prueba ya que los componentes altos suelen ser GUI, permite demostrar de forma temprana el producto. El problema es que los stubs quedan bastante complejos, y las condiciones para hacer la prueba pueden ser muy difíciles de lograr.
La mejor estrategia de pruebas está sujeta a consideraciones como restricciones de arquitectura, plan de proyecto y plan de pruebas. La mejor estrategia puede ser un mix de varias alternativas según aspectos de riesgo, costo, disponibilidad, etc.
Pruebas de sistema
En este tercer nivel de prueba se busca comprobar que el sistema cumple con los requisitos especificados. El objeto de prueba es el sistema integrado como un todo, el entorno de prueba se busca que sea el más cercano posible al de producción (es un error utilizar el mismo ambiente de desarrollo) y el objetivo de la prueba es validar que el sistema completo cumple con la especificación de sus requisitos.
Para estas pruebas se utiliza el documento de requisitos del sistema.
Pruebas de Aceptación
Cuarto nivel de prueba. Aquí se comprueba que el sistema es adecuado y cumple las necesidades del cliente. El objeto de prueba es el sistema, pero a los ojos del cliente, el entorno de prueba es el de producción y los objetivos es validar que se construyó el producto correcto. Las bases de la prueba es cualquier documento construido que describa al sistema desde el punto de vista usuario/cliente: Casos de uso, historias de usuario, procesos de negocio, etc.
Acceptance Testing is carried out in a separate testing environment. No necesariamente tiene que ser el entorno de producción, pero tiene que asemejarse lo más posible a este.
Existen varios tipos de pruebas de aceptación:
- Pruebas de aceptación contractuales: El cliente verifica, en su entorno, el correcto cumplimiento de todos los requisitos definidos en el contrato y criterios de aceptación. También se estudia conformidad de estándares, regulaciones si aplica.
- Pruebas de aceptación de usuario: Aceptación del usuario del software (importante si el cliente y usuario difieren). Permite ver si el usuario está conforme con el software, más allá de si funcionalmente el software cumple.
- Pruebas de aceptación operacionales: Es la aprobación del software por los sysadmins. Estos aprueban de que el sistema cuenta con los mecanismos apropiados de backup/restore, recuperación, manejo de usuario y chequeo de vulnerabilidades que estos crean necesario.
- Pruebas de campo (alpha/beta testing y dog-food tests): Se prueba el software en distintos ambientes. Se distribuye el software a muchos clientes y estos corren pruebas definidas en sus ambientes, proporcionando feedback y comentarios. Esto de testear con versiones preliminares junto a una muestra representativa de los clientes se le llama alpha testing y beta testing. Alpha es cuando el testing se realiza junto al desarrollador (en el mismo lugar), y beta cuando se realiza en la ubicación del cliente. Otro termino que se usa es el de dog-food, este refiere a que el producto se distribuya previamente entre los usuarios internos de la compañía para que lo prueben. La idea es: "if you make dog-food, try it yourself first".
The objective of the field test is to identify influences from users’ environments that are not entirely known or specified and to eliminate them if necessary. If the system is intended for the general market (a COTS system), this test is especially recommended
Una vez que se pasan estas pruebas, se pasa a la fase evolución del ciclo de vida del software. Luego de instalada la versión 1.0 esta puede ir cambiando con el transcurso del tiempo, agregando y actualizando funcionalidades. El mantenimiento puede ser correctivo, adaptativo o evolutivo.
En cada fase de los procesos incrementales se deben hacer pruebas de regresión para verificar que los cambios introducidos no hayan degradado (roto) el funcionamiento del sistema:
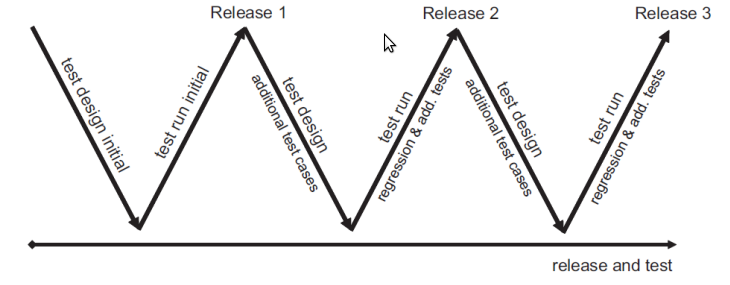
En los equipos ágiles, los integrantes del equipo realizan pruebas de múltiples niveles
Tipos de pruebas y técnicas de generación de casos de prueba
- Pruebas funcionales: Verifican la entrada/salida del sistema. Las técnicas black box son las más usadas.
- Pruebas no funcionales: verifican en que grado se cumplen los requisitos no funcionales. Se pueden usar pruebas funcionales para crear un escenario donde la característica no-funcional del software puede ser medida de forma efectiva.
- Pruebas de estructura del software: Se basan en cómo están hechos los artefactos (código, requisitos, arquitectura). Se usan white-box testing.
- Pruebas relacionadas a los cambios: Por ejemplo, las pruebas de regresión. Verificar las faltas introducidas o enmascaradas al realizar cambios.
Las técnicas de verificación pueden dividirse en técnicas de análisis estático: Analizar el producto para su correcta operación (ver el código) y pruebas dinámicas, donde se estudia el comportamiento del producto (caja negra/blanca, técnicas basadas en la experiencia).
Pruebas estáticas
En el análisis de código se revisa el código buscando de efectos, esta actividad se puede hacer en grupo, realizando varias recorridas e inspecciones. En el análisis estático se analiza el código fuente del programa y se buscan defectos, esto es lo que hace de forma automática el compilador... antes de compilar hace todos los chequeos.
El termino revisión implica que el análisis estático lo realiza un humano. Por ejemplo, las recorridas e inspecciones. Donde el objetivo es criticar el producto (¡no el desarrollador que lo hizo!) para resaltar sus defectos. Estas inspecciones están buenas porque permiten remover los defectos de forma temprana y es una instancia de aprendizaje mutuo para los desarrolladores ya que mejora el estilo de programación para los productos futuros.
En las revisiones hay varios roles que toman los integrantes del equipo:
- Líder (manager): Selecciona los artefactos a revisar, asigna los recursos y el equipo a cada artefacto.
- Moderador: Es el que organiza la discusión de resultados y ejecuta cada revisión.
- Autor: Presenta y explica el código.
- Revisor: Experto técnico que participa en la revisión
- Secretario: Hace un reporte de la reunión, recopila problemas y decisiones que fueron tomadas en la reunión.
Es interesante señalar que la inspección reduce un 67% de las faltas detectadas en el software. Un software que fue sometido a inspección tiene 38% menos fallas en los primeros 7 meses de producción. El 93% de las faltas en procesos de negocio se detectan en inspecciones (Ackermann).
Tipos de revisiones
Se revisan los productos generados a partir del proceso de desarrollo. También se puede revisar el proyecto o proceso de desarrollo en sí mismo. A esto se le llama management reviews. Existen varios tipos de revisiones de productos
Recorridas (walkthroughs)
Método informal y manual. Consiste en descubrir defectos, problemas y ambigüedades en el software. E indirectamente, educar a la audiencia sobre el producto, aprendizaje mutuo y discutir alternativas de implementación. En esta prueba se recorre el producto, simulando su comportamiento, en busca de defectos.
Es bastante informal en comparación con las siguientes revisiones.
Inspecciones (inspections)
Es uno de los métodos más formales de revisión, proceso formal y descriptivo. El objetivo es encontrar defectos e impresiones, midiendo la calidad del objeto bajo revisión y mejorar la calidad del proceso de inspección y desarrollo del software.
Se examinan artefactos en busca de defectos comunes.
Los revisores cuentan con checklists (dependientes del lenguaje y organización) para verificar que se realizaron todas las pruebas apropiadas.
Revisiones técnicas (technical reviews)
Revisiones informales (Informal reviews)
Análisis estático
Al igual que las revisiones, el objetivo es encontrar defecto o partes propensas a defectos en los documentos. La diferencia es que la revisión la va a realizar una herramienta. Por ejemplo, los compiladores cuentan con funciones de análisis estático previo y sugerencias. Para esto el documento debe seguir una cierta estructura formal.
Pruebas dinámicas
Las pruebas dinámicas el sistema se encuentra en ejecución. Existen 3 categorías: Caja negra, caja blanca y basadas en la experiencia. La siguiente imagen muestra la diferencia entre las cajas.
Técnicas de caja negra
En las técnicas de black box la estructura/diseño del objeto de prueba no se considera. Algunas de estas técnicas son:
- Particiones en clases de equivalencia
- Análisis de valores límite
- Pruebas de transacción de estados
- Pruebas basadas en lógica (grafos causa/efecto, tablas de decisión, etc.)
- Pruebas basadas en casos de uso.
Particiones en clases de equivalencia
Una clase de equivalencia es un set de entradas que comparten la misma salida. Los casos de prueba deben cubrir un conjunto extensión de las particiones. Para identificar las clases de equivalencia se separan condiciones entre grupos.
Valores límite
Los casos de prueba que exploraran las condiciones límite son los más útiles. Son los "márgenes de las clases de equivalencia. Es esencial utilizar el ingenio para encontrar las condiciones límite en cada caso.
Pruebas basadas en CU.
Son las que se estudiaron en el obligatorio. Para cada caso de uso generar un grafo con todos los escenarios posibles, para cada escenario identificar al menos un caso de prueba y las condiciones que lo harán ejecutable, para cada caso de prueba, identificar los datos de prueba a utilizar.
Es muy útil para identificar los escenarios posibles construir un flujo de eventos principal y alternativo:
No confundir un caso de pruebas con el plan de pruebas del sistema! A test case is a specification of the inputs, execution conditions, testing procedure, and expected results that define a single test to be executed to achieve a particular software testing objective, such as to exercise a particular program path or to verify compliance with a specific requirement.
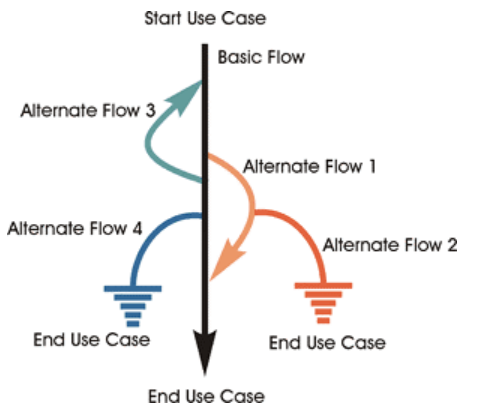
Es necesario incorporar las condiciones bordes de cada escenario.
Técnicas de caja blanca
La derivación de los casos de prueba se basa en la estructura/diseño del objeto de prueba. También se les llama técnicas basadas en estructura/código.
Existen dos técnicas importantes:
- Técnicas basadas en el flujo del control del programa: Expresan cubrimientos del testing en términos del grafo de flujo de control del programa
- Técnicas basadas en el flujo de datos del programa: Expresan cubrimientos en términos de las asociaciones definición-uso del programa
El cubrimiento de un código puede ser por diferentes criterios:
Cubrimiento de:
- sentencias: Asegura que el conjunto de casos de pruebas ejecuta al menos una vez cada instrucción
- decisión: cada decisión dentro del código toma al menos una vez el valor true y false para el conjunto de casos de pruebas.
- condición: cada condición dentro de una decisión debe tomar los valores true y false para el conjunto de casos de pruebas (CCP)
- decisión/condición: combinación de los dos criterios anteriores
- condición múltiple: Todas las combinaciones posibles de resultados de condición dentro de una decisión se deben ejecutar al menos una vez
- arcos
- caminos: Se ejecutan al menos una vez todos los caminos posibles.
