Apuntes Curso Redes de Computadoras
Se toman apuntes de clases y el libro de Kurose: Computer Networking: A top-down approach.
Parte I - Computer Networks and the Internet
Que es la internet?
Podemos responderla de dos formas: Por los componentes físicos que la integran o en términos de una infraestructura de conexión que provee servicios a aplicaciones distribuidas.
Visión física
La internet esta formada por hosts or ends systems que se encuentran inter-conectados por communication links y packet switches. Los communication links pueden ser de muchos tipos (coaxial, cobre, fibra, etc) los cuales tienen sus características particulares. Cuando un host tiene que enviar información, la segmenta y le agrega headers con información. A estos segmentos se les llaman paquetes y son las unidades que viajan por la red. El sistema que recibe todos los paquetes los vuelve a ensamblar para obtener los datos originales. Los packet switches toman un paquete que llega desde una de sus entradas de comunicación y la reenvia por otra de sus salidas de comunicación. Existen muchos tipos de switches, los más predominantes son los routers y link-layer switches. La secuencia de communication links y packet switches por los que pasa un paquete por la red se le llama route/path.
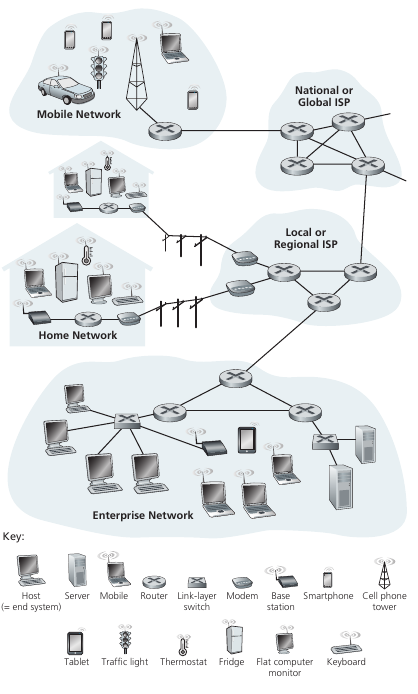
Los sistemas finales acceden a la internet a través de internet service providers (ISP), cada ISP es en sí una red de packet switches y comm links. Todos los dispositivos obedecen un protocolo para poder inter-comunicarse entre sí: Estos son el transmission control protocol (TCP) y el Internet Protocol (IP). El IP especifica el formato de los paquetes. A estos dos se les llama TCP/IP. Estos son regulados por agencias de standardization (IEEE & Engineering task force (Con sus requests for comments (RFC))). Algunos ejemplos de RFC's son: TCP,IP,HTTP,SMTP, hay más de 7000... La IEEE establece los protocolos LAN/MAN, Ethernet y WiFi. Un protocolo define el formato y orden de un intercambio de mensajes entre dos entidades así como las acciones tomadas por la transmission y/o recibo de un mensaje o otro evento.
Visión de servicios
La internet es una infraestructura que provee servicios a las aplicaciones. Las aplicaciones que usan estos servicios se les llama distributed applications, ya que reciben/envían datos de muchas partes. Las aplicaciones de internet corren en los hosts y son para los hosts. Los sistemas conectados a internet proveen una socket interface que especifica como un programa que corre en un host le pide a la internet para enviar datos a un programa que corre en otro host. Existe un conjunto de reglas e interfaces que el programa debe seguir para lograr la comunicación.
El borde de la red
Los hosts son quientes se encuentran en el borde de la red, por ello se les dice sistemas finales. A su vez, puede aveces dividirse los hosts en dos subsets: clientes y servidores. Un cliente es un celular o una pc de una persona normal, mientras que un servidor es una computadora mas potente que hostea paginas web, videos y servicios. Los grandes lugares donde se almacenan videos y contenido se les llama data centers.
Redes de acceso
Los comm links que conectan los sistemas finales al "interior de la red" a través del primer router (edge router) son el primer enlace que conecta un host con la internet. Existen distintos tipos y clases y tecnologías de acceso.
Tecnología de los comm links
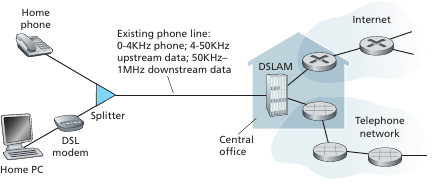
Para las residencias, existe el DSL,Cable,FTTH,Dial-Up y Satellite. El Digital subscriber line (DSL) es el que comprate la conexión con la red telefonica. Se transportan los datos en diferentes frecuencias de subida/bajada de internet y la red telefonica permitiendo enviar todo en simultaneo. El Digital subscriber line access multiplexer (DSLAM) se encarga de multiplexar los canales y enviarlos al corazón de la web y a las centrales telefónicas respectivamente. El rango de frecuencias para subida y bajada son distintos, dando valores distintos de velocidad, por ello se dice que la red es asimétrica y a su vez la ISP puede topear los valores según cuanto pagas. Los transmission rates también se ven topeados por la distancia, interferencia eléctrica y grosor del cable (twisted pair).
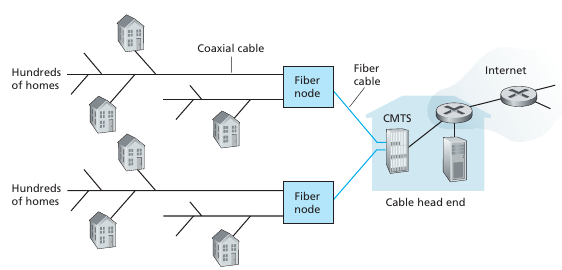
Por otro lado, el cable usa la infraestructura de la red de televisión. Se puede combinar con fibra óptica, lo que se le llama hybrid fiber coax (HFC). Cada medio requiere un modem especial para transformar la señal digital de ethernet a la del medio (cable/dsl modem). La unión entre el cable y el modem se le llama cable modem termination system (CMTS) y cumple una función similar al DSLAM que es la transformación de señales según el medio. Notar que la internet por cable estaba pensada para el broadcast, por el cable se recibe las señales de todos los usuarios y el modem tiene que pickear las que son para el.
Países avanzados como uruguay utilizan fibra óptica, a esto se le llama FTTH (Fiber to the home). Por lo general tenemos un cable de fibra que es usado por muchos usuarios y a medida que nos vamos acercando cada usuario tiene un cable individual. Existen dos arquitecturas para diseñar la red de fibra: passive optical network (PON) y active optical network (AON).
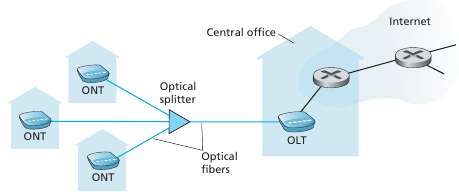
El dial-up era la tech que utilizaba literalmente la red telefonica, no permitiendo usar el teléfono a la vez y era super lenta. Para lugares remotos se puede usar la conexión satelital, esta por temas de distancia tiene importantes desventajas.
Dentro de lo que se denomina la red local (LAN), los sistemas utilizan ethernet para conectarse al switch. Se utiliza un twisted pair copper wire. Luego este switch se conecta al router que provee conexión con la ISP. Otro método popular es el Wireless LAN (WiFi). Las redes móviles como el 3G y el LTE son también usadas para acceder a la red.
Medios físicos
Es el medio por donde los bits llegan de un receptor a otro. Existen dos grandes categorías: medios guiados y no guiados los guiados son los que pasan por un medio solido, como un cable de cobre. Y los no guiados son los que se transportan por la atmósfera y el espacio como ondas electromagnéticas (wifi).
#l par trenzado de cobre, se trenza para reducir la interferencia (cada cable de 1mm de grosor esta insulado) El par de cables constituye un communication link. Unshielded twisted pair UTP es el más utilizado para conectar computadoras. El cable coaxial consiste en dos conductores concéntricos con insulación y protección. La fibra óptica transmite pulsos de luz, son inmunes a la frecuencia electromagnética aunque son algo frágiles. En el corazón de la red se usa este medio, no es tan predominante en las redes de hogar por el alto costo de los dispositivos. Luego están los medios de radio como el wifi y los satelitales. Existen dos tipos de satélites: los geoestacionarios y los de LEO (low-earth-orbiting). Los geoestacionarios están a 36000 km de la superficie para igualar la velocidad de rotación de la tierra, tienen como 280ms xd. LEO están más cerca de la tierra y no se mantienen quietos, rotan sobre la misma y se comunican entre otros satélites y estaciones en la tierra. Para proveer comunicación continua tiene que haber muchos satélites LEO conectados y un meticuloso calculo de órbitas.
El corazón de la red
Packet switching
Para enviar paquetes de un host a otro, los paquetes recorren un path de comm links y packet switches (routers and link-layer switches). Los paquetes se transmiten por cada comm link a una tasa igual a la full transmission rate del link. Es decir, si se mandan $L \ bits$ por un link con tasa de transmisión $R \ bits/sec$, el tiempo de transmisión del paquete será $ \frac{L}{R} $ segundos. La mayoría de packet switches usan store-and-forward transmission en las inputs de los links. Estos es, los packet switches tienen que recibir,almacenar y procesar todos los bits de una paquete antes de poder reenviarlo a otra entrada. Debido a esto el delay de envíar un paquete de L bits con un path de N links con rate R (N-1 packet switches) es $ d_{end-to-end} = N\frac{L}{R} $.
Un packet switch tiene multiples links que lo conectan, cada link tiene un output buffer\queue que guarda los paquetes que el router esta planeando enviar por ese link. Si un paquete quiere viajar por ese link pero el link esta ocupado por otro paquete, este debe esperar en ese buffer. Como consecuencia, los paquetes al viajar sufren queueing delays los cuales dependen del estado de congestión de la red. Si llega un paquete y el buffer está lleno, el router va a deshacerse de un paquete del buffer o descartar el entrante, i.e packet loss.
Cuando al router le llega un paquete, como sabe a quien mandárselo? Existe distintas formas de implementar packet forwarding. Forwarding tables se utilizan para realizar el forwarding, cuando llega un paquete como header se tiene la dirección de destino, dicha dirección se parsea y se mira en una tabla a que nodo enviarla y elegir el outbound link apropiado. Y como se construye dicha tabla? Para ello se utilizan routing protocols los cuales setean automáticamente dichas tablas.