- trayectorias independientes
Técnicas basadas en la experiencia
A diferencia de las pruebas dinámicas y estáticas, no es un enfoque sistemático. Se basa fuertemente en la intuición, habilidades, conocimiento y experiencia del testear. Los casos de prueba se basan en datos históricos (cosas que fallaron antes), o en donde se creen que podría haber problemas (error guessing).
Si no existe documentación como bases del testing, se pueden usar técnicas de testing exploratorio.
Testing exploratorio
En el testing exploratorio se realizan 3 actividades simultáneamente:
- Aprendizaje/exploración de la aplicación
- Diseño de casos de prueba
- Ejecución de casos de pruebas
No hay actividades explícitas de planificación, pero se puede hacer un enfoque basado en sesiones, definir objetivos a cumplir en cada sesión de testing (establecer x flujos, ver robustez, etc), y limitar el tiempo que abarca cada sesión (menos de 2hs).
En este tipo de testing los elementos de software son explorados. Al principio se ejecutan pocos casos de prueba para conocer mejor el software, se deriva su comportamiento y en base a los resultados de las sesiones anteriores se planifican nuevas sesiones utilizando un roadmap (hoja de ruta en español). Esta técnica es altamente dependiente de las habilidades del testear, ya que requiere ser observador, analítico y tener buen pensamiento crítico.
Algunas preguntas importantes al realizarse en cada sesión de prueba son:
- Cual es el objetivo?
- Que debe ser probado?
- Que método de prueba usar
- Que tipo de problemas podría encontrar
Durante las pruebas se construye un modelo mental del software, esas pruebas se están ejecutando contra ese modelo mental .
La mejor técnica de prueba depende de muchos factores del software. Desde la evaluación de riesgos y necesidades del cliente hasta el cumplimiento de estándares, la experiencia del equipo de testers y la disponibilidad de herramientas y documentación formal.
Notar que el testing exploratorio no es una técnica de caja negra ni de caja blanca. Es una forma de pensar el proceso de testing.
Proceso para testear un módulo
Según Jacobson, se debe ejecutar primero la caja negra, cuando está todo bien complementar con caja blanca. Esto se debe a que, al corregir errores de caja negra, el código va a cambiar, invalidando las pruebas hechas anteriormente de tipo caja blanca.
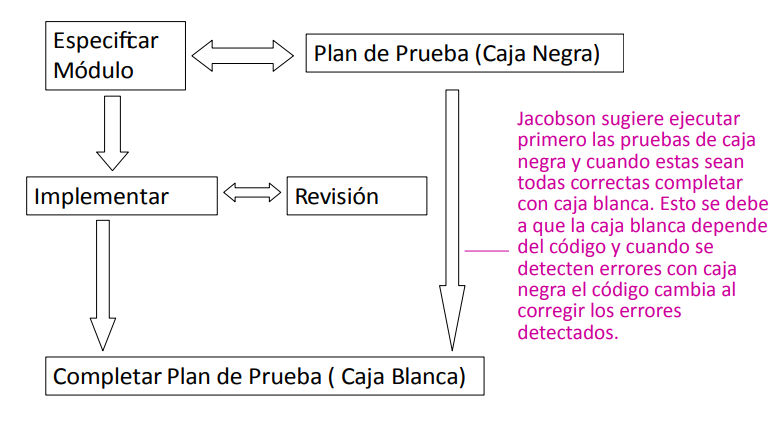
Comparación de técnicas
Estáticas
Ventajas
- Son efectivas en la detección temprana de defectos
- Sirven para verificar cualquier producto (requerimientos, diseño, casos de prueba, etc.)
- Conclusiones de validez general
Desventajas
- Está sujeto a errores en el razonamiento del tester
- No sirven para validar, solo para verificar
- No siempre consideran al hardware y software de base
Dinámicas
Ventajas
- considera el ambiente de trabajo donde es usado el software
- Sirven para verificar y validar
- Sirven para probar otras características además de funcionalidad
Desventajas
- Están atados al contexto de ejecución
- son difíciles de generalizar.
- Solo sirve para probar software ya construido
- Normalmente solo se detecta un error por prueba (luego de corregirlo aparecen nuevos errores...)
Pruebas no funcionales
En este tipo de pruebas resulta esencial definir el procedimiento de prueba (como se va a simular la carga, hacer el profiling de x manera, número de casos a probar, etc), los criterios de aceptación (ejemplo: El cliente valida el 90% de los casos de prueba en ambiente de producción y se cumplen los tiempos de respuesta), características del ambiente de producción (pueden haber grandes diferencias entre ambiente producción/desarrollo), estándares internacionales de prueba sobre los atributos de calidad del software.
Algunas pruebas clásicas definidas en estos estándares son:
- Pruebas de carga
- Prueba de performance
- Prueba de volumen
- Prueba de estrés
- Prueba de seguridad
- Prueba de confiabilidad
- Prueba de robustez
- Prueba de compatibilidad y conversión de datos
- Prueba de configuración: Validar y verificar que el cliente del sistema funciona apropiadamente en las estaciones de trabajo recomendadas. Estas pruebas verifican la operación del sistema en diferentes configuraciones de hardware y software.
- Prueba de facilidad de uso
- Prueba de documentación.
Gestión de pruebas (test management)
Es importante organizar las actividades de testing. Existen beneficios importantes al independizar el testing del desarrollo. Existen varias formas de hacerlo:
- Equipo de desarrollo responsable de las pruebas, los devs se verifican mutuamente el código
- Roles específicos de testers en el equipo
- Uno o más equipos especializados en testing trabajan en conjunto
- Especialistas independientes se especializan de actividades concretas (ej. experto en ciberseguridad)
- Tercerización de testing en una organización más barata. (reducir costos)
Roles en las pruebas
- Líder de testing (test manager). Planifica y hace el seguimiento de las actividades de verificación: Da soporte a las estrategias de pruebas a utilizar, asegura recursos para realizar las mismas, identifica métricas necesarias para dar seguimiento al progreso de las pruebas y controlar la calidad del software.
- Diseñador de pruebas (test analyst): Experto en métodos/técnicas de prueba
- Automatizador de pruebas: Sabe de testing, así como de programación y técnicas de automatización
- Administrador de pruebas: Experto en instalar y operar el entorno de pruebas
- Probador (tester): Ejecuta y reporta los resultados de las pruebas.
Planificar la verificación
Las actividades de verificación se deben planificar en mayor o menor grado dependiendo el proceso de desarrollo. Permite que el personal técnico obtenga una visión global de las pruebas del sistema y ubique su propio trabajo en ese contexto.
La V&V es un proceso caro. Se requiere llevar una planificación cuidadosa para obtener el máximo provecho de las revisiones y las pruebas para controlar los costos del proceso de V&V.
Se debe poner en balanza los enfoques estático y dinámico, utilizar estándares y procedimientos para las revisiones y pruebas, establecer listas de verificación para las inspecciones y tener un plan de pruebas definido.
El mayor error al planificar un proceso de prueba es: Suponer que no se encontrarán fallas al momento de realizar el cronograma.
Equivocarnos en esto implica subestimar la cantidad de tiempo y personal a asignar, resultando en entregas fuera de fecha o con actividades de V&V subpares.
Liberación
La liberación del sistema comprende todas las actividades a posteriori de que el sistema se haya construido y testado. Esto va más allá del deployment, incluye la instalación y configuración, adopción del software y entrenamiento y apoyo en el uso del nuevo sistema.
En más detalle, las fases de liberación son:
- Instalación y configuración: Instalar el software para que quede operativo. La dificultad de esto depende de la tecnología utilizada, requisitos funcionales y requisitos de disponibilidad (que tan bien tiene que quedar instalado xd). La facilidad de la instalación afecta la liberación inicial y las siguientes liberaciones durante mantenimiento, ya que muchas veces la liberación incluye la migración y carga de datos, parametrización de procesos, carga de usuarios y administración de permisos, etc.
- Adopción (conversión): Es el hecho de sustituir un sistema anterior por uno nuevo (ya sea uno manual o digital.). Incluye la carga de datos básicos, información histórica. Se debe definir una estrategia de conversión. Y estrategias de contingencia (que hacer sui el nuevo sistema tiene fallas operativas.)
Estrategias de adopción
Big Bang
El 12/12/2022 se van a instalar todos los módulos.
Esta instalación brusca debe organizarse cuidadosamente
Paulatina
De a poquito se van a instalando módulos, también pueden irse instalando por unidad de negocio, o por localización. Si bien es un cambio más suave, tiene el problema que conviven varios sistemas al mismo tiempo. Y se debe hacer un ajuste de procedimientos para este cambio intermedio, lo cual consume tiempo.
Procesamiento en paralelo
Existe un sistema que vive en producción, y otro que vive en un ambiente de prueba y control. Esta bueno para realizar entrenamiento y validación de la operación del sistema.
Estrategias Híbridas
Combinación de las 3 estrategias definidas anteriormente...
Entrenamiento
Es indispensable entrenar a las personas a operar con el software. Aunque este aspecto se ve condicionado por el perfil y necesidades de los usuarios. Existen 2 grupos de usuarios a entrenar. Los usuarios finales, los cuales quieren saber qué hace el sistema y como operar con él, y los administradores y operadores, que deben conocer cómo funciona el sistema y los mecanismos para dar soporte a este.
A su vez, existen diferentes necesidades del entrenamiento. No es lo mismo el training para usuarios frecuentes que eventuales. ¿Y los usuarios que se incorporan más tarde? Material de repaso para los usuarios experimentados. También estaría bueno dar entrenamiento especializado (explicar funcionalidades nuevas, por ejemplo.)
Materiales
Para dar soporte al entrenamiento, es buena idea utilizar:
- Documentos: Se debe cuidar el tamaño (mucho texto) y calidad, la relación costo/beneficio. Recordar que son muy pocos los usuarios dispuestos a leer.
- Ayuda en línea: Do de needful.
- Demostraciones, talleres y simulacros: Da un entrenamiento individual y dinámico, se debe definir su duración y cantidad.
- Usuarios expertos: Hay gente dispuesta a trabajar gratis y compartir su conocimiento en los foros (descentralización del soporte técnico).
Sobre la documentación
La documentación facilita el soporte técnico. Su importancia depende de la cantidad de usuarios, dispersión (usuarios en una oficina vs todo el mundo), y diversidad.
Los atributos de calidad clave de la documentación son legibilidad, completitud y correctitud.
Es importante considerar distintos roles en la documentación:
- User's manual: De propósito general y explica funcionalidades
- Operator's manual: Configuración del hardware/software, troubleshooting, acceso a usuarios. Lo necesario para el sysadmin
- Guía general del sistema: Detalles para que el cliente curioso comprenda, configuración hw+sw, filosofía del sistema.
- Developer's manual: APIs, interfaces, todo lo necesarios para el desarrollador del sistema.
Revisión del entrenamiento
Es importante evaluar los resultados del entrenamiento. Algunas métricas validas son:
- Grado de uso del sistema
- Eficiencia en el uso del sistema
- Cumplimiento de objetivos
Al entrenar, se debe tomar en cuenta los diferentes estilos de trabajo, presiones organizacionales y las características y preferencias personales de los usuarios y operadores.
Apoyo durante el uso del sistema
El apoyo básico durante el uso del sistema son los mensajes de error. Son una forma rápida de decirle al usuario que es lo que hizo mal. A su vez, estos mensajes pueden complementarse con guías rápidas de acceso, ayuda en línea y soporte a través de teléfono o internet. Sistemas más empresariales pueden tener un proceso de gestión de incidentes para sus distintos niveles de servicio. (Tickets, reclamos, e.g).
También está bueno que haya funcionalidades para deshacer procedimientos de contingencia.
Evolución
¿Por qué evoluciona el software?
El software evoluciona porque necesita:
- Adaptarse al entorno operativo cambiante
- Adaptarse al usuario
- Mejorar su desempeño
- Mejorar sus funcionalidades
- Corregir sus errores
Para ello, se requiere una adaptación y mantenimiento continuos para que una pieza de software siga siendo un asset valioso y útil para la organización.
Recordar, un sistema de software es un asset crítico para las organizaciones. Pero su valor decrece a medida que aumenta el desajuste entre lo que hace el software y la operativa de la organización. Por ello, los sistemas deben modificarse y actualizarse.
Recordemos que las actividades principales de la ingeniería de software son: Especificación, Diseño e Implementación, Validación y Evolución.
Las etapas de desarrollo y evolución del software pueden verse como una espiral, que va pasando por las etapas de especificación -> Implementación -> Validación -> Operación en cada versión. Cuando existe una diferencia marcada entre desarrollo y evolución, a la etapa de evolución se le llama mantenimiento de software.
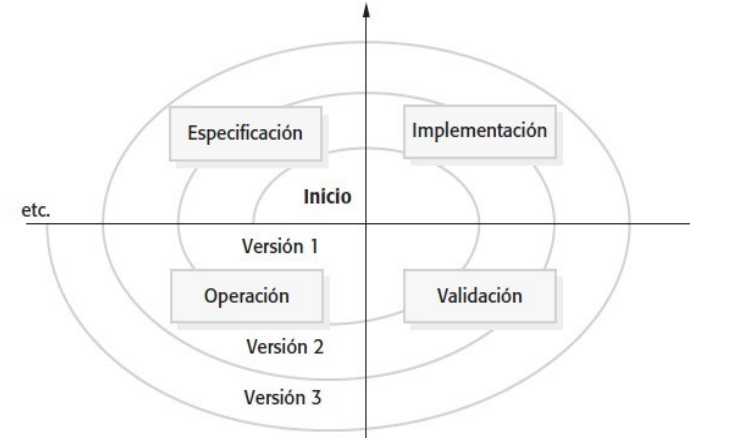
Por otra parta, el software puede pasar por un ciclo de vida completo:

Evolución: En esta etapa el sistema se encuentra en su auge operacional y evoluciona cuando los nuevos requisitos son propuestos y se implementan en el sistema en cada nueva versión.
Servicio: El software sigue siendo útil, pero solo se hacen cambios para que este se mantenga operativo. No se agregan más funcionalidades. Solo se corrigen errores y se hacen modificaciones para soportar cambios en el entorno del software.
Retiro Gradual: El software se sigue usando, pero ya no se va a hacer ningún cambio más sobre este.
Procesos de evolución
Las propuestas de cambio guían la evolución del software
Las sugerencias de cambios por lo general se basan en requisitos preexistentes que no fueron cumplidos antes de la liberación del sistema, nuevos requisitos que aparecen, errores reportados en el sistema y nuevas ideas del equipo de desarrollo.
Es importante identificar y relacionar los componentes que son afectados por un cambio, para poder estimar el costo e impacto de este.
La identificación de los cambios y la evolución continúan a lo largo de la vida del software. Los siguientes diagramas ilustran esta idea:
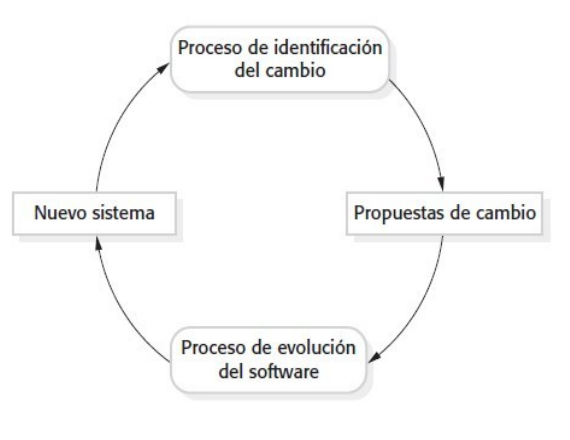
Una sugerencia por lo general sigue este proceso de vida (¡si no muere en el camino!)
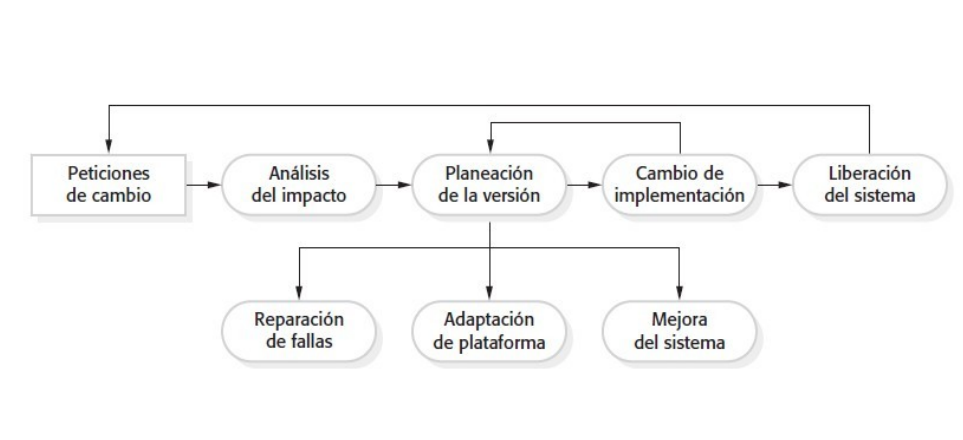
Análisis de impacto: Se evalúa que tan afectado resultará el sistema y cuánto va a costar el cambio. Cuando el equipo de mantenimiento es distinto del desarrollo, hacer un cambio implica entender el módulo que será afectado, por lo que la comprensión de dicho programa será un coste adicional. El análisis de impacto resulta en la planificación de una nueva versión con los cambios aceptados.
Plantación de la versión: Se consideran aquí todos los cambios que se han propuesto, se tiene que definir cuales cambios entran en la siguiente versión y cuáles no.
Liberación del sistema: Después de implementar todo, se libera la nueva versión. Así repitiéndose el proceso con esta nueva versión como base para la próxima liberación.
Implementación del cambio
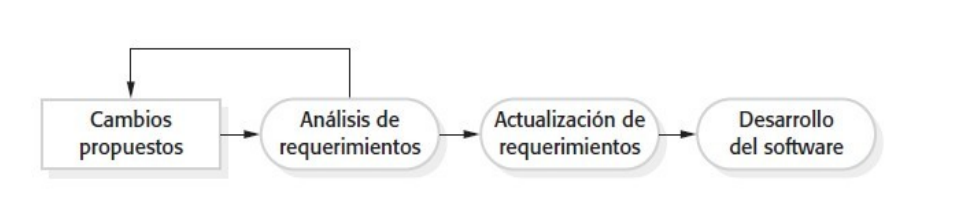
Durante la implementación, pueden surgir modificaciones a los cambios propuestos. También se debe considerar que en las primeras etapas de implementación puede implicar entender el código fuente del programa. Particularmente si fueron otros quienes lo hicieron.
Cambios Urgentes
Los cambios urgentes son aquellos cambios que tienen que implementarse sin pasar por todas las etapas del proceso de la organización. (O, mejor dicho, del proceso de la ingeniería de software).
Esto es necesario cuando hay fallas graces, cambios en el entorno que tienen efectos inesperados o necesidad de dar una respuesta rápida (¿ej. la competencia lanzó funcionalidad X, y nosotros?).
Para lanzar un cambio rápido, se elige una solución rápida. Sin embargo, no es la mejor opción. Y existen riesgos importantes como el de no actualizar documentación.
Una práctica de remediación es registrar un cambio urgente como para después rehacerlo bien. (Política del día después.)
Métodos Ágiles
La transición entre desarrollo y evolución es perfecta en los métodos ágiles. Ya que la evolución es una simple continuación del proceso de desarrollo basado en liberaciones frecuentes del sistema.
Las pruebas de regresión automatizada de los métodos ágiles son muy valiosas para seguir los cambios del sistema.
Los requisitos nuevos (cambios), se suelen expresar como historias de usuario adicionales.
Conversión evolución/desarrollo ágil.
Si el desarrollo fue ágil, pero la evolución se quiere seguir con un enfoque tradicional, va a existir el problema de falta de documentación detallada.
Si se siguió un enfoque tradicional, y se quiere hacer una evolución ágil. V a estar el problema de que puede no haber pruebas automatizadas ya desarrolladas y el código puede faltarle bastante refactoring.
Legacy Systems
Si bien los sistemas se reemplazan a medida que el negocio cambia, muchos sistemas muy viejos se siguen utilizando y tienen roles críticos. Estos son los legacy systems. Este concepto también puede abarcar hardware, librerías, software de soporte y procesos de negocio. Es un concepto abstracto. Tienen la característica de que han sido mantenidos por mucho tiempo, su estructura puede estar degradada y depender de hardware antiguo.
También puede pasar de que no soporten los nuevos procesos de negocio de la organización.
El mantenimiento de estos sistemas tiene dificultades y es costoso.
- Falta de habilidades o conocimiento de viejas tecnologías
- Dificultades para entender el código (escrito por muchos y con diferentes estilos)
- Sistema degradado por muchos años de mantenimiento y documentación inexistente/outdated
- Vulnerabilidades de seguridad
- Problemas de integración con nuevas tecnologías
- Ausencia de soporte oficial
- Hardware obsoleto y costoso de mantener
- Problemas en el manejo de datos (duplicación y baja calidad).
De todas maneras, tomar la decisión de reemplazar un legacy system puede ser costoso y muy riesgoso. Principalmente, por la falta de una especificación completa del sistema que reemplazamos. Los procesos de negocio se van a tener que modificar también, y muchas veces pasa que las reglas de negocio están hardcoded en el sistema legado y sin documentación.
Gestión de legacy systems
Se debe decidir que estrategia de evolución seguir para los legacy systems:
- Desechar el sistema por completo y modificar los procesos de negocio para no utilizarlo más.
- Continuar manteniendo el sistema
- Transformar el sistema a través de reingeniería y mejorar su mantenibilidad
- Reemplazar el sistema por uno nuevo.
Elegir la estrategia depende de la calidad del sistema legado y el valor que este tiene para el negocio. Se puede utilizar dos ejes para dividir los sistemas legado en cuatro grupos:
Los sistemas de baja calidad y poco valor se mandan a la papelera, los de buena calidad, pero poco valor puede verse de reemplazarse con componentes de terceros, desechar o mantener, los de baja calidad, pero alto valor si bien aportan al sistema son muy caros de mantener, por lo que deben reestructurarse o reemplazarse por otro sistema. Los que andan bien deben seguir en operación y mantenerse de forma normal.
Valor del software
Para evaluar el valor de un sistema para un negocio se deben tomar muchos puntos de vista (usuarios finales, clientes, gerentes de línea, administradores, etc.). Hay que entrevistar a los distintos grupos y ponderar resultados. Algunos aspectos básicos a considerar son:
- El uso del sistema: Si un sistema lo usa poca gente, puede que no sea tan importante para la organización
- Los procesos de negocio que soporta: Un sistema puede tener bajo valor para la organización si obliga a utilizar procesos de negocio ineficientes.
- Confianza en el sistema: Si el sistema no es confiable y afecta a los clientes, su valor para el negocio es bajo.