Circuit switching
Circuit switching es otra alternativa para enviar datos por una red. En esta, los recursos que construyen el path son reservados por la duración de la comunicación entre dos sistemas finales. Como consecuencia, tienen que esperar para acceder a un communication link. Las redes telefónicas son el ejemplo estrella de circuit switching networks. Una diferencia clave es que cuando reservamos el recurso tenemos una tasa de transmisión asegurada, en cambio en la conmutación de paquetes, no hay ninguna garantía de que un paquete no se retrase en algún conmutador. un circuito en una red de conmutación de circuitos se implementa utilizando frequency division multiplexing (FDM) o time-division multiplexing (TDM). En FDM, las frecuencias del link se particionan y se asignan a los pedidos de conexión en un link. El rango de frecuencias asignada a un link se le llama ancho de banda (bandwidth). En TDM, el tiempo se divide en frames y a cada frame se divide en slots donde se asignan los pedidos de conexión.
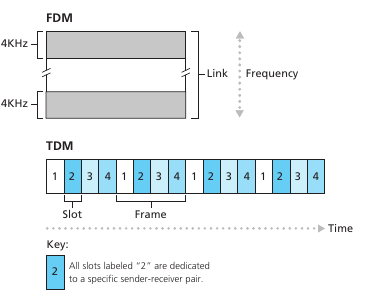
Una de las críticas al modelo de circuitos es que sufre de silent periods esto es, momentos donde hay reservado un circuito pero en realidad no se está utilizando. Otro problema es que asignar un circuito es un problema complejo y requiere un tiempo considerable. Sin embargo, una vez que tenemos el circuito establecido es importante destacar que el tiempo de transmisión es independiente del número de links del circuito. A su vez, como cada usuario tiene que tener asignado una porción del link, la capacidad de usuarios que pueden usar la red de forma concurrente va a ser considerablemente menor.
Red de redes
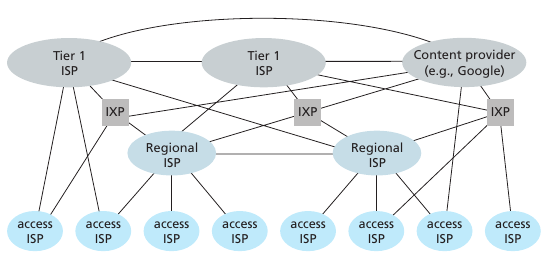
Los usuarios se conectan a un ISP para acceder a internet. A su vez, los ISP se deben conectar entre ellos para poder interconectar a todos los usuarios. La estructura de la red tiene carácter socio-económico. Los ISP se estructuran por regiones y con el objetivo de minimizar costos. Básicamente tenemos las ISP de acceso (tier-3) que son pequeñas, estás ISP se conectan a ISP's regionales o directamente con una tier-1. Las ISP's regionales se conectan con una ISP tier1 para acceder a los hosts de las demas regiones. A su vez las isps tier 1 se conectan entre si para brindar una cobertura de todo el globo. Las ISP chicas se conectan a las ISP grandes a través de PoP (Points of presence) lo cual es simplemente un lugar con muchos routers juntos. Multi-home se le llama cuando una ISP tiene más de 1 ISP proveedor. Peering se le llama al hecho de conectar dos ISPs geográficamente cercanas para reducir el costo de pasar por un ISP grande. Los internet exchange points (IXP) es un edificio independiente que se dedica a conectar multiples ISP en un punto neutral. Finalmente tenemos las content-provider networks las cuales son redes independientes a la internet administradas por grandes compañías privadas (e.g Google) para conectar sus servidores con sus servicios. Estas redes de contenido se conectan muchas veces de forma directa con las ISPs pequeñas para abaratar costos y tener un mejor control del servicio.
Delay, Loss, and Throughput in Packet-Switched Networks
Throughput is the amount of data per second that can be transferred. The internet has physical hardware and an increasing level of complexity, so many kinds of delays and throughputs appear.
Delay
Existen muchos tipos de delays, los mas importantes en una circuito de conmutación de paquetes son:
- Nodal processing delay
- Queueing delay
- Transmission delay
- Propagation delay
- Nodal delay
Donde: $d{Nodal} = d{processing}+d{queueing}+d{transmission}+d_{propagation}$
La suma de los cuatro primeros generan el nodal delay, el cual es el delay que sucede en cada nodo de un path.
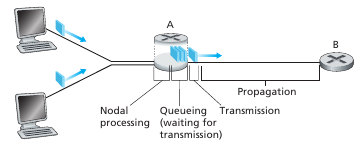
El processing delay es el tiempo requerido para examinar el header de un paquete y determinar a donde dirigirlo. También puede incluir otros factores, como el tiempo para hacer la corrección de errores del paquete recibido. Suele ser del orden de microsegundos. El queueing delay es el tiempo que espera el paquete en la cola esperando a ser transmitido por el comm link. Este tiempo depende de su posición en la cola al llegar y el estado de congestión de la red. Suele ser del orden de microsegundos a milisegundos. El transmission delay es el tiempo que me lleva meter el paquete en el link. Dado un paquete de L bits, y un link con una tasa de transmisión de R bits por segundo. el transmission delay es $ \frac{L}{R} $. Suelen ser del orden de microsegundos a milisegundos. El propagation delay es el tiempo físico que le lleva un bit propagarse a través del medio desde el origen al destino. El tiempo de propagación depende de la velocidad de propagación del medio y el largo del mismo. Es decir, dado un medio con velocidad de propagación $s$ metros por segundo y un link de largo $m$ metros el propagation delay es $ \frac{d}{s}$ sec. Suele ser del orden de milisegundos.
Cual delays es el predominante depende mucho del contexto. LAN, WAN, conexión satelital o dial up... Red vacía o llena de usuarios, todas estas variables y muchas mas afectan el retraso en cada nodo de la internet.
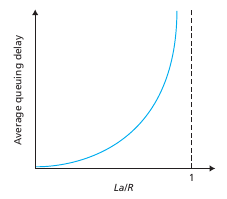
Queueing delay
El queueing delay es uno de los mas interesantes. Una de las variables para medirlo es el ratio $a\times \frac{L}{R}$ aka traffic intensity. Donde $L$ es el largo del paquete, $R$ es la tasa de transmisión y $a$ la tasa promedio en que llegan paquetes al conmutador. Si la intensidad de trafico está cerca de uno la cola va a tender a llenarse y tendremos packet loss! Por lo que es importante que la intensidad de la cola sea menor a 1+eps. Matemáticamente baste que la intensidad sea menor a 1, pero en la realidad es necesario que sea menos debido a la naturaleza del uso de la red los paquetes nunca llegan a tiempo constante sino que llegan en bursts aleatorios. Por lo que se necesita una intensidad menor a 1 para poder procesar estos bursts. La performance de un nodo no solo se mide en términos de su delay sino también de la probabilidad de que tenga un packet loss.
End-to-End delay
De forma general, para un paquete que viaja por N-1 routers, tenemos que el delay de un bit entre llegar de un host a otro es: $ d{end-end} = N\times (d{proc}+d{trans}+d{prop}) $. Asumiendo que las colas siempre están vaciás. Notar que esto es para redes homogéneas donde todos los nodos tienen los mismos tiempos de delay.
Extra delays
Existen otros tipos de delays asociados a los protocolos de comunicación y aplicaciones que generan delays adicionales. Un ejemplo es el packetization delay asociado a codificar el audio digital en Voice over IP VoiP applications.
Throughput
Considere que desea enviar un largo archivo entre un host A y B. El throughput instantáneo (ancho de banda), en un instante del tiempo, es la tasa en bits sobre segundo que el host B recibe un archivo. Si tengo $F$ bits, y la transferencia lleva $T$ segundos, el average throughput va a ser $\frac{F}{T} bits/sec$. En un path que pasa por muchos links el ancho de banda va a estar dado por el bottleneck link, esto es el link con menor ancho de banda. Notar que un link puede estar siendo usado por muchos usuarios por lo que el throughput instantáneo de un link es variable. Notar que el throughput es importante para descargar archivos grandes (de muchos paquetes), por ejemplo un video. Mientras que el delay toma una mayor importancia cuando queremos que un paquete llegue lo antes posible a un host (ej: online gaming o una videollamada)
Protocol Layers and their service models
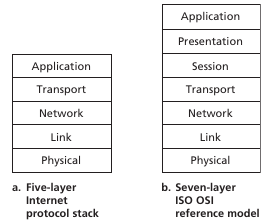
La internet sigue una arquitectura de capas, donde los diseñadores de la red organizaron los protocolos (+ el hardware y software que lo implementa) en layers. Cada protocolo de la internet pertenece a un layer. Cada uno de estos layer provee servicios realizando acciones dentro del mismo layer o utilizando layers inferiores. Un protocolo puede implementarse en una combinación de hardware y software. Protocol layering tiene ventajas conceptuales y estructurales y permite actualizar los sistemas con mayor facilidad. Sin embargo tiene sus contras como el overhead. La internet rompe muchas veces las estructuras obteniendo información de distintos layers en layers de más arriba o abajo. Todos los layers juntos se les llama el protocol stack, la internet tiene un stack de 5 capas.
Application layer
En esta capa es donde reside las aplicaciones de la red y sus protocolos. Estos incluyen: HTTP (transferir documentos), SMTP (email), FTP (archivos), DNS (website.com -> ip address domain name service), etc. Un protocolo de application es distribuidor entre muchos hosts, donde una aplicación desde un host usa el protocolo para intercambiar paquetes con otros. Estos paquetes desde el application layer se les llama mensajes (messages).
Transport Layer
El transport layer transporta los mensajes del application layer entre dos application endpoints. Existen dos protocolos en la internet: Transmission Control Protocol TCP y User Datagram Protocol UDP. TCP provee una conexión con delivery asegurado,flow control (matcher velocidades entre el sender/receiver) y congestion control. UDP no provee ninguno de los servicios mencionados anteriormente. Un paquete desde la capa de transporte se le llama segmento (segment)
Network layer
El network layer es responsable de mover network-layer packets: datagrams desde un host a otro. Básicamente el transport layer le manda un segmento y una destination address al network layer, y este se encarga de transportarlo al host destino. Este layer incluye el protocolo IP, que define el contenido de los datagrams. También contiene los protocolos de enrutamiento sobre que dirección toma un paquete al llegar a un router. A todos estos protocolos se les llama informalmente ip layer.