- Salidas del sistema: Si la organización depende del output del sistema, entonces el negocio vive de dicho sistema y no viceversa, el sistema tiene un valor muy alto para el negocio.
- Proceso de negocio: ¿El sistema hasta qué punto soporta los objetivos actuales del negocio?
- Evaluación del entorno: ¿Que tan efectivo es el ambiente del sistema y cuánto cuesta mantener este?
- Evaluación de la aplicación (calidad del software en sí): Cantidad de solicitudes de cambios/Volumen de datos que trabaja/ número de interfaces que tiene.
Mantenimiento del Software
Es la modificación de un programa luego de que está siendo utilizado.
Este término se utiliza más que nada para el software personalizado. El mantenimiento no genera grandes cambios de arquitectura, más bien implica modificar componentes preexistentes y agregar nuevos componentes con funcionalidades novedosas.
Tipos de mantenimiento
- Mantenimiento para reparar defectos o vulnerabilidades.
- Mantenimiento para adaptar el software a un entorno operativo diferente
- Mantenimiento para agregar o modificar funcionalidades al sistema (satisfacer nuevos requisitos)
Según Davidsen y Krogstie 2010, el 60% del esfuerzo de mantenimiento está en agregar y modificar funcionalidades, el 20% a adaptar a nuevos entornos y el 20% restante en corregir errores.
Categorización de Pfleeger 2010
Pfleeger define la siguiente categorización para las tareas de mantenimiento:
- Correctivo (21%): Es la reparación de fallas al controlar diariamente el funcionamiento del sistema
- Adaptativo (25%): Es cuando se modifica el sistema a los cambios del entorno.
- Perfectivo (50%): Se trata de mejorar funcionalidades existentes
- Preventivo (5%): Se hacen cambios para prevenir que el desempeño del software se degrade (ir mejorando la implementación sobre la marcha).
Costos de mantenimiento
Por lo general, el mantenimiento es más caro que el desarrollo (y también es más caro agregar funcionalidades ahora que en la etapa de desarrollo).
Es esencial que el grupo de mantenimiento entienda el sistema, el mantenimiento muchas veces corrompe la estructura del software y hace aún más difícil em mantenimiento de este. Mantener el software es aburrido, y hay poca motivación para hacer software mantenible. (Muchas veces se empuja por hacerlo rápido antes que mantenible).
Predicción del mantenimiento
La predicción de mantenimiento es la técnica de evaluar cuales partes del sistema van a causar problemas e incurrirán en los mayores costos de mantenimiento. Los costos del mantenimiento dependen del número de cambios y el costo del cambio depende de la capacidad de mantenimiento (la cual se reduce cuando el sistema se degrada al implementar cambios).
Notar que no es lo mismo que la predicción de cambios en el sistema.
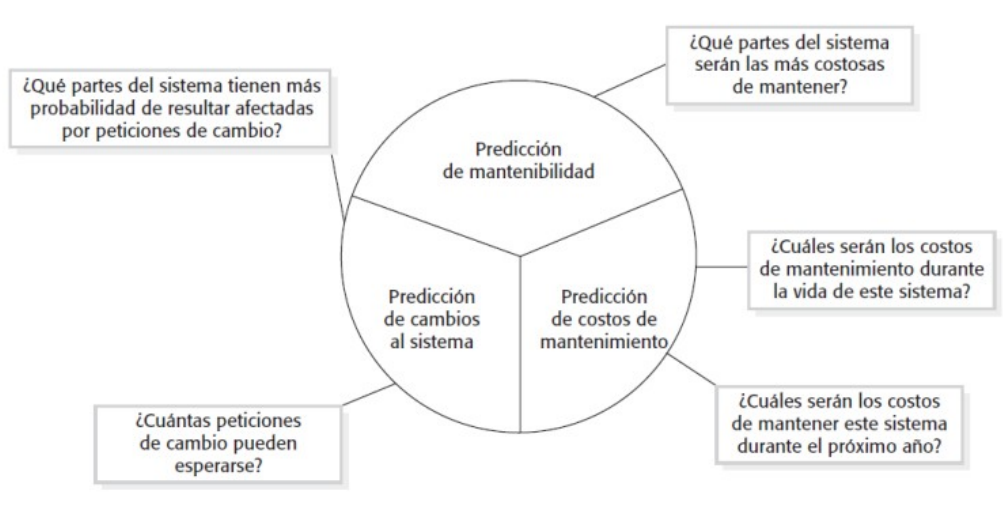
Métricas de complejidad
Las métricas de mantenimiento se pueden realizar mediante la evaluación de complejidad de los componentes del sistema. Está probado que el mayor esfuerzo de mantenimiento de un sistema se realiza sobre un numero pequeño de los componentes de este. Esta complejidad depende de las estructuras de control y datos que utiliza y los objetos, métodos y tamaño de los módulos.
Métricas de procesos
Las métricas de proceso pueden también utilizarse para evaluar la mantenibilidad. Estas métricas pueden ser, por ejemplo, la cantidad de solicitudes de mantenimiento correctivo (arreglar bugs), el promedio de tiempo del análisis de impacto, el promedio de tiempo para implementar una solicitud de cambio, etc.
Cambios de estas métricas permite sacar a luz si se está ganando o perdiendo mantenibilidad del sistema.
Predicción del cambio
Es la predicción de la cantidad de cambios que se van a requerir y la relación entre el cambio, el sistema, y el entorno donde trabaja.
Los sistemas fuertemente acoplados requieren de cambios cada vez que cambia su entorno. Los factores principales que influencian esta relación son:
- Cantidad y complejidad de las interfaces del sistema
- Cantidad de requisitos de sistema que son volátiles de forma inherente (requisito conexión con API inestable)
- Los procesos de negocio donde el sistema es utilizado.
Reingeniería del software
Consiste en la reestructuración o reescritura parcial o completa de un sistema legado. Es aplicable cuando se tiene que mantener frecuentemente un sistema legado. La esencia de la reingeniería consiste en realizar un gran esfuerzo para que el sistema sea más fácil de mantener a largo plazo.
Las ventajas de la reingeniería son la reducción del riesgo (Es menos riesgoso que desarrollar un nuevo software) y reducción de costo (es mucho más barato que hacer un software totalmente desde 0).
El proceso de reingeniería se ilustra en el siguiente diagrama:
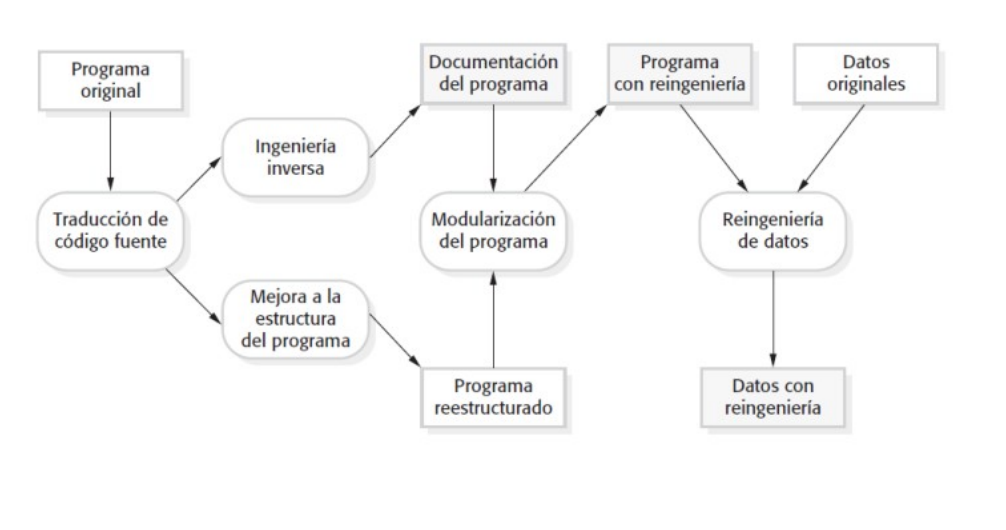
Enfoques de la reingeniería
A medida que se reestructura cada vez más un sistema, mayor es el costo de la reingeniería:
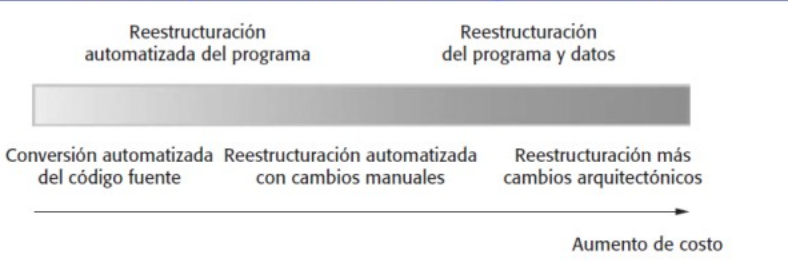
Otros factores que afectan el costo es la calidad del software a diseñar, las herramientas disponibles para la reingeniería (inb4 gdb), el grado de conversión de datos que se requiere (y su flexibilidad), la disponibilidad de personal experto en reingeniería (¿dónde consigo un experto de COBOL->JAVA?)
Refactorización
La refactorización es el proceso de hacer mejoras al sistema para reducir la degradación del sistema al realizar cambios.
Puede entenderse como un mantenimiento preventivo. Ya que reduce problemas en cambios futuros.
Cuando se hace refactoring, nunca se agregan nuevas funcionalidades.
Este proceso es inherente a las metodologías ágiles.
Refactorización vs reingeniería
La reingeniería toma lugar luego de que el sistema fue mantenido por x tiempo y sus costos de mantenimiento aumentan. Aquí se usan herramientas automatizadas para procesar y rediseñar sistemas legacy para hacer un nuevo sistema más mantenible.
En cambio, la refactorización es un proceso continuo de mejora en todo el proceso de desarrollo y en la evolución. Se tiene la intención de evitar que se degrada la estructura y el código del sistema para que no se dificulte su mantenimiento.
Bad Smells
Son señales de que el código podría estar mejor.
Por ejemplo, cuando vemos código duplicado (crear una función paramétrica), métodos muy largos, enunciados switch (utilizar polimorfismo), aglomeración de datos (mismos datos en varios lugares del programa) y generalidad especulativa (incluir generalidad en caso de que sea necesario en el futuro).
Deuda técnica
“Algunos problemas con el código son como una deuda financiera. Está bien pedir un préstamo a futuro, siempre que se pague.” Ward Cunningham, firmante del Manifiesto Ágil
Es pensar las decisiones en el código como una deuda de tiempo. Yo me ahorro X segundos ahora al hacer esto de forma casera, pero en 10 años para arreglar esto al sistema le va a llevar N*X segundos. ¡Al final N es como un interés!
Continuous Integration / Delivery / Deployment
Integración continua refiere a tener builds automatizadas con tests de aplicación e integración que se ejecutan automáticamente cada vez que se realiza un cambio. De esta manera se pude visualizar fácilmente cualquier error que se introduzca al software.
Por otra parte, continuous delivery refiere al deploy to staging y test de aceptación automatizados. Sin embargo, el deployment a producción sigue siendo manual. Por otra parte, el continuous deployment es igual al anterior a menos que el deployment a producción es automático.
Gestión de Proyectos
Un proyecto es “un esfuerzo temporal que se lleva a cabo para crear un producto, servicio o resultado único”.
¿Qué es la gestión de proyectos?