Link layer
Para mover un paquete de un nodo a otro el network layer usa los servicios del link layer. En cada nodo el network layer le pasa el datagrama al link layer el cual manda el mismo al siguiente nodo, luego el link layer devuelve el datagrama al network layer en el siguiente nodo. Ejemplos de protocolos son Ethernet, wifi, DOCSIS (data over cable service interface specification), etc. Los paquetes de un link layer son llamados frames.
Physical layer
Mientras que el link layer mueve frames de un host adyacente a otro, el link layer se encarga de mover cada bit individual dentro del frame. Estos dependen de las características físicas del medio. Cada medio tendrá su physical layer protocol el cual considera las características del mismo (twisted pair copper wire, fiber optics, etc.)
Encapsulamiento
El internet stack genera que los paquetes se envíen de la siguiente forma:
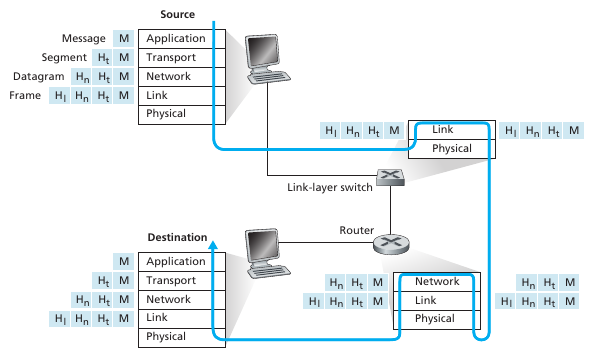
En esta imagen sale a la luz una diferencia importante entre un router y un link-layer switch: Un router implementa las capas 1-3 del protocolo mientras que un link-layer switch solo la 1-2. Es decir, el switch mira la ethernet address para saber por que link reenviarlo, pero necesita un router para poder enviar el paquete a la red y enrutarlo según la ip.
Esta forma de transporte genera la encapsulación de cada paquete de las capas, cada capa inferior encapsula el paquete de la capa superior y le agrega su información pertinente para cumplir el protocolo. Por ello, dado un layer tenemos que un paquete tiene 2 campos, el header que tiene la info que precisa el layer para implementar el protocolo y el payload con el contenido del mensaje a enviar.
El modelo OSI
Open systems interconnection es un modelo inventado por la ISO que se construyo de forma artificial allá por 1970. Agrega dos layer adicionales: Presentation layer y session layer. El primero permite a las aplicaciones interpretar el significado de los datos que intercambian. Esto incluye: Compresión de datos e encryption, descripción de los datos, etc. El session layer provee formas para delimitar y sincronizar el intercambio de datos, incluyendo formas de tener checkpoints y esquemas de recuperación. Son servicios bastante abstractos que caen dentro del application layer.
Network attacks
La internet fue pensada como un modelo hippie donde todos estamos conectados y nos confiamos entre si. Estó generó un monton de problemas cuando la internet se comenzó a utilizar de forma masiva. Distintos tipos de vulnerabilidades son:
Malware: A través de una conexión por internet un host le puede mandar un programa malicioso a otro. Un malware puede hacer cualquier cosa sobre el host dependiendo del acceso que tenga al sistema. Se le llama botnet a la red de computadoras infectada por malware que permite al atacante controlarla remotamente. Muchos tipos de malware son de tipo self-replicating, esto es que cuando infectan a un host tratan de replicarse en otros hosts que el host está conectado así expandiéndose. Se le llama virus al malware que requiere interacción de usuario para activarse y worms al que no requiere interacción explicita del usuario, pueden entrar por una vulnerabilidad directa del protocolo.
Server attacks: Otros problemas son los denial of service (DOS) attacks. Estos son ataques que tratan de exhaust los recursos de un servidor haciendo que el mismo no pueda continuar su funcionamiento normal. Existen 3 subtipos:
- Vulnerability attack: Consiste en enviar ciertos paquetes crafteados especialmente para un host con el objetivo de romperlo.
- Bandwidth flooding: El atacante enviá tantos paquetes que el access link del servidor se congestiona, no permitiendo a los usuarios reales llegar al servidor
Connection flooding: El attacker establece muchas conexiones TCP "semi abiertas\abiertas" y no las cierra. La performance del host se reduce por la cantidad de conexiones que tiene abierta no permitiendo a los usuarios reales establecer una connexion legitima.
Los ataques que se realizan desde una botnet se les llaman distributes DoS (DDoS).
SNIFF: Es posible capturar los paquetes que se transmitiendo a través de los enlaces. Un recibidor pasivo que captura cada paquete que pasa por la red se le llama packet sniffer. Un sniffer puede colocarse tanto en LANs como en Wifis. Defensas al sniffing se basan en el encriptado de mensajes.
SPOOF: Un host puede pasarse por alguien que no es o decir que es algo que no es alternado los headers que envía. La capacidad de inyectar paquetes en la internet con un dirección fuente falsa se le llama ip spoofing. La solución a esto es implementar end-point authentication. La cual verifica que ambos lados de la conexión verifican quien dicen ser.
Parte II - Application Layer
Principles of network applications
Network application development is writing programs that run on different end systems and communicate with each other over the network. Notar que el software que se diseña es para los sistemas finales, los sistemas intermedios que constituyen la red no implementan el application layer. Notar que no es lo mismo la arquitectura de la aplicación que la arquitectura de la red, la red implementa una arquitectura en capas, una aplicación es diseñada por los creadores para su conveniencia y dicta como se comporta los sistemas finales. La arquitectura de la red solamente provee un set especifico de servicios a estas apps. Las dos arquitecturas de aplicaciones predominantes son las de cliente/servidor y P2P (peer-to-peer). En la arquitectura cliente-servidor hay un host que recibe pedidos de muchos otros hosts (clientes). Un ejemplo clásico de esto son las aplicaciones web,ftp,telnet y email. Por lo general el servidor tiene una IP bien conocida y siempre esta disponible, permitiendo al cliente contactar al mismo en cualquier momento. Los data centers son lugares donde se alojan los hosts para asegurar su disponibilidad y poder atender a muchos clientes. En una arquitectura P2P cada host es a la vez un cliente y un servidor. Una de las ventajas de esto es su self-scalability y reducción de costos. Las desventajas de las P2P son problemas de seguridad, performance y reliability por su estructura descentralizada.
Processes Communicating
Dos procesos (SO) que se encuentran en distintos hosts se comunican intercambiando mensajes a través de la red. Una network application consiste en un par de procesos que se envían mensajes a través de una red. Por ejemplo como un Web server intercambia mensajes con el navegador de un cliente. En todo par de procesos comunicándose siempre hay una relación cliente servidor:
In the context of a communication session between a pair of processes, the process that initiates the communication (that is, initially contacts the other process at the beginning of the session) is labelled as the client. The process that waits to be contacted to begin the session is the server.
The Interface Between the Process and the Computer Network
Ahora bien, como hace un proceso para envíar un mensaje por la red? Un proceso envía y recibe mensajes a través de una interfaz de software llamada socket. Un socket es como una puerta, si los procesos están dentro de una casa, para enviar un mensaje un proceso saca un mensaje por una puerta, el mensaje recorre la red, y termina en la puerta de la casa de otro proceso para que este lo levante. Un socket es la interfaz entre el application layer y el transport layer en un host. También se le llama application programming interface (API) entre la aplicación y la red. El desarrollador tiene control de todo lo que sucede en el socket desde el lado de la aplicación pero casi ninguno del lado de la capa de transporte. Las opciones que tiene en la capa de transporte son elegir el protocolo de transporte (TCP y UDP) y elegir un par de parámetros de la capa de transporte como el tamaño máximo y mínimo de buffers y segmentos. Cuando se elige un protocolo la aplicación usa los servicios de trasporte provisto por ese protocolo.
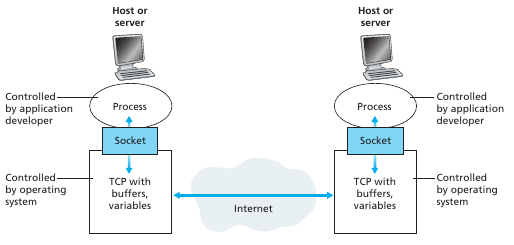
Adressing process
Como hace un proceso para referirse a un proceso en otro host en particular? Para ello se necesitan direcciones. Para identificar a un proceso se necesitan dos cosas: La dirección del host y un identificador para el proceso que se encuentra en dicho host. En la internet el host se identifica con una ip address, lo cual es una tira de 32 bits que identifica a un host de forma única. Para identificar a un proceso (o mejor dicho, al socket donde enviar el mensaje) se necesita saber el port number, ya que un host tiene muchos sockets funcionando. Puertos estándar son el puerto 80 para servicios web, el mail (SMTP) por el puerto 25, y muchos más.
Servicios de transporte disponibles para aplicaciones
La aplicación se encarga de mandar mensajes por un socket a un socket destino en otro host, el transport layer tiene la responsabilidad de hacer llegar esos mensajes al socket del proceso que quiere recibir el mensaje. La internet provee más de un protocolo de transporte, los cuales están caracterizados por los servicios que ofrecen:
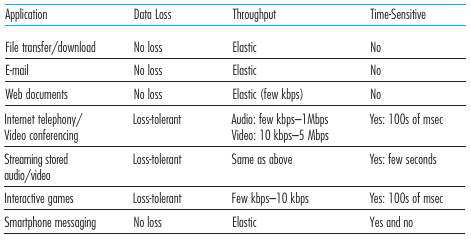
Reliable data transfer: Muchas aplicaciones necesitan la garantía de que cuando envíamos un mensaje este llegue de forma integra al destino, no pueden haber errores. Pero cuando la cola de un router se llena y hay un packet loss que hacemos? Se necesita hacer algo para asegurar que los datos enviados por una app llegan de forma completa e integra al otro lado. Los protocolos que ofrecen esta garantía se dicen que ofrecen reliable data transfer. Si el protocolo de transporte provee este servicio, el proceso puede mandar datos al socket y tener la garantía de que los datos van a llegar sin errores al otro proceso. Si no se provee este servicio, puede pasar que algunos paquetes nunca lleguen al proceso destino, esto puede ser acceptable en aplicaciones loss tolerant como servicios de streaming de audio/video.
Throughput: Un protocolo podría asegurar un throughput al utilizarlo. Aplicaciones que tienen requerimientos de throughput se les llaman bandwidth-sensitive applications, un ejemplo de esto son los servicios de streaming. Muchas de estas aplicaciones utilizan técnicas de codificación y regulación para poder matchear el contenido que envían con el throughput de la red. Las elastic applications utilizan todo el throughput que tienen disponible, ejemplo de esto es el correo o de descarga de archivos.
Timing: Un protocolo podría asegurar que le va llevar no mas de x segundos enviar un mensaje a un host. Esto seria particularmente util n sistemas de tiempo real o aplicaciones de llamada telefonica.
Security: El protocolo de transporte podría proveer servicios de seguridad, por ejemplo encriptando todos los datos que la aplicación coloca en el socket para su envío seguro.
La siguiente lista muestra las necesidades de algunas aplicaciones:
TCP
El modelo de servicio TCP incluye un servicio orientado a conexiones y de reliable data transfer. Cuando una app usa este protocolo recibe ambos de estos servicios. Connection oriented service refiere a que el cliente y servidor intercambian información antes de que los mensajes a nivel de aplicación comienzan a ser enviados/recibidos. Este handshaking alerta al cliente y servidor para prepararse para la transferencia de paquetes. Tras realizado el handshake, se dice que existe una conexión TCP entre los dos sockets. La conexión se dice que es full-duplex ya que ambos pueden enviar mensajes entre si al mismo tiempo. Cuando la aplicación termina de enviar mensajes debe "desarmar" la conexión TCP. A su vez, los procesos que se comunican pueden confiar en TCP para enviar cada uno de los bits que envían y que llegan en el orden correcto. TCP también incluye un control de congestión, que hace un throttle sobre los paquetes que envía cuando la red está congestionada. En sí TCP (ni UDP) proveen encriptación. Se ha desarrollado una mejora a TCP llamada Secure Sockets Layer el cual extiende TCP y provee servicios de seguridad como encriptación y authentication. SSL no es un protocolo de transporte sino una mejora de TCP que está implementada en el application layer. SSL tiene su propia Socket API que los programadores deben utilizar si quieren utilizar sus servicios.
Clase: TCP ofrece un stream, UDP ofrece un mensaje. TCP asegura que no se pierden bytes en un stream. Si mi aplicación tiene el concepto de mensaje, tengo que delimitarlo de alguna manera. Ejemplo practico: Vos en TCP enviás 'a' y luego 'b', el proceso servidor recibe 'ab', recibe todo el stream!!!
UDP
UDP es un protocolo liviano que provee servicios mínimo, es connectionless por lo que no hay handshake. Provee unreliable data transfer, no asegura que el mensaje llegue ni que llegue en el orden correcto. No tiene control de congestion.
Nótese que la internet no provee ningún servicio de timing y throughput, trata de hacer lo mejor posible y la mayor parte de las veces lo cumple. Es posible que esta filosofía de poco compromiso es lo que le dio a la Internet la versatilidad para crecer a un ritmo tan acelerado y convertirse en la red de computadoras que es hoy en dia.
La siguiente imagen muestra populares protocolos del application layer y el transport layer que se encuentra por detrás:
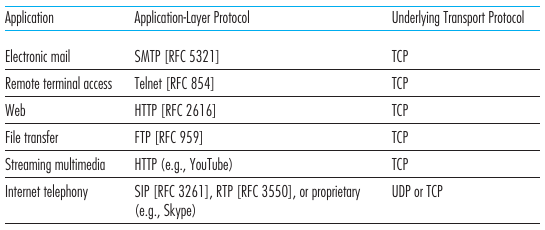
Application-Layer Protocols
Como se estructuran los mensajes que se envían al socket? Un protocolo de la capa de aplicación define como un proceso de una aplicación, corriendo en distintos hosts, se pasa mensajes entre sí. En particular define:
- El tipo de mensajes intercambiados. Ej: mensajes request y response
- La sintaxis de los mensajes, los campos de los mensajes y como se delimitan
- La semántica de los campos, el significado de la información que se encuentra en dichos campos
- Reglas para determinar cuando y como un proceso enviá y responde mensajes.
Los siguientes temas tratan en particular de los principales protocolos de aplicación de internet. Es importante antes notar la diferencia entre una network application y un application-layer protocol. El ultimo es solo una parte de una aplicación en red. Por ejemplo, La Web es una aplicación servidor/cliente que permite a los clientes obtener documentos. La aplicación web consiste de muchos componentes: Un standard para el formato de documentos (html), un browser (chromium), web servers (apache) y un application layer protocol: HTTP.
The Web & HTTP
Overview of HTTP
HyperText Transfer Protocol es uno de los protocolos de aplicación más importantes de la web. HTTP se implementa en dos programas: un programa cliente y un programa servidor. El cliente y el servidor hablan entre sí intercambiando mensajes HTTP.
Repasando antes algunos conceptos de la web: Una webpage consiste en objectos. Un un objeto es un archivo. Ej: HTML,JPEG,Java applet. Estos son referenciables con un URL. La mayoría de los sitios web tienen un base html site donde se referencia a los objetos. Web browsers implementan el lado cliente del HTTP (Ej: firefox) y Web servers implementan el lado servidor del HTTP, hosteando objetos que son accesible con una URL. Ej de webservers son: Apache, Microsoft Internet Information Server.
HTTP usa TCP como su protocolo de transporte. Primero, el cliente HTTP inicia una conexión TCP con el servidor, una vez establecida el cliente y el servidor acceden a TCP por sus interfaces de socket. El cliente envía una HTTP request al socket del servidor y recibe un mensaje de respuesta HTTP en su socket. Una vez que se envía el mensaje TCP se encarga de mandarlo. I love arquitectura en capas :). Notar que el servidor envía archivos sin guardar información sobre el cliente. Por ello se dice que HTTP es un stateless protocol.
Persistence of connections
En las aplicaciones de internet el cliente se comunica por un periodo de tiempo largo y hace varias requests al servidor. La cuestión está en si hay que iniciar una conexión TCP cada vez que hacemos una solicitud o podemos dejar esta conexión abierta y enviar todas las requests dentro de esta conexión. Estos dos approaches son llamados persistent and non-persistent connections. HTTP por defecto usa conexiones persistentes, pero es posible configurarlo para usar el modo no peristente.
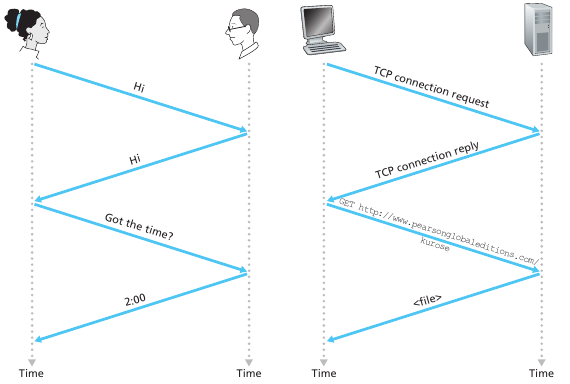
Si accedemos a una pagina html con 10 imágenes tenemos que hacer 11 conexiones TCP. Estas conexiones pueden realizarse en paralelo dependiendo del navegador. Se define el round-trip time (RTT) como el tiempo que le lleva a un paquete epsilón viajar del cliente al servidor y luego volver al cliente. RTT incluye delays de propagación procesamiento y encolamiento. Cuando clickeamos un hyperlink sucede un "three-way handshake": básicamente el cliente manda un pequeño segmento TCP al servidor, el servidor lo acepta y responde con otro segmento TCP y finalmente el cliente acepta y vuelve a enviar al servidor. Al completar las dos partes del handshake (1 RTT) el cliente envía un HTTP request file junto con el acknowledge del "three-way handshake a la conexión TCP". Al llegar la request al servidor este le envía el archivo finalmente. Por lo tanto el tiempo total de respuesta para envíar un archivo es siempre 2 RTT más el tiempo de tansmision del archivo desde el servidor.
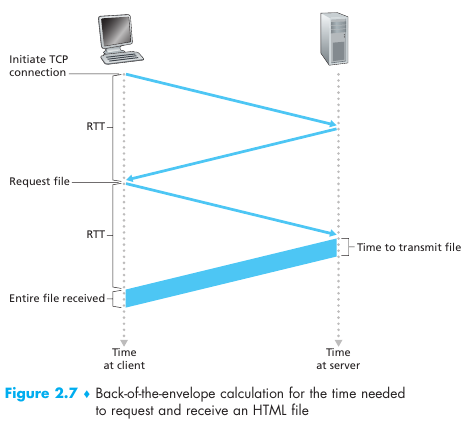
Por cada objeto que pedimos "TCP buffers must be allocated and TCP variables must be kept in both server and client". Esto es una carga para el servidor web, que atiende miles de clientes. Y agrega un RTT adicional. En una conexión persistente se deja abierta la conexión tcp y se puede enviar un sitio web con muchos objetos en una sola conexión, a su vez las requests se pueden hacer de forma consecutiva sin esperar respuestas generando como un pipeline. Por lo general el servidor HTTP cierra la conexión cuando se deja de usar por un cierto tiempo (configurable timeout). HTTP/2 Es el protocolo que implementa pipelining con requests y respuestas enviadas de forma multiplexada en una misma conexión y un mecanismo de prioritization de requests.