“La gestión de proyectos es la aplicación de conocimientos, habilidades, herramientas y técnicas a las actividades del proyecto para cumplir con los requisitos del mismo”
Los objetivos principales de la gestión de proyectos son:
- Entregar el sw en el tiempo acordado
- Mantener los costos dentro del presupuesto acordado
- Entregar un sw que cumpla con las expectativas del cliente
- Mantener un equipo funcionando
Las características distintivas de gestionar un equipo de SW son que se está tratando con un producto intangible, existe gran variabilidad entre los distintos proyectos de software, y cada organización trabaja con distintos procesos.
Por lo tanto, los siguientes factores determinan la gestión de los proyectos:
- Tamaño de la empresa
- Cliente
- Tamaño y tipo de SW
- Cultura organizacional
- Proceso de desarrollo de SW
Existen ciertas actividades que siempre están en la gestión de proyectos, como la planificación, gestión de RRHH, gestión de riesgos, seguimiento y control, etc.
Roles
Director de proyecto
“El director del proyecto es la persona asignada por la organización ejecutora para liderar al equipo responsable de alcanzar los objetivos del proyecto.”
El director debe ser alguien con conocimiento en dirección, debe ser capaz de aplicar los conocimientos y tener fuertes habilidades interpersonales. (Liderazgo, motivación, comunicación, etc.)
Interesados
Los interesados son las personas que tienen... un interés en el proyecto (usuarios, clientes, stakeholders, desarrolladores, etc.).
Es importante identificarlos, conocer sus responsabilidades e influencias sobre el proyecto para poder conocer sus expectativas sobre este y poder gestionarlas.
Ciclo de vida de un proyecto
El ciclo de vida de un proyecto tiene la siguiente estructura: Inicio del proyecto -> Organización y preparación -> Ejecución del trabajo -> Cierre del proyecto.
En cada fase hay un conjunto de actividades relacionadas, cada fase culmina con finalización de uno o más entregables.
Las fases de un proyecto pueden ser secuenciales o estar superpuestas (depende mucho). También existen muchos enfoques para los ciclos de vida:
- Predictivos / Orientados a planes
- Iterativos incrementales
- Adaptativos / Orientados al cambio.
Desarrollo orientado a planes
En este tipo de desarrollo los planes son bien detallados. Estos planes incluyen:
- Introducción
- Organización del proyecto
- Análisis de riesgos
- Requerimientos de recursos (HW y SW)
- Work breakdown structure (WBS): Estructura de desglose de trabajo.
- Cronograma
- Monitoreo y reporte
Planificación
La planificación se puede ubicar en 3 distintos lugares a lo largo del proyecto:
- En la propuesta/ contrato: Hay mucha incertidumbre, se hace una estimación del precio y del plan inicial
- Al inicio del proyecto: Menos incertidumbre, pero sigue habiendo muchos márgenes de error
- En forma periódica durante el proyecto: Se debe hacer cuando hay desvíos que fuerzan a cambiar el plan.
Proceso de planificación
Alcance
Se define el alcance de un producto como las características y funciones que describen un producto, servicio o resultado.
Se define el alcance de un proyecto como el trabajo a realizar para entregar un prodcuto/servicio/resultado con las funciones y características especificadas.
Para definir el alcance debemos:
- Recopilar los requisitos!
- Definir el alcance, cuales incluir y cuales no
- Crear la WBS (EDT): Estructura de desglose de trabajo.
WBS - EDT
“La EDT/WBS es una descomposición jerárquica del alcance total del trabajo a realizar por el equipo del proyecto para cumplir con los objetivos del proyecto y crear los entregables requeridos”
Para crear una EDT hay que subdividir los entregables del proyecto en pequeños componentes, desarrollar y asignar códigos de identificación para estos.
La EDT permite dar una visión estructurada del trabajo, construyendo paquetes de trabajo: Unidad indivisible de trabajo que se puede estimar, gestionar su costo y su duración.
El nivel de detalle de un paquete de trabajo depende de la complejidad y tamaño del proyecto.
La EDT es jerárquica, los componentes inferiores deben completarse al 100% para que el nivel padre también esté completo. Es decir, que una tarea padre está compuesta por los hijos y no hay ningún trabajo extra.
Cada entregable puede tener distintos niveles de actividades. Cuanto más descomponemos las actividades mayor capacidad de planificar, gestionar y controlar, pero existe un sobrecosto al particionar tanto, cuidado!
Existen dos estilos/presentaciones de EDT:
- Utilizando los entregables principales como el segundo nivel
- Utilizando las fases del ciclo de vida como el segundo nivel
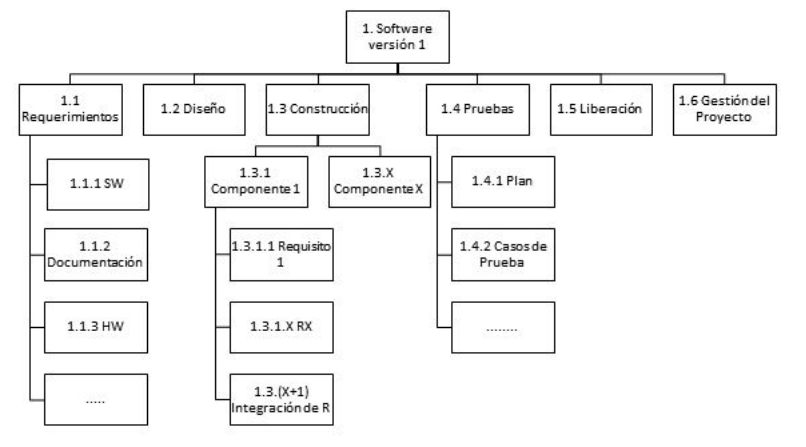
Actividades
Es importante identificar las actividades de un proyecto: los paquetes de trabajo de la EDT.
Estas actividades deben poder ser estimables, y formarán parte del cronograma.
Es necesario identificar precedencia entre las actividades (relaciones lógicas)
Estimaciones
Es el hecho de predecir cuanto va a durar un proyecto o cuanto va a costar.
Las estimaciones son inexactas debido a imprecisiones en los requisitos, entornos desconocidos (trabajar con tech muy avanzada) y la experiencia del equipo.
Una estimación es una proyección de la experiencia del pasado hacia el futuro, ajustando según las diferencias entre el pasado y el futuro.
Por lo tanto, para realizar una estimación es necesario contar con experiencia del pasado, saber algo del futuro y ser capaz de ajustar las diferencias entre ambas. De todas maneras, las estimaciones siempre están basadas en supuestos y restricciones.
Los proyectos deben reestimarse de forma periódica y aperiódica (un cambio de requerimientos, pérdida de personal, reducción de presupuesto, etc.)
Los factores básicos que influyen en una estimación:
- Tamaño del software (determinante). La productividad no es proporcional a la cantidad de desarrolladores.
- Tipo de SW
- Factores del personal (que tan bien anda la gente)
- Lenguaje de programación (¿java masters en el equipo?)
En procesos ágiles es importante que los elementos del product backlog cumplan con los criterios INVEST, así el equipo puede estimar el esfuerzo que llevará completarlo.
Métricas
Para estimar se necesitan métricas. Existen distintos tipos de métricas.
Métricas de tamaño
El tamaño es clave. Mide la cantidad de esfuerzo necesario, puede ser medido de forma objetiva y es un dato útil para comparar cuando se planteen proyectos similares.
Existen dos técnicas para medir el tamaño LOCS (lines of code) y puntos de extensión.
Las LOCS si bien sin fácil de medir automáticamente y útiles para comparar proyectos. Tienen el problema de que difícilmente se pueda estimar de forma temprana en el proyecto. Además no se debe utilizar como medida de productividad a no ser que se quiera generar catástrofes en el equipo de desarrollo.
Los puntos de función (Albrecht 79) son un cálculo que considera la cantidad de entradas de interfaces, salidas, archivos internos, queries y entradas de funciones. Es un cálculo basado en reglas. Está bueno porque no requiere que exista código, puede calcularse a partir de los documentos de diseño y es independiente del lenguaje. El problema es que es bastante complejo y está restringido a sistemas intensivo de datos y de poco peso algorítmico.
Técnicas
Existen dos tipos de técnicas para estimar:
- Basadas en la experiencia: Se estima en base a experiencia y conocimiento del equipo en proyectos pasados. Ej: Analogía, Juicio de expertos, Delphi
- Algoritmos: Se aplican métodos matemáticos considerando los atributos del producto (tamaño, experiencia, etc.). Ej: COCOMO
Analogía
Encontrar proyectos análogos para utilizarlos como referencia. Una forma de hacer esto es armar una tabla con proyectos pasados e identificar similitudes con distintas métricas (tipo de producto, tamaño, duración estimada, etc.)
Juicio de expertos
Consultar a n expertos por una estimación (considerando esfuerzo, tiempo, conocimientos del equipo, etc.)
Los expertos ajustaran según su criterio y que tantos datos tienen de la realidad.
Esta bueno ya que genera opiniones diversas. Tiene el problema de que puede pasar que los expertos sean muy optimistas o que las referencias del pasado sean incorrectas o incompletas.
Delphi
Es una técnica de estimación combinada entre expertos (A cada experto se le brinda la misma ). Consiste en:
- Primero se pide a los expertos que estimen.
- Luego, se le dice a cada experto los resultados de la estimación de los demás expertos e información adicional que se tenga.
- Se les pide que estimen again (entre 1 y 2 días después, repetir hasta convergencia).
Luego de 3 o 4 rondas de estimación se tiende a converger la opinión de los expertos. Tiene la ventaja de que las operaciones no se ven afectadas por los demás (ya que el experto sabe de la estimación, pero no quien la hizo).
Si hay convergencia de la estimación se hace una reunión para confirmar y discutir detalles. Si no converge hacer una reunión para ver diferencias entre expertos.
Existe también la variante Wideband Delphi donde los expertos se reúnen al principio para discutir el proyecto, luego se da tiempo para reflexionar y dar la estimación anónima. (Pueden existir influencias).
Otra variante interesante es Planning Poker (Scrum Poker) donde el proceso delhi se hace en una misma reunión utilizando cartas. Los expertos hacen las estimaciones poniendo cartas boca abajo. Luego las cartas se revelan y se discuten las estimaciones.
Algoritmos
Un ejemplo de algoritmo es:
\[ E = A \times Size^{B \times M} \]
donde \(A\) es una constante de la organización, \(Size\) una medida del producto, \(B\) la complejidad del producto (entre 1 y 1.5), y M un factor que considera el proceso, atributos, equipo, etc.
Parece una idea tentadora, pero tiene muchos problemas, ya que es difícil de aplicar en fases tempranas, las estimaciones de los factores son muy subjetiva y requiere de mucha calibración con datos de la historia organizacional que a veces ni siquiera existe.
Se recomienda el uso de tres valores. Por ejemplo: peor caso, mejor y más probable.
COCOMO II
Constructive cost model. Recolecta datos de diversos proyectos, estos datos se analizan y se definen formulas. Tiene 4 sub modelos: Composición de aplicaciones, diseño temprano, reúso y modelo post arquitectura.
Desarrollo del Cronograma
¡Una vez que tenemos las actividades y sus estimaciones podemos armar un cronograma!
Definimos el set de tareas como ternas (Nombre, Estimación, Precedencia). Donde precedencia es la lista de tareas que se deben ejecutar antes.
¡Armar un cronograma para un set de tareas es lo mismo que armar un grafo de precedencias! (Investigación operativa).
Nos interesa que, al definir este grafo de precedencias, hallar el camino crítico. Ya que este camino si se retrasa, atrasa todo el proyecto (definición). El camino crítico puede cambiar durante el ciclo de vida del proyecto y no tiene relación con la importancia técnica de las actividades.