HTTP Message format
HTTP Request message
Un mensaje de HTTP típico enviado por un cliente tiene la forma:
GET /index.html HTTP/1.1
Host: www.dogs.com
Connection: close
User-agent: Mozilla/5.0
Accept-language: en
Un request message puede tener una cantidad variable de lineas. La primera linea se le llama request line y las siguientes header lines. La request line tiene 3 campos: el método, URL y versión de HTTP. El método puede tomar los valores : {GET,POST,HEAD,PUT,DELETE,etc.}. La mayoría de las requests usan el método GET. El campo host indica en donde se encuentra el host, este campo es necesario para implementar los web proxy caches. Connection: close hace que el browser le diga al servidor que cierre la conexión cuando termine de enviar el objeto pedido. User agent habla de quien es el navegador, esto permite al servidor dar diferentes versiones del mismo objeto al igual que el accept language. Estos headers se le llaman negotiation headers. El formato de una HTTP request puede verse en la siguiente figura:
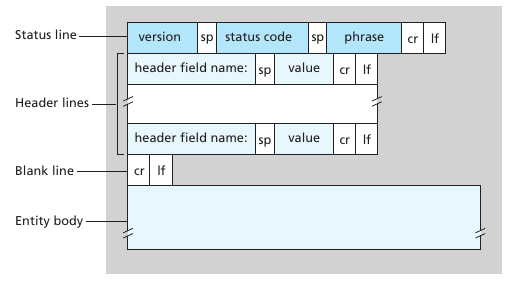
Notar que en el ejemplo de arriba el "entity body" está vació. Este se usa en el método POST para indicar los campos que el usuario llenó. Sirve por ejemplo para llenar formularios. Sin embargo enviar datos al servidor también puede hacerse con el método GET y incluir los datos ingresados dentro del url. Un ejemplo de esto es www.domain.com/video/search?search=cute+cats. El método head se utiliza para debuggear, ya que hace que el servidor responda enviando un mensaje HTTP pero sin el objeto solicitado. El método PUT sirve para subir objetos a un path especifico de un web server. El método put sirve para subir archivos a un servidor. El método DELETE sirve para borrar objetos de un servidor.
HTTP Response message
La respuesta a la HTTP request enviada anteriormente podría ser:
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 aug 1450 12:12:12 GMT
Server: Nginx/2.1 (NixOS)
Last-Modified: Tue, 18 Aug 2027 14:11:11 GMT
Content-length: 9999
Content-type: video/mkv
(DATA DATA DATA)
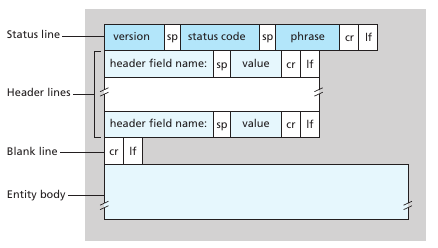
Un HTTP response se compone de tres secciones: status line, header lines and entity body La primera tiene 3 campos, la version del protocolo HTTP, un código de status y un mensaje de status. Las header lines, connection close indica que el servidor va a cerrar la conexión tras enviar el mensaje. La fecha es el momento en que el servidor envió el mensaje. El campo server indica el tipo de servidor que envió el mensaje, las modified indica la ultima vez que se modificó el archivo, esto es importante para el caching. El largo del contenido y el tipo de contenido describen el contenido del entity body.
Ejemplos clásicos de response status son: 200 OK (todo cool), 301 Moved Permanently (Indica que el objeto se movió a un nuevo path, se incluye en Location: el nuevo path, el navegador automáticamente solicita este nuevo URL) y 400 Bad request (error genérico del servidor indicando que no entendió la request), 404 Not Found (no existe el objeto pedido), 505 HTTP Version Not Supported (Al pedir HTTP/8.0)
Cookies
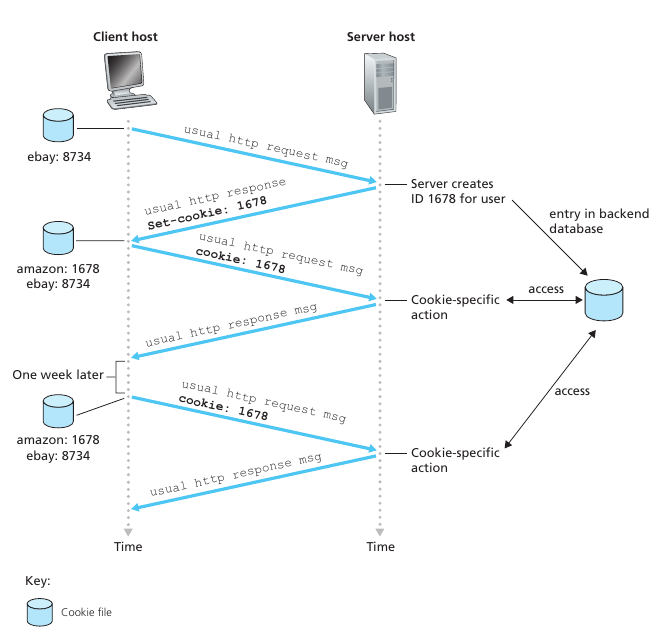
Un servidor HTTP es stateless. Entonces como hacen las webs hoy en dia para identificar usuarios y crear los mecanismos de logins? Respuesta: cookies! La tecnología de las cookies tiene 4 componentes: un cookie header que se encuentra en el HTTP response message, un cookie header line en el HTTP request message, un archivo cookie guardado en el navegador del cliente, y una database en el servidor. Básicamente en el primer contacto el servidor responde con un header Set-cookie: x. El navegador se guarda este x y la próxima vez que haga un request al servidor le va a enviar en el header la linea Cookie: x. De esta forma el servidor puede identificar a un usuario.
Web caching
Un web cache\proxy server es una entidad en la red que satisface HTTP request en nombre de un Web server origen. Un web cache tiene su propio storage y mantiene copias de objetos recientemente solicitados. Un navegador puede ser configurado para que todas sus HTTP requests sean primero dirigidas a un web cache. Básicamente el comportamiento del mismo es: Se envía el request al web cache, el web cache la recibe y se fija sí tiene el objeto. Si no lo tiene le envía un request al servidor origen, cuando el web cache recibe el archivo se lo manda al cliente. Es una herramienta muy util para descongestionar la red y suelen ser adquiridos e instalados por un ISP. Reducen el trafico de la internet en general y el trafico hacia el exterior de una red, lo que reduce notablemente los costos operativos. A su vez, las Content delivery networks (CDN) instalan multiples a lo largo del planeta para localizar y aumentar la efectividad el trafico.
Conditional GET
Como hace el cache para verificar que la copia de un objeto solicitado está actualizada? Este mecanismo se le llama conditional GET. Una request conditional GET utiliza el método GET y incluye la linea en el header: If-Modified-Since: date. El conditional get se utiliza para que el cache le pregunte al servidor si un objeto fue modificado. Dado un objeto cacheado en una fecha d. El cache le envía una request al servidor origen que dice: GET (...) If modified since: d. Luego el servidor le responde con el archivo. Pero si este no fue modificado le va a llegar un header sin contenido, que dice solamente HTTP/1.1 304 Not Modified. Nos ahorramos un montón de trafico!
El correo
El mail service electrónico es uno de las aplicaciones más antiguas de la red. Tiene 3 componentes principales: user agents, mail servers y el Simple Mail Transfer Protocol (SMTP). Los user agents nos dejas leer,responder,etc. mensajes (Ej: Microsoft Outlook, Apple Mail). Mail servers son el core de la infraestructura, cada recipiente tiene su mailbox ubicada allí. Un mailbox administra los mensajes de cada usuario. Ej: Bob escribe un msg en su user agent, lo envía a su mailbox en el servidor, y viaja al mailbox del servidor de destino. Si no se pude enviar el mensaje, los mensajes quedan en una message queue que cada cierto tiempo trata de reintentar. Si no lo logar tras muchos intentos le avisa al usuario que no se pudo.
SMTP es el protocolo para la aplicación de correo electrónico. Utiliza tcp para la transferencia de mensajes. SMTP tiene dos lados: El cliente que es el que ejecuta en el servidor que manda el mensaje y el servidor que es el servidor que tiene el mailbox destino. Un mail server es tanto un cliente y un servidor dependiendo de lo que este haciendo.
SMTP
Es un protocolo muy viejo. Requiere que el contenido de los mensajes sean de 7-bit ASCII. Hay que codificar si quiero mandar fotos por ej... Lo mensajes básicos de SMTP son: A invoca su user-agent y compone un correo. El user agent de A envía el mensaje al servidor, que lo encola. El servidor (cliente SMTP) manda el mensaje al servidor destino. Tras el handshaking, SMTP manda el mensaje al servidor. El servidor de B recibe el mensaje y lo coloca en el mailbox. B invoca su agente para leer el mensaje.
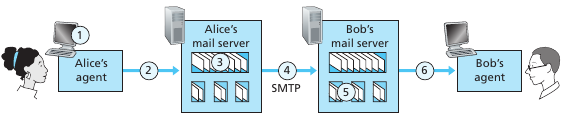
Una diferencia notable con HTTP es que este es un pull protocol, i.e alguien cargar información en un servidor y los usuarios pullean la información a su conveniencia. SMTP es un push protocol, el sending mail pushea un archivo al mail server destino. La conexión TCP es iniciada por la maquina que quiere envíar el archivo. Notar que HTTP se pide de a un objeto. En SMTP podrías poner todos los objetos (fotos por ej) en un solo mensaje.
Ejemplo comunicación de SMTP
S= servidor, C= cliente. Antes se hace un handshaking. La conexión TCP es persistente, se podría envíar mas mensajes. (MAILFROM...) se tiene que cerrar la conexión con el QUIT del cliente.
S: hamburger.edu
C: HELO crepes.fr
S: 250 Hello crepes.fr, pleased to meet you
C: MAIL FROM: <alice@crepes.fr>
S: 250 alice@crepes.fr ... Sender ok
C: RCPT TO: <bob@hamburguer.edu>
S: 250 bob@hamburguer.edu ... Recipient ok
C: DATA
S: 354 Enter Mail, end with "." on a line by itself
C: Do you like MEAT?
C: How about Sausages?
C: .
S: 250 Message accepted for delivery
C: QUIT
S: 221 hamburger.edu closing connection
Formato SMTP
Al envíar el mensaje antes se incluye un header. El header está separado por una linea CRLF. El header tiene que tener necesariamente los siguientes valores (mismo formato http): From: y To: Para indicar de quien y a donde es el mensaje. Ej de header:
From: guille@mailbox.acc.com
To: annie@lol.com
Subject: Poggers
Acceso al mail server
Observar que en la mayoria de los casos el user agent de los usuarios reside en los dispositivos de los mismos y el mail server es un servidor contratado y mantenido por una compañía. También observar que "A" desde su user agent le enviá por SMTP el correo a su mailbox, y luego el servidor usa SMTP para enviar el correo al servidor destino. El user agent no habla directo con el servidor destino porque si el mensaje falla en envíar no podría encolarse ya que el user agent no tiene por que estar siempre online.
Ahora bien, como accede B a sus correos desde el user agent? Como SMTP es un push protocol no puede utilizarlo para recibir datos. Debe usar otros: Post Office Protocol V3 POP3, Internet Mail Access Protocol IMAP or HTTP.
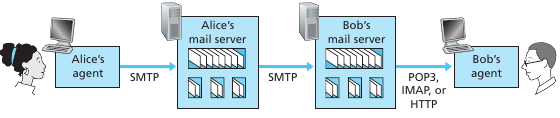
POP3
POP3 es un protocolo simple y legible. Su simpleza la da funcionalidad limitada. Al establecer la conexión TCP, POP3 tiene 3 etapas:
- autorización: El user agent manda un username y un password (no encriptado) para autenticar
- transacción: El user agent recibe mensajes, puede marcar mensajes para borrar, obtener estadisticas para el mail o deshacer los mensajes marcados para borrar
- update: Ocurre tras invocar "quit", cierra la sesión POP3 y el servidor borra los mensajes seleccionados.
El servidor siempre responde "+OK\ -ERR" dependiendo de lo que envía el usuario. Ejemplo de login en POP3: telnet mailsrv 110 +OK POP3 server ready user bob +OK pass hungry +OK user successfully logged on
La transacción puede ser download and delete o download and keep. En la primera al pedir un mensaje luego se borra, en la anterior el agente de usuario deja el mensaje en el mail server tras descargarlo (recordar que el user agent es un programa)
C: list
S: 1 498
S: 2 912
S: .
C: retr 1
S: (texto)
S: (texto)
S: .
C: dele 1
C: retr 2
S: (texto)
S: .
C: dele 2
C: quit
S: +OK POP3 server signing off
IMAP
IMAP es un protocolo más complejo que permite a los usuarios crear/borrar y mover carpetas y en ellas mismas almacenar mensajes. Cuando un mensaje llega al servidor se guarda en la carpeta por defecto inbox. El recipiente luego la puede mover a donde quiera. Esta estructura de carpetas es remota y el usuario puede acceder desde cualquier user agent a sus carpetas. Una funcionalidad importante es que IMAP tiene la capacidad de recibir solo algunos componentes de un mensaje (ej el header) esto es relevante en conexiones lentas.
HTTP
Es la forma más usada hoy en dia, se accede al correo a través de un navegador web. El usuario se comunica con el mailbox via HTTP. Tanto para envíar como recibir mensajes se puede utilizar este protocolo. Sin embargo para la comunicación entre servidores de correo electrónico se sigue usando SMTP
DNS - The internet's directory service
Las maquinas se identifican por IP address ya que es size-fixed y numérico, pero los humanos nos gusta identificarlas por su memonico hostname. Es necesario entonces un mapping $I \leftrightarrow H$. Esta es la tarea del Domain Name System (DNS). El DNS es una base de datos distribuida implementada en una jerarquía de servidores DNS + un application-layer protocol que permite a los host hacer queries a la base de datos. El DNS usa el protocolo UDP en el puerto 53. Tiene la particularidad que es una aplicación que es utilizada por protocolos de otras aplicaciones (HTTP, SMTP) para resolver los hostnames. Un pedido con http con hostname sigue estos pasos:
- El usuario, que corre el lado cliente de la app DNS y tiene un navegador, extrae el hostname de la URL y se lo pasa al cliente DNS.
- El cliente DNS envía una query con el hostname al servidor DNS
- El DNS client recibe (idealmente) una respuesta, que incluye la IP del hostname
- Con la ip del hostname el navegador inicia una conexión TCP para el proceso HTTP en el puerto 80 de dicha IP.
Funcionalidades DNS
Host aliasing: Un host con un nombre complicado como "relay1.weswer23.google.com" puede tener muchos aliases como "google.com" o "goGle.com". El primer hostname se le llama canonical hostname. El DNS puede ser invocado para obtener el canonical hostname de un alias y su IP.
Mail Server Aliasing: Se utiliza para obtener lo que va después del @. Se utilizan aliases. Ademas el aliasing permite que el servidor web de una compañía tenga el mismo alias que el servidor mail de esta.
Load Distribution: Se puede asociar muchos ip address a un alias. Cuando un cliente hace una query del hostname el servidor DNS responde con todo el set de IPs pero va rotando el orden de la lista de ips, de esta forma se logra un balanceo natural entre los servidores (por lo general un cliente envía la HTTP request de el primer IP de la lista)
Overview
El servidor dns funciona como una caja negra para el cliente, el pide y recibe. Pero en realidad cuando al servidor le llega una request, al ser una base de datos distribuida hay un mecanismo de comunicación complejo. Por que no se optó por hacer un único servidor centralizado? Respuesta: Si se rompe nos quedamos sin internet, el trafico sería inmensurable, los que están lejos se joden, mantenimiento de algo gigante que debe actualizarse frecuentemente.
It simply doesn't scale.
Para encarar con el problema, DNS usa muchos servidores organizados en una estructura jerárquica. No hay ningún servidor que tenga todos los mappings de los hosts. El mapping se distribuye entre los servidores DNS. Existen 3 clases de servidores DNS:
- Root DNS Servers: Existen unos 400 alrededor del mundo, administrados por 13 organizaciones (Kurose,2016?). Estos proveen las IP de los servidores TLD
- Top-level domain (TLD) servers: Para cada top-level domain (ej: com, org, net, edu, moe, etc.) incluyendo los nacionales (uy ,us ,jp ,uk, etc) hay un servidor TLD (o un cluster).
- Authoritative DNS server: Cada organización con hosts públicos en la internet debe tener un registro DNS publico que hace el mapping del el nombre de sus hosts a un IP address. El authoritative DNS server de cada organización se encarga de ellos. Alternativamente, una organización puede pagarle a alguien para que sus hosts sean publicados en el servidor authoritative DNS de un tercero.
Cuando un cliente quiere la ip de nootnoot.org primero el cliente contacta uno de los servidores root, el cual retorna la ip address de un TLD server para el dominio ".org", luego el cliente contacta con ese servidor TLD el cual retorna el authoritative server de nootnoot.org, el cual al ser contactado por el cliente devuelve el address de 4chan.org
Existe un servidor DNS fuera de la jerarquía: el local DNS server. Cada ISP tiene un local DNS (aka default name server). Cuando un host se conecta a un ISP esta le provee las IP de sus servidores dns locales. No suelen estar muy lejos (en path) del host. Cuando un host hace una query, esta es envíada al servidor DNS local, la cual actúa como un proxy forwarding la query en la jerarquía de servidores. Ejemplo de query dns:
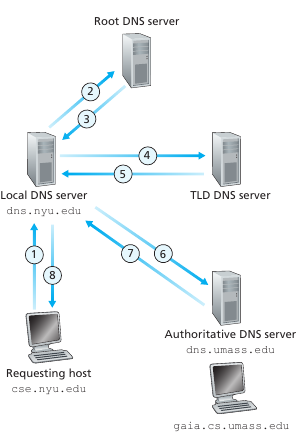
Se le llama recursive queries a aquellas que se mandan y luego el cli habla con otro o la procesa iterative queries a las que se hace una query, responde y luego se hace otra. Ejemplos (la segunda es toda recursiva):
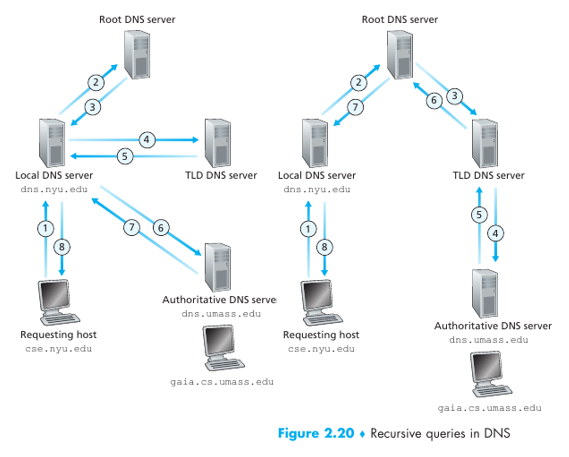
DNS Catching
Se usa caching para evitar delay de performance, y reducir los mensajes en la red. Básicamente cuando un servidor recibe la ip de un host esta se la puede guardar, cuando viene otro por el mismo host le puede devolver la ip que había guardado! Yay! Los elementos se van descartando a medida que van pasando los dias, de esta forma toda la jerarquía de servidores dns puede ser evitada y solo utilizar el local dns para los hostname mas populares.
DNS records
Los DNS servers guardan en la base de datos resource records (RR), incluyendo RR's que tienen H<>IP mappings. Cada mensaje de respuesta DNS lleva 1 o más RRs. Un resource record es una cuaterna que contiene:
$(Name, Value, Type, TTL)$ TTL es el tiempo de vida del RR. Indica cuando debe ser borrado del cache. Type indica el tipo:
- Type = A: Indica que Name es el hostname y value es la IP del hostname. Es el preciado H<>IP
- Type = NS: Indica que Name es un dominio y value es el hostname del DNS autoritario que sabe como obtener dicha IP
- Type = CNAME: Indica que Value es el canonical hostname para el hostname alias Name. Ej (foo.com,relay1.foo.com,CNAME,18273)
- Type = MX: Indica que Value es el canonical name server que tiene como alias el hostname Name. (Servidores de correo que sirve para ese dominio (gmail.com, alt4.gmail-smtp-in-l.google.com)) El DNS authoritative de un hostname tiene un un type A RR de este. Otros pueden tenerlo en su cache.