Recordemos algunas definiciones de camino crítico:
- Comienzo temprano (ES): Lo antes posible que puede comenzar una actividad de forma válida.
- Comienzo tardío (LS): Lo más tarde que puede comenzar una actividad sin alterar la duración del proyecto (camino crítico).
- Fin temprano (EF): La fecha de fin si la actividad comienza lo antes posible y dura lo preciso
- Fin tardío (FT): Lo más tarde que puede terminar una actividad sin afectar la duración del proyecto
- Holgura total: Cuanto se puede atrasar una actividad sin afectar la fecha de fin del proyecto
- Holgura libre: Cuanto se puede retrasar una actividad sin afectar la fecha de inicio temprana de cualquier actividad subsiguiente inmediata.
Ahora bien, ahora que tenemos el grafo de precedencia armado podemos armar un cronograma (ubicar las tareas en el tiempo).
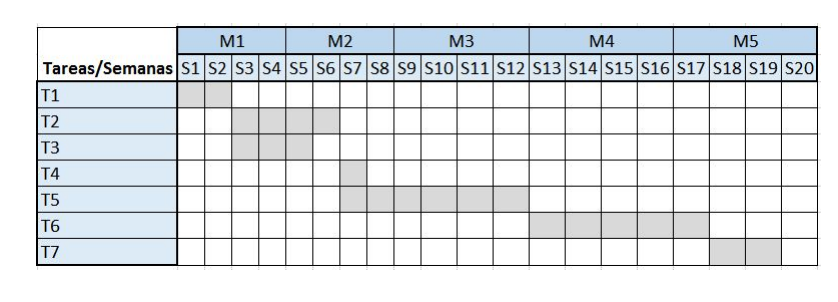
El problema está en que puede pasar que una semana quede sobrecargada de horas en relación a la capacidad de horas humanas que se dispone. La solución a esto es aplicar nivelación de recursos.
Nivelación de recursos
Se ajustan fechas de inicio y/o fin cuando hay restricciones de recursos.
Se usa luego de determinar el camino crítico y cuando hay recursos compartidos o críticos en ciertos momentos, disponibles en cantidad limitada, o que se quieren utilizar a un nivel constante durante un periodo de tiempo. Puede cambiar el camino crítico, usualmente crece en tiempo.
Acortar cronograma
Si hay que acortar el cronograma existen dos técnicas: Crashing (compresión) y Fast tracking (ejecución rápida).
En crashing el objetivo es acortar el cronograma con el menor incremento de costo posible (se hacen horas extra, por ejemplo). Solo sirve para las actividades del camino crítico y no es algo que siempre sea viable (tiene riesgos, por ejemplo, pérdida de calidad).
El fast tracking hace que fases que se planeaban hacer secuencialmente, se hagan en paralelo. Puede generar retrabajo ya aumentar riesgos. Solo funciona si las tareas son mínimamente paralelizable.
Gestión de Riesgos
Un riesgo es un evento o condición incierta que, si se produce, tiene un efecto positivo o negativo sobre al menos un objetivo del proyecto
Las organizaciones tienen distintos grados de tolerancia al riesgo y toman distintas actitudes frente a este.
Los riesgos se aceptan o se rechazan según el grado de recompensa o daño asociado.
Vocabulario:
- Riesgo positivo -> Oportunidad
- Riesgo negativo -> Amenaza
- Riesgo negativo materializado -> Problema
categorización
Se pueden categorizar los riesgos como:
- De proyecto: Efectos en el cronograma o recursos (ej. se va un miembro del equipo)
- De producto: Afectan su calidad (ej. falla en un componente clave del producto)
- De negocio: Afectan el negocio que se está construyendo (ej. aparece un nuevo competidor)
Proceso de Gestión
El siguiente diagrama ilustra las etapas de gestión de riesgos:
Identificación
Se determina qué riesgos pueden afectar y se documentan las características. Es una actividad de equipo (muchos puntos de vista). Se arma un checklist de los riesgos y cuales son de mayor impacto.
Tipos de riesgo
- Estimación: Se subestima el tiempo que lleva hacer el sw.
- Organizacional: Aparece una reestructura, recortes de presupuesto
- Personas: No hay gente para reclutar, alguien deja el barco
- Requisitos: Aparecen cambios en los requisitos que requieren mucho retrabajo
- Tecnológicos: Errores en componentes de software reutilizables, limitaciones de una tecnología (maxthreads)
- Herramientas: Las herramientas no se integran bien, son ineficientes.
Análisis
Existen dos tipos grandes: Cualitativo y cuantitativo.
En el análisis cualitativo se trata de medir:
- Impacto: Medida del efecto que causaría dicho evento (catastrófico, serio, menor)
- Probabilidad: Que tan probable sea el evento (Insignificante, baja, media alta).
- Severidad: Impacto * Probabilidad (¡Ordenar riesgos por severidad!)
El análisis cuantitativo aplica una técnica numérica para medir el efecto de los riesgos priorizados.
Una buena forma de analizar los riesgos es con una matriz de probabilidad/impacto:
Cada organización puede definir su umbral de riesgo, calificándolo como alto, moderado o bajo.
Planificación
Desarrollar acciones para mejorar las oportunidades y reducir las amenazas. (Según su severidad)
Para abordar riesgos negativos se pueden hacer 4 cosas:
- Evitar: Cambiar el plan para eliminar por completo la amenaza (ej reemplazar componente riesgoso)
- Mitigar: Reducir el riesgo a un umbral aceptable, ya sea por probabilidad o impacto (ej. contratar más gente en puestos clave)
- Transferir: Trasladar a un tercero todo o parte del impacto de la amenaza (ej. contratar un seguro)
- Aceptar: No hacer nada. (Puedo soportar el riesgo)
Para abordar riesgos positivos:
- Explotar: Eliminar la incertidumbre para que la oportunidad se concrete.
- Mejorar: Aumentar la probabilidad o impacto de la oportunidad
- Compartir: Asignar parte de la ventaja/oportunidad a un tercero mejor capacitado que sepa explotarla para el beneficio de ambos.
- Aceptar: Estoy dispuesto a tomar ventaja si se da la oportunidad, pero no hago nada para buscarla.
Estrategias de contingencia
Son las respuestas a riesgos diseñadas para utilizar solo si se producen determinados eventos.
Los eventos que pueden disparar un plan de contingencia deben estar bien definidos y ser monitoreados. Se deben guardar reservas para contingencias (tener gente preparada para salir cuando sea el momento).
Monitoreo
Es hacer un seguimiento periódico para detectar riesgos nuevos, cambiantes u obsoletos.
También se deben hacer un seguimiento de las condiciones de los planes de contingencia, revisar la ejecución de respuesta a riesgos, revisar los planes de contingencia y modificar el plan si es necesario.
Seguimiento
Existen varias técnicas para medir como va una tarea:
- De formula fija: Las tareas no empezadas se les asigna un 0, al comenzarlas se les asigna un % fijo al final del primer periodo y el otro porcentaje al completarlas. (25/75, 50/50, 0/100). Sirve para tareas cortas
- Hitos con peso: Se le asigna un valor a cada hito, en cada hito sube el porcentaje. Útil para tareas largas con entregables intermedios.
- Porcentaje de completitud, la responsable estima cuanta falta. Cuidado con el síndrome del 90%, donde hace 1 mes que se dice que "se está por terminar".
Enfoque del valor ganado
Es un modelo para unificar todas las actividades llevándolas a $$$ según su costo planificado. Permite controlar si algo logró el avance previsto y costó lo previsto.
Definiciones
Valor planificado (PV): Lo que tendría que tener hecho hoy, al valor que estimé. (Si hoy tenía que trabajar 10 horas a 10 usd la hora -> PV=100$)
Valor ganado (EV): Lo que hice hasta ahora, al valor que estimé. (Si tengo 80% del componente, que sale 1000 USD -> EV=800$)
Costo actual (AC): Lo que llevo gastado para el trabajo que hice: (Si trabajé 100 horas (y mi hora vale 10) -> 1000$)
Varianza de costos (CV): EV - AC. Si es negativo entonces gasté más de lo esperado.
Variación de cronograma (SV): EV-PV. Que tan atrasados estamos. Si es negativo estamos atrasados.
Cost performance index (CPI): EV/AC: Indica que tan eficiente estamos siendo. Si EV/AC < 1 entonces estamos siendo ineficientes (según la estimación).
Schedule performance index (SPI): EV/PV: Indica que tan eficiente estamos usando el tiempo. SPI = EV/PV < 1 entonces hay atraso.
presupuesto planificado (BAC). Cuanto pensábamos gastar en el proyecto
final planificado (FP): Cuando termina el proyecto
presupuesto final del proyecto (EAC): BAC/CPI : Permite estimar cuanto va a terminar costando el proyecto según la eficiencia.
tiempo final del proyecto (EAC(t)): FP/SPI : Permite estimar cuanto nos vamos a atrasar o adelantar.
¡Todo esto supone una variación típica manteniendo el índice SPI y CPI igual a lo largo del proyecto!
Equipo
Reclutar y retener “buena” gente no es una tarea fácil
Conseguir buena gente depende mucho de las habilidades del proyect manager. Algunos de sus factores que influencian esto son:
- Consistencia: ¿El PM trata a todos sus minions igual?
- Respetar diferencias: Diferentes skills y oportunidades de contribuir de cada minion.
- Inclusión: Que todos los minions se sientan considerados (sentimiento de igualdad)
- Honestidad: Ser transparente en cuanto al estado del proyecto.
Es importante desarrollar un buen equipo. Ya que permite disminuir costos ($ y tiempo) y mejorar la calidad de los entregables. Auemtar los sentimientos de confianza y cohesión levanta la moral y la eficiencia. Crea una cultura de equipo dinámica y cohesiva.
Motivación
Existen 3 grandes teorías con respecto a la motivación de los wagies: La Jerarquía de Maslow, la teoría de Herzberg y la teoría X e Y de McGregor.
Maslow 1954
Necesito cumplir las necesidades de abajo para poder cumplir las de arriba. Si cumplo todas estoy motivado.
Herzberg
Se habla de factores de higiene (son cosas que pueden destruir la motivación, pero no mejorarla). Por ejemplo: condiciones de seguridad, salario, salubridad, vida personal, etc.
Luego están los agentes de motivación que si afectan la motivación: Responsabilidad, reconocimiento, autorrealización, etc.
n Lo que motiva a las personas es el trabajo en sí.
McGregor
Está la teoría X (¡BAD WAGIE!) y la teoría Y (¡GOOD WAGIE!). Son dos supuestos opuestos que hacen los gerentes en cuanto a la naturaleza humana.
En la teoría X se supone que la gente odia su trabajo y no quiere trabajar, no hay ambición ni capacidad de resolver problemas. Los wagies tienen que ser dirigidos y no tomar iniciativas, la motivación es la más básica de maslow (agua), son egoístas no le importa cómo le va a la empresa.
En la teoría Y se supone que los wagies cumplen altas expectativas si están motivados. Son creativos y ambiciosos, auto disciplinados y autodirigibles. Están motivados con olas necesidades más altas de Maslow (autorrealización).
Personalidades Bass and Dunteman
A los wagies se los puede identificar con personalidades (arquetipos de personas):
- Orientado a tareas (le motiva el trabajo en sí, lo ve como un desafío intelectual)
- Orientado a si mismo (quiere el éxito personal y el reconocimiento, mira lo objetivos a largo plazo y buscan el éxito en el trabajo para su propio beneficio).
- Orientado a la interacción (le motivas el trabajo de sus compañeros)
Cohesión
Un grupo cohesivo es una sola unidad, están motivados por el éxito del equipo y no el éxito personal.