DNS Messages
Tanto las query como las reply tienen el mismo formato de mensaje:
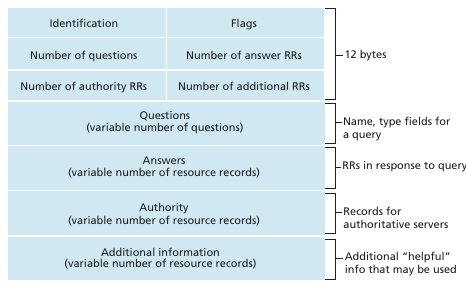
Los primeros 12 bytes son de la sección de header. Los primeros 16 bits identifican la query, permitiendo al cliente matchear la respuesta con la identificación. Una flag de 1 bit marca si el mensajes una respuesta (1) o una query (0). Una flag de 1 bit se settea cuando el que responde es el DNS authoritative. 1 bit flag indica si el que hace la query le gustaría que el host haga recursión. Luego hay 4 campos con números que indica la cantidad de secciones de cada tipo que hay
La sección question contiene información sobre la query que se esta haciendo. Contiene:
- Namefield: name that is being queried
- Type: type of question being asked about the name
Cuando es una respuesta del servidor DNS, la answer section contiene los RR del nombre que fue queried.
La authority section contiene los RR de otros servidores autoritarios
La additional section contiene otros RR útiles. Por ejemplo si es una MX query puede contener el canonical hostname del mail server y contiene un type A record con el ip del canonical hostname.
Insertar un registro a una DNS
Para ello tenes que pagarle a un registar. Cumplir todas las condiciones (no esta en uso el hostname.com etc). Para registrar un hostname se debe proveer los nombres e ips de tu dns authoritative primario y secundario. El registar se va a asegurar que un RR tipo NS y tipo A sean ingresados en el TLD .com server. Ponele que tu dns authoritative es dns.hostname.com con ip 123.123.123.1 entonces el registar ingresara al TLD DNS: (dns.hostname.com,123.123.123.1) y (hostname.com,dns.hostname.com, NS). Ahora existe un protocolo que permite actualizar los servidores dns, pero antes lo hacia alguien de forma manual.
P2P
Se puede probar matemáticamente la escalabilidad de las redes P2P frente a las server/client (ver Kurose). Es una arquitectura alternativa que se basa en que no siempre los hosts van a estar disponibles y en una aplicación en cada sistema se encuentran las partes cliente y servidor.
BitTorrent
BitTorrent es un protocolo p2p popular para distribuir... archivos. La colleccion de compas participando en la distribución de un archivo se le llama torrent. Peers en un torrent descargan chunks de un archivo y se los distribuyen entre ellos, tanto envíando como recibiendo. Un peer siempre puede salir del torrent, o puede volver.
Como me conecto con los peers? Cada torrent tiene un nodo cliente/servidor llamado tracker. Cuando un peer se une se registra en el tracker y le informa periódicamente que siguen el torrent. El tracker entonces tiene la lista de todos los peers del torrent en un momento dado.
Cuando un nuevo peer se uno el tracker le manda un subconjunto de peers. El nuevo peer trata de establecer una conexión TCP con todos los peers (concurrentemente). Los otros peers que aceptan la conexión se llaman neighbouring peers. Con el tiempo el subset de neighbouring peers va cambiando, estos son los que se mandan las chunks. Las chunks se piden según el criterio rarest first maximizando la integridad de un archivo. Dado un peer, a quien le manda chunks. Bit torrent sigue un algoritmo de negociación que en esencia se basa en que los top x que más datos me mandaron yo también les voy a mandar y a los otros los tengo ahi, si alguno me empieza a mandar y sube al top x entonces le voy a empezar a mandar a el. A los peer que se les manda chunks se llaman unchoked, los que están chocked y reciben chunks se les llama optimistically unchoked ya que podría subir.
Video Streaming
El video consume muchos recursos de la preciada internet. Para que todos los usuarios puedan acceder a ver el video, creamos muchas versiones del video a distintos bitrate. Los usuarios pueden decidir cual quieren en función de su ancho de banda disponible.
DASH
In HTTP streaming, the video is simply stored at an HTTP server as an ordinaryfile with a specific URL. When a user wants to see the video, the client establishes a TCP connection with the server and issues an HTTP GET request for that URL. The server then sends the video file, within an HTTP response message, as quickly as the underlying network protocols and traffic conditions will allow. On the client side, the bytes are collected in a client application buffer. Once the number of bytes in this buffer exceeds a predetermined threshold, the client application begins play- back—specifically, the streaming video application periodically grabs video frames from the client application buffer, decompresses the frames, and displays them on the user’s screen. Thus, the video streaming application is displaying video as it is receiving and buffering frames corresponding to latter parts of the video.
Esto tiene el problema de que todos los clientes reciben la misma version del video, a pesar de sus distintos throughputs. Por ello se desarrollo un nuevo tipo de HTTP: Dynamic Adaptative Streaming over HTTP (DASH). En DASH, el video es codificado en muchas versiones con distinto bitrae. El cliente pide dinamicamente los chunks (segmentos de video muy cortos). Cuando hay buen troughput el cliente pide la version 4k cuando hay malo se conformará con 144p. En cada HTTP GET puede elegir el chunk.
El servidor HTTP tiene un manifest file donde indica las URL de cada video con su bitrate. Primero el cliente pide el manifest file y mira las versiones. Luego pide un chunk por vez y corre un algoritmo para determinar cual chunk sera pedido la próxima vez (toma en cuenta el throughput y el video que ya hay buffereado). Lo que se quiere evitar es siempre la interrupción del video.
Content Distribution Networks (CDN)
Los datos pesados como imágenes y videos realmente son una carga para la red. Las compañías para mejorar la performance y poder distribuir esta cantidad masiva de datos utilizan content delivery networks (CDN). Un CDN tiene muchos servidores en todo el mundo con copia de objetos en sus servidores, cada request que recibe la trata de redirigir al servidor que le va a dar una mejor experiencia al usuario. Las CDN pueden ser privadas (google) o de terceros (le pagas a ellos, también son privadas en en ámbito del derecho publico). Existen dos filosofías para las CDN
- Enter Deep: Básicamente poner nodos por todas las isp posibles, muchos servidores y clusters por el mundo.
- Bring home: Poner los clusters donde importan, las isp van a venir. Se ponen los clusters en IXP y lugares para que las ISP se conecten.
Las CDN tienden a replicar su contenido entre losclusters. Sin embargo, no tiene por que querer una copia de cada video que casi nadie vaa mirar. Para ello usan una pull strategy: Si un cliente pide un video a un cluster que no tiene el video, el cluster consigue el video y se guarda una copia de este mientras lo streamea al cliente. Cuando se queda sin espacio se deshace de videos.
CDN Operation
Cuando un host pide un video (URL), la CDN tiene que interceptar la request para determinar el cluster CDN apropiado para ese cliente y redirigir el cliente a un servidor del cluster. Como es esto de interceptar? Las CDNs toman ventaja del DNS para hacer esta interceptación. Básicamente al pedir por un hostname, al llegar al dns authoritative lo que hace es darle la ip devuelve el hostname de uno de los servidores de la CDN al Local DNS. Entonces la LDNS hace el DNS query al CDN y luego este le da la ip de un servidor seleccionado por este. Finalmente el LDNS le devuelve la cdn al host. La secuencia de llamadas se muestra en la siguiente imagen:
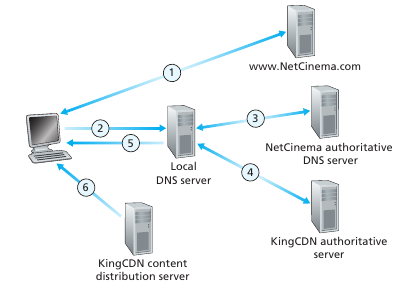
Cluster Selection
Para elegir el mejor servidor de un cluster se emplean diversas estrategias. Desde geographically closest, la cual tiene la contra de que no siempre el que esta más cerca tiene el network path más cercano. Y real-time measurements donde los CDN envían "sondas" a los LDNS del mundo, para testear la velociad de conexión. El problema es que muchos LDNS están configurados para no responder a ninguna sonda (Las sondas que llegaron nunca volvieron...)
Socket Programming
En el desarrollo de aplicaciones existen dos tipos: Las que sus protocolos están especificados en un standard abierto (RFC) y las aplicaciones en red propietarias, que usan sus propio protocolos que no son públicos. Una de las primeras decisiones que debe tomar un desarrollador es si su app va utilizar TCP o UDP.
Socket programming in UDP
Consideraciones:
- Antes de enviar un mensaje por un socket, se tiene que agregar la dirección de destino del paquete. Esto es: La dirección IP del destino y el puerto (ya que varias aplicaciones pueden estar corriendo en el servidor). También se agrega el IP address y el puerto de quien envía el paquete aunque esto no lo hace explicitamente el programador pero el sistema operativo.
Ejemplo:
UDPClient.py:
from socket import *
serverName = ’hostname’
serverPort = 12000
clientSocket = socket(AF_INET, SOCK_DGRAM)
message = raw_input(’Input lowercase sentence:’)
clientSocket.sendto(message.encode(),(serverName, serverPort))
modifiedMessage, serverAddress = clientSocket.recvfrom(2048)
print(modifiedMessage.decode())
clientSocket.close()
observar que se crea un objeto "socket". El parametro AF_INET indica que se usará la red ipv4 y SOCK_DGRAM que el protocolo será UDP. No se elige el numero de socket. El sistema operativo nos asigna uno disponible. Observar como el sendTo del socket toma tanto el mensaje y la dirección. Esto es todo lo necesario para establecer una comunicación. recvFrom espera a que llegue un paquete al socket. Finalmente se libera el socket.
UDPServer.py:
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_DGRAM)
serverSocket.bind((’’, serverPort))
print(”The server is ready to receive”)
while True:
message, clientAddress = serverSocket.recvfrom(2048)
modifiedMessage = message.decode().upper()
serverSocket.sendto(modifiedMessage.encode(), clientAddress)
La diferencia notable es que al socket se le hace un binding del puerto que queremos. Se asigna un puerto de manera explicita.
Socket programming in TCP
Unlike UDP, TCP is a connection-oriented protocol. This means that before the client and server can start to send data to each other, they first need to handshake and establish a TCP connection.
Al crear la conexión TCP nos asociamos los puerto,ip del servidor cliente. Luego tras establecer la conexión ambos lados pueden tirar paquetes al stream por el socket. Esto es diferente a la forma de pensar en mensajes.
Para crear una conexión TCP el servidor tiene que estar listo. Es decir debe estar corriendo antes que el cliente, que es el que inicia el handshake, pida la conexión. Además el servidor tiene que tener un socket especial para darle la bienvenida al host. El cliente se comunica con este socket para iniciar el handshake. Cuando el servidor recibe el primer handshake crea un nuevo socket dedicado al cliente que inicio el handshake. Este nuevo socket es la tubería que nos permite acceder al stream. Es importante notar que hay dos sockets del lado del servidor. El welcoming socket y el del stream (el cual es único para cada cliente). El cliente tiene un solo socket.
TCPCLient.py:
from socket import *
serverName = ’servername’
serverPort = 12000
clientSocket = socket(AF_INET, SOCK_STREAM)
clientSocket.connect((serverName,serverPort))
sentence = raw_input(’Input lowercase sentence:’)
clientSocket.send(sentence.encode())
modifiedSentence = clientSocket.recv(1024)
print(’From Server: ’, modifiedSentence.decode())
clientSocket.close()
Observar que ahora se usa SOCK_STREAM para crear el socket, esto indica que es TCP. El SO se encarga de asignar el puerto. el socket.connect es el que inicia la conexión TCP. Notar que el send no recibe la dirección, el programa simplemente tira los bytes en el socket. No hay mensajes. Luego el socket del cliente se cierra (le avisa al servidor que va a cerrar la conexión TCP).
TCPServer.py:
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET,SOCK_STREAM)
serverSocket.bind((’’,serverPort))
serverSocket.listen(1)
print(’The server is ready to receive’)
while True:
connectionSocket, addr = serverSocket.accept()
sentence = connectionSocket.recv(1024).decode()
capitalizedSentence = sentence.upper()
connectionSocket.send(capitalizedSentence.encode())
connectionSocket.close()
aquí serverSocket es el welcoming socket y connectionSocket es el del stream. Notar como el welcoming socket ejecuta listen. El cual hace que se quede esperando a que alguien toque la puerta. (el parametro especifica el maximo de conexiones encoladas (hmm)). Cuando un cliente toca la puerta el servidor invoca accept() y crea el nuevo socket dedicado al cliente. Se completa el handshaking y el stream queda establecido. Luego se cierra el socket.
Parte III - Transport Layer
La función clave de la capa de transporte es: Extender el servicio de delivery de la capa de red entre dos sistemas finales a un servicio entre dos procesos de la capa de aplicación corriendo en dos sistemas finales.
Adicionalmente, se trata sobre los distintos servicios que pueden ofrecer este sistema. Siempre recordando que los servicio que pueden proveer están limitados por los servicios de las capas de abajo. Si la capa de red no ofrece minimos delays, la capa de transporte tampoco. Sin embargo, existen servios que puede proveer utilizando compleja ingenieria: Como control de congestion, y connection reliability. Recordar que si bien es la capa de transporte la que provee estos servicios, cualquier otra capa lo pudiese haber hecho. Los protocolos de congestion de TCP son un tema de estudio, estos evolucionan a lo largo de los años. UDP y TCP son los caballos de batalla de la internet, pero han estado surgiendo otros protocolos en los últimos años:
DCCP (data congestion control protocol): low-overhead, message-oriented, UDP-like unreliable service. Pero con un sistema de congestion compatible con TCP.
QUIC (Quick UDP Internet Connections) Protocol : provides reliability via retransmission as well as error correction, fast connection setup and rate based congestion control algorithm aiming to be TCP friendly. Todo esto implementado como un application level protocol sobre UDP.
DCTCP (Data Center TCP): Version de TCP diseñada para redes de datacenters.
SCTP (Stream Control Transmission Protocol). Reliable message-oriented protocol that allows several different application-level "streams" to be multiplexed through a single SCTP connections. Implementa funcionalidades adicionales como multi-stream opt in out-of-order-data, etc/
TFRC (TCP Friendly Rate Control) Protocol. Protocolo de congestion solamente (como DCCP), tiene como objetivo ser más smooth que TCP en cuanto al control del sending rate.
Intro and Transport-Layer Services
Un transport protocol provee comunicación lógica entre dos procesos de aplicación en distintos hosts. Esto es, los host corren procesos como si estuviesen directamente conectados (ignoran por todos los routers que deben pasar). Los protocolos de transporte se implementan en los sistemas finales. Al enviar paquetes, la capa de transporte convierte los mensajes de las aplicaciones en paquetes de la capa de transporte llamados segmentos. Por lo general se parte el mensaje en pequeños paquetes para generar estos segmentos. Luego la capa de transporte le pasa estos segmentos a la capa de red del mismo host (encapsulando este segmento en un datagrama) para transportar los segmentos al host final - desde el protocolo de red.
Mientras que el transport layer procesa la comunicación lógica entre procesos. corriendo en distintos hosts, la capa de red provee comunicación lógica entre hosts. El libro usa una based analogy de 2 casas con niños que se mandan cartas. Las mamás de cada casa levantan las cartas de los niños y se las mandan al correo postal, a su vez levantan las cartas que el correo postal dejó para su casa, y se las da a los respectivos niños destinatarios. Para los niños, la mamá es todo el sistema de transporte de cartas, no conocen el servicio postal. A su vez, distintas mamás pueden ser distintas, algunas pueden llevar la cuenta de las cartas que envían y avisarle a sus hijos que su amigo recibió todas, mientras que otras solamente mandan la carta y poco le importa si llega bien o no. Por otro lado las madres están limitadas por el servicio postal, si el servicio postal no puede prometer que las cartas se envíen en menos de 3 días, ellas tampoco.
En internet tenemos dos grandes: TCP y UDP. Cabe destacar que si bien los transport layer packets son segments y los network layer packets son datagrams, en las RFC se usa datagram para los paquetes UDP (Para tener en consideración).
IP es el protocolo de red que provee comunicación lógica entre los hosts. El modelo de servicio IP se le llama best-effort delivery service, ya que hace lo mejor que puede pero no ofrece ninguna garantía: Los paquetes pueden nunca llegar, pueden alterarse (integridad) e incluso llegar en distinto orden. En este sentido el protocolo IP es un unreliable service. Muchos protoclos de trasporte tratan de enmendar esto, o mejor dicho, dar servicios adicionales.
La funcionaliad clave del protocolo de transporte: Extender host-to-host delivery -> process-to-process delivery se le llama transport layer multiplexing/demultiplexing.
Multiplexing & Demultiplexing
Cuando estamos en zoom y miramos un video de youtube, nos llegan paquetes (host) de parte de varias aplicaciones, es responsabilidad del transport protocol enviarselos al proceso correspondiente. Para llevar esto a cabo se usan sockets. Por lo tanto, el protocolo de transporte no envía los mensajes directamente al proceso pero a un socket que esta asignado a uno.
Se le llama demultiplexing al trabajo de enviar los datos de un segmento al socket correcto. El trabajo de juntar chunks de datos, encapsularlos ( agregarle información (ej. socket destino) transformarlos en segmentos) y envíarlos al network-layer para que viajen se le llama multiplexing. Para hacer este trabajo se necesitan dos piezas esenciales:
- Los sockets deben tener un identificador único (o por lo menos una forma de)
- Cada segmento debe tener información relativa al socket al cual debe ser envíado. (Esto es Source port number field y le Destination port number field. )
Un puerto en un host se identifica con un 16ibt number (0-65535). Los puertos del 0 al 1023 se les conoce como well-known port numbers y están restringidos a protocolos conocidos. (EJ: HTTP 80, FTP 21, etc.). Notar que $puerto \neq socket$ . Mientras que un socket es una estructura para que un proceso reciba/envíe mensajes, un puerto es simplemente un número que potencialmente puede identificar a un socket. A su vez los sockets dependen del protocolo de transporte: No es lo mismo el TCP port 80 que el UDP port 80.
En un segmento UDP, se manda el source port, destination port y dos valores adicionales. Con esto queda determinado el socket. El source port se usa para que la aplicación que le llega el mensaje sepa a que puerto envíar un mensaje si desea responder. Para demultiplexar basta con mirar el destination port para saber a cual socket UDP envíar el segmento. Por lo tanto un socket UDP está definido de forma única por la tupla IP dest Address y Destintation Port.
Por otro lado, en TCP un socket queda definido por una 4-upla: $< source\ IP\ address,\ source\ port\ number,\ destination\ IP\ address,\ destination\ port\ number>$ . De esta forma tenemos dos sockets diferentes para dos hosts que hablan con el puerto 80 de un webserver. La excepción de esto se da en los primeros segmentos TCP que contienen el pedido original de conexión. Cuando un servidor receive un incoming connection-request segmento en un cierto puerto, este localiza los procesos que estas esperando para aceptar una conexión en dicho puerto, luego de aceptarla se crea un nuevo socket que establece un túnel de comunicación entre ambas partes.
Nmap es una utilidad que nos permite ver los puertos abiertos/cerrados y deshabilitados de un host de internet. Los puertos abiertos son necesarios para enviar menajes por internet, pero son una puerta de acceso rapido a un sistema y atacarlo si se puede acceder desde un puerto a aplicaciones vulnerables.
Connectionless Transport: UDP
UDP hace casi lo minimo indispensable para implementar un protocolo de transporte: Multiplex/Demultiplex and a little error checking. UDP se le conoce como connectionless ya que no hay handshaking, son puramente mensajes que se envían de un puerto a otro. Una aplicación que utiliza UDP, cuando envía un mensaje y no recibe un mensaje tras cierto tiempo, puede hacer lo siguiente: Reenviar el mensaje, probar otro host (si aplica), avisar que no tuvo éxito. Ahora bien, si TCP es confiable para que existe UDP?? Hay aplicaciones en las que UDP is better suited for the following reasons:
Finer application-level control over what data is sent, and when: Al enviar un mensaje con UDP, UDP empaqueta el mensaje en un segmento UDP y se lo manda de una al network layer. TCP por otro lado hace control de congestión y renvía los segmentos hasta que el que los recibe haga un acknowledge. Muchas