Tener un equipo cohesivo permite el aprendizaje compartido, compratir conocimientos y mejorar continuamente.
Un equipo es afectado por sus miembros (personalidades, balance de habilidades técnicas), su organización (quien es el líder, quien tomó las decisiones y quien interactúa con quien), y la comunicación de este.
Comunicación
Cuando hablamos entendemos lo que queremos.
Existen barreras que impiden la codificación/decodificación pura:
Barreras de codificación:
- Habilidades de comunicación
- Marco de referencia
- Credibilidad del transmisor
- Sensibilidad interpersonal
- Suposiciones sobre los receptores (ahh este ya debe saber x)
- Relación prexistente con los receptores
Barreras de decodificación:
- Tendencia evaluatoria
- Preconceptos
- Habilidades de comunicación
- Sensibilidad interpersonal
- Suposiciones sobre los emisores (ahh este no sabe nada)
- Relación prexistente con el emisor
- Escucha selectiva
La cantidad de posibles canales de comunicación en un equipo de proyecto está dada por la fórmula \(n(n-1)/2\) donde “n” es el número de integrantes
El impacto que tiene un mensaje, según Albert Mehrabian (1971) está dado un 65% por la expresión facial, un 38% por el tono de voz y un solo 7% por las palabras! Esto indica la importancia de la forma de hablar.
Es también una habilidad poder hacer preguntas, parafrasear, hacer contacto visual, comprender la real intención de un mensaje y tener una escucha activa.
Etapas del desarrollo de un equipo
Según Tuckman & Jensen, 1977. Un equipo puede estancarse en una de las siguientes etapas e incluso retroceder. Equipos que ya trabajaban desde antes no tienen que empezar en la primera etapa, la duración de cada etapa depende del tamaño y liderazgo del equipo.
Las 5 etapas son:
- Formación: El equipo se reúne y se le informa sobre el proyecto, y los roles de cada uno. Los miembros actúan de manera independiente y no muy abierta.
- Turbulencia: El equipo comienza a abordar el trabajo, toma decisiones técnicas y como se va a enfocar la dirección. Aquí puede pasar que haya miembros no colaborativos o no abiertos a ideas diferentes, puede pasar que aparezcan ambientes contraproducentes.
- Normalización: Los miembros del equipo empiezan a trabajar en conjunto y ajustar sus hábitos. Aparece la confianza entre los miembros del equipo.
- Desempeño: El equipo funciona como una unidad bien organizada, interdependiente, eficaz y afronta los problemas sin complicaciones.
- Disolución: El equipo completa el trabajo y se desliga del proyecto. Ya sea porque se libera personal, se terminan los entregables o se cierra el proyecto.
Gestión de conflictos
Los conflictos son naturales e inevitables. Se originan por cronograma, choques de personalidad, costos, opiniones técnicas, etc.
Es importante tener una actitud de apertura para resolverlos.
Hay que centrarse en el presente y en el problema. No en las personas y en el pasado.
Las técnicas para resolver conflictos son:
- Retirarse/Eludir: Retirarse cuando hay conflicto, táctica de retraso que enfría la situación.
- Suavizar/Adaptarse: Suavizar diferencias y resaltar puntos en común. No resuelve el problema, pero mantiene un ambiente cordial.
- Consensuar/Conciliar: Buscar soluciones que aporten cierto grado de satisfacción a ambas partes.
- Forzar/Dirigir: Imponer mi punto de vista, una parte gana la otra pierde
- Colaborar/Resolver: Incorporar varios puntos de vista para resolver el problema.
Desarrollo ágil
La mayor prioridad es satisfacer al cliente mediante la entrega temprana y continua de software con valor.
Los procesos Ágiles aprovechan el cambio para proporcionar ventaja competitiva al cliente.
Los proyectos se desarrollan en torno a individuos motivados. Hay que darles el entorno y el apoyo que necesitan, y confiables la ejecución del trabajo.
SCRUM
Un marco de trabajo mediante el cual las personas pueden hacer frente a problemas adaptativos complejos, mientras entregan, creativa y productivamente, productos del mayor valor posible.
Los 5 valores del SCRUM son:
- Foco: Conjunto acotado de funcionalidades.
- Coraje: Apoyo entre nosotros para afrontar desafíos
- Apertura: Transparencia y discusión abierta
- Compromiso: Equipos comprometidos
- Respeto mutuo y ayuda.
Los 3 pilares son Transparencia, inspección y adaptación.
Las estimaciones en SCRUM se hacen con técnicas basadas en Delphi, sucesión fibonacci o estimación relativa. Es discutido como hay que tratar la métrica velocity del development team. Se deben planear el Release plan de acuerdo a la velocity y prioridades.
El sprint burnt down chart permite ver el equipo como va respecto al plan. Se puede usar para estudiar la tendencia del sprint. No es para que el PM haga seguimiento.
Gestión de la configuración
Los sistemas de software están en un continuo cambio durante su desarrollo y su uso. La gestión de la configuración son las políticas, procesos y herramientas para gestionar los cambios en los sistemas de software.
Su propósito es evitar perder el tiempo o perder código fuente. (Ya sea al modificar versiones incorrectas o entregando versiones incorrectas de componentes o incluso el sistema entero).
La gestión de la configuración comprende las siguientes actividades:
- Gestión de versiones: Llevar el registro de las múltiples versiones del sistema y asegurarse que los cambios entre desarrolladores no interfieran entre si (aka git).
- Armado del sistema (buidling): Ensamblar componentes, datos y bibliotecas, compilarlas para generar un ejecutable.
- Gestión de cambios: Mantener registro de los requerimientos de cambios que realizan los clientes y desarrolladores, calcular el costo y evaluar el impacto de estos para ver si se pueden implementar. Seguimiento del proceso de realizar cambios.
- Gestión de liberación: Preparar el software para la liberación externa y llevar un registro de las versiones del software que los clientes tienen.
La gestión de la configuración es la gestión de un sistema de software en evolución.
En sistemas grandes existe un equipo de personas de Configuration Management que aseguren que los cambios se incorporan de manera controlado y llevan registro de los cambios.
Definiciones
Ítem de configuración: Cualquier cosa relacionada a un proyecto de software (código, datos de prueba, documentos, etc.) que haya sido puesto bajo control de configuración. Tienen un identificador único
Control de configuración: Proceso mediante el cual se asegura que se registran distintas versiones de un sistema y sus componentes para permitir gestionar los cambios.
Versión: Una instancia de un ítem de configuración que difiere (de alguna manera) con otras instancias del mismo ítem.
Baseline: A baseline is a collection of component versions that make up a system.
Codeline: A codeline is a sequence of revisions of a configuration item. (aka a branch).
Mainline: Secuencia de Baselines que representan distintas versiones de un sistema
Release (liberación): Una versión del sistema que ha sido liberada a los clientes para su uso.
Workspace: Área privada de trabajo donde se puede hacer modificaciones sin afectar a los desarrolladores.
Branching: La creación de una nueva codeline a partir de una versión de codeline existente.
Merging: La creación de una nueva codeline de un componente a partir de la unión de diferentes codelines.
Armado del sistema: Creación de un ejecutable del sistema
Principio de inmutabilidad.
La información congelada no se puede modificar más.
La SCM se basa en este principio. Es decir, existen versiones de un ítem de configuración.
Gestión de versiones
Es el proceso de realizar el seguimiento de las diferentes versiones de los componentes de software o ítems de configuración y los sistemas de los cuales forman parte.
Se debe asegurar que no haya interferencia entre los cambios de los desarrolladores.
Puede entenderse como la gestión de codelines y baselines.
Notar que la baseline permite recrear una versión específica de un sistema. Mientras que una codeline no es más que una secuencia de versiones del código fuente.
La gestión de versiones debe incluir las siguientes actividades:
- Identificación de las versiones y liberaciones (asignar un identificador)
- Gestión del almacenamiento: Herramientas para que tener muchas versiones no ocupen tanto lugar (ej. Git con los deltas).
- Registro histórico de cambios: Registrar todos los cambios (el git commit history)
- Desarrollo independiente: Se tiene que asegurar que las modificaciones realizadas a un componente por distintos programadores no interfieran entre si
- Soporte a proyectos: Soporte para proyectos que comparten componentes (git submodules?)
Control de versiones
Los sistemas de control de versiones identifican, almacenan y controlan el acceso a diferentes versiones de los componentes.
Existen 2 tipos, los sistemas centralizados donde hay un único repositorio que tiene todas las versiones y componentes de software (ya no se usa). Todo ocurre en un servidor compartide, se usan mecanismos de file locking (reserva de un recurso de forma explícita, se le hace check out para reservar un archivo y check in para devolverlo, un archivo bloqueado es read-only para los demás developers) y versión merging para evitar conflictos.
Y por otro lado están los sistemas descentralizados donde existen múltiples versiones de un repositorio al mismo tiempo (Git). Tiene un menor riesgo de pérdida de datos, no hay una copia canónica del código y aprovecha que las operaciones de commit, revert y history son más rápidas.
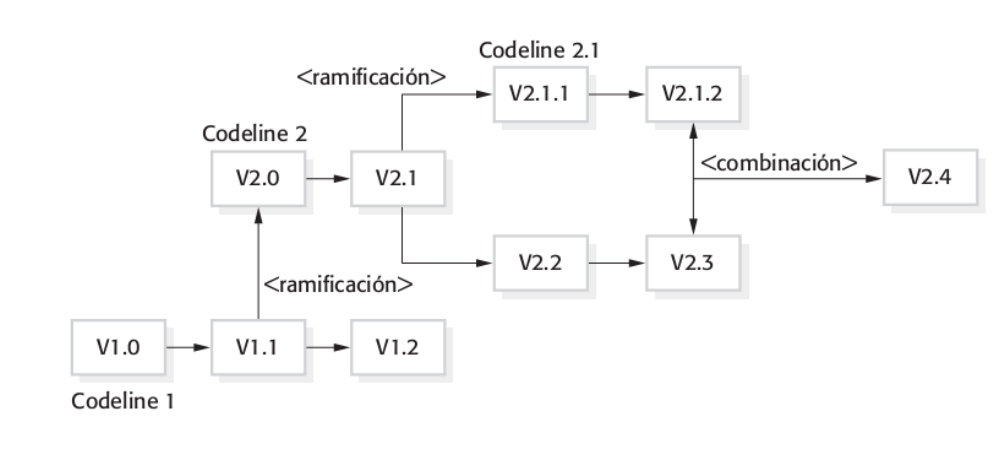
Armado del sistema
Es el proceso de crear una versión completa y ejecutable del sistema mediante la compilación y el linkeo de sus componentes, librerías externas, archivos de configuración, etc.
El software debería ser rearmado de forma frecuente y probado inmediatamente luego de cada versión. Así es más fácil detectar defectos y problemas que se introdujeron en armados anteriores.
Involucra hacer el checkout de versiones de componentes que se encuentran en un repositorio con version control system.
Existen herramientas que facilitan el armado del sistema:
- Generación de build scripts (CMake)
- Integración con sistemas de gestión de versión (Poetry)
- Recompilaciones mínimas (Make)
- Creación del ejecutable del sistema
- Automatización de pruebas (Git CI tools)
- Reporte de resultados
- Generación de documentación
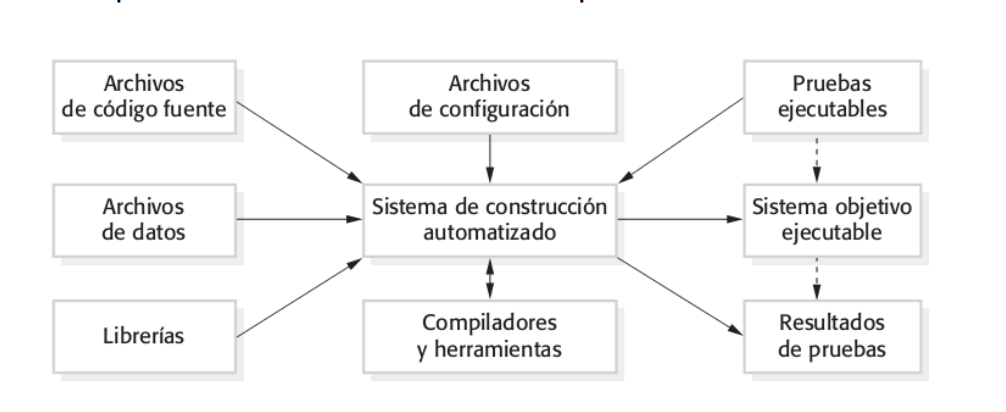
El siguiente paso de las herramientas que automatizan el trabajo es el continuous integration:
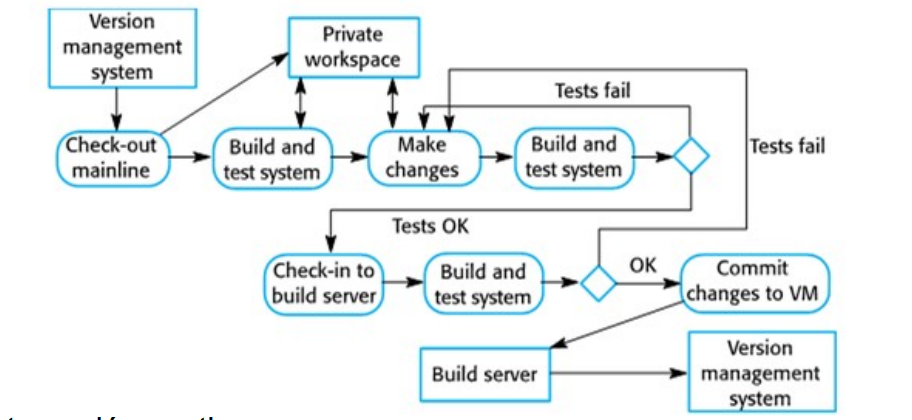
La integración continua es muy utilizada en las metodologías ágiles. Se recomienda complementar la CI con pruebas automatizadas. Permiten rápidamente resolver conflictos entre desarrolladores. No es buena cuando el sistema es muy grande o complejo, o existen diferencias entre la plataforma objetivo (target) y la de desarrollo.
La integración continua es una práctica de desarrollo de software mediante la cual los desarrolladores combinan los cambios en el código en un repositorio central de forma periódica, tras lo cual se ejecutan versiones y pruebas automáticas.
Cuando no se puede hacer integración continua se puede optar por integración frecuente, donde se hacen builds diarios o con cierta frecuencia. Hacer integración frecuente tiene el beneficio no solo en encontrar conflictos sino en aumentar la calidad de las pruebas unitarias.
Gestión de cambios
Su objetivo es asegurar que la evolución del sistema sea un proceso gestionado donde se priorizan cambios urgentes y beneficiosos.
Aquí se analizan los cotos y beneficios de las peticiones de cambios, se aprueban los cambios y se identifican las cosas que se deben modificar.
Hay que decidir si es rentable implementar el cambio X en una nueva versión de un sistema.
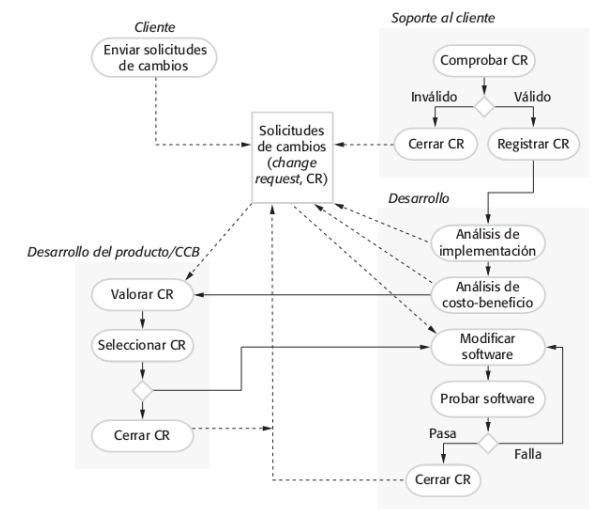
Podemos observar que este proceso de gestión puede dividirse en 4 grupos.
- Cliente: El cliente es quien genera las peticiones de cambio. (Change requests)
- Soporte al cliente: Se le da un soporte al cliente, donde dichas peticiones de cambio se comprueban si son válidas. Si son válidas se envían al área de desarrollo para su análisis.
- Desarrollo: Donde están los devs. Aquí se analiza la implementación de los cambios y se hace un análisis costo beneficio. Los resultados se mandan al área de desarrollo de producto para que evalúan los resultados. En la próxima versión, se reciben los change requests, estos se desarrollan modificando el software, se testea la nueva versión y se hacen cambios hasta pasar los tests, así cerrando el CR.
- Desarrollo del producto: Se reciben los análisis costo-beneficio y se seleccionan los cambios a enviar al equipo de desarrollo.
Para analizar los cambios existe un comité de control de cambios el cual tiene en cuenta:
- Las consecuencias de no realizar el cambio.
- Los beneficios del cambio.
- Número de usuarios afectados por el cambio.
- Costos de realizar el cambio
- Ciclo de su liberación
Este comité podría estar compuesto por el cliente, el patrocinador y el director de proyectos; pero no existe una regla exacta que determine quiénes son los integrantes del comité.
Ejemplo de formulario de petición de cambio:
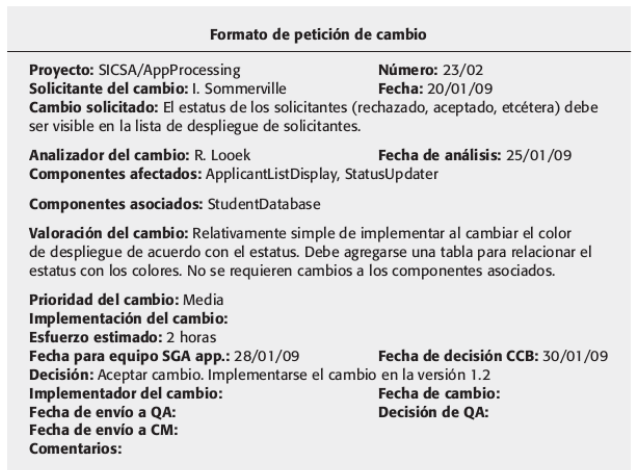
Otra cosa que se hace es llevar un historial de cambios:

Notar que estos ejemplos son muy anticuados. Hoy existen herramientas que proveen un soporte y proceso de gestión muy eficientes.
Durante el desarrollo se usa un proceso de gestión de cambios más sencillo, un cambio que no afecta nada lo decide el desarrollador él solito si hacer un cambio o no. Si afecta varios módulos, es decisión del arquitecto.
En metodologías ágiles
el cliente está directamente involucrado en la gestión de los cambios.
Los cambios del software los deciden los propios programadores del sistema.
Se debe considerar la propuesta de cambios como nuevos requerimientos, evaluar su impacto y discutir su prioridad para el siguiente incremento del sistema.
Gestión de liberación
Existen varios tipos de liberaciones (mayores, menors, fixes, etc.)
Cuando se produce una liberación se debe documentar esta para poder ser recreada en el futuro. Tiene que tener un objetivo, como estará compuesta y toda la información necesaria.
Liberar versiones es costoso.
Al planificar una liberación se debe considerar la calidad técnica del sistema (reparar fallas/ mejorar sistema), cambios en las plataformas donde se trabajan, etc.
La 5ta ley de Lehman indica que si se agregan muchas funcionalidades a un sistema necesariamente se introducen bugs a corregir en la próxima versión.
También se debe considerar la competencia, los requisitos del mercado (fechas) y las propuestas del cliente. Estos últimos factores son clave para decidir el momento de hacer una liberación mayor.
Una liberación incluye todos los componentes del software (ejecutables, configuraciones, documentaciones, archivos de datos, programas de instalación, packaging (dvd), etc.)
Un aspecto interesante es que puede ocurrir que haya varios clientes utilizando liberaciones del sistema distintas entre ellos.
Ahora con la proliferación de la internet aparecieron las actualizaciones vía internet. Estas pueden ser obligatorias o no (Windows 10), gratuitas, o como un premium. (¡free updates after purchase!).
La modalidad SaaS (software as a service) simplifica la gestión de liberaciones y la instalación del sistema, ahora es el developer el responsable de reemplazar la versión en producción por la nueva liberación. Y esta queda disponible automáticamente para todos los clientes.
Alcance y Formalismo
Los beneficios y costos de la SCM están artados al alance y grado de formalismo que se emplea. El alcance es la cantidad de objetos que están bajo la gestión, y el formalismo el nivel de detalle del control sobre las tareas de dicha gestión.
Es imposible determinar el grado de formalismo perfecto. La elección depende de los requerimientos de la empresa y las posibilidades.
En general hay un mínimo de inversión para evitar catástrofes (tener un repositorio git).
Al alcance de la gestión puede ir desde el producto (control de versiones, control de cambios y armado), soporte a nivel de proyecto (integración continua, actividades de gestión de cambios) hasta a nivel de la organización determinando procesos entre las actividades (flujo de trabajo).
Gestión de ambientes
- Desarrollo: Es el ambiente donde se desarrolla el software, lo controlan los developers.
- Prueba: Es un ambiente aislado para ejecutar las pruebas del sistema (integración y regresión). Lo usa únicamente el área de Testing.
- Pre-producción: Ambiente previo a la producción con la instalación de cambios que se consideran listos para producción. Este ambiente está destinado para pruebas a nivel de usuario.
- Producción: Where the real deal is going on.
Puntos clave
La ausencia de fallas no indica que no haya defectos.
Encontrar fallas y repararlas no siempre asegura que el software cumpla con las expectativas y necesidades del cliente.
Evaluar la calidad de los productos es uno de los objetivos de la verificación.
Desde que se crea un elemento y se pone en control de configuración este no tiene que pasar por todos los controles formales... pensar en la etapa de desarrollo.
El modelo en V se creó con el objetivo de que los cambios se pueden introducir de la forma más sencilla posible en el sistema.
La baseline de un proyecto es el conjunto de productos que han sido revisados formalmente y acordados.
Es necesario priorizar los casos de prueba para asignar los recursos necesarios para las pruebas.
La validación busca comprobar que el software hace lo que el usuario espera.
Las pruebas de regresión son muy útiles también en el mantenimiento y regresión del sistema... estas no se enfocan en las funcionalidades o artefactos nuevos del software sino en los preexistentes y de que estos no se hayan degradado.
Un posible criterio para finalizar las pruebas es el failure rate, si esta tasa cae debajo de un umbral puede decirse que seguir testeando no está económicamente justificado.
¡¡¡El avance de historias durante el sprint, no se da puntos hasta que la historia no está terminada!!! ¡Puede ser que perdamos puntos! Por ejemplo, si nos damos cuenta de que una historia no está realmente terminada. ¡El sprint burndown chart no muestra el progreso real porque solo muestra cuando se termina una historia!
Los defectos encontrados en producción o los cambios requeridos del sistema pueden ser expresados como historias de usuario adicionales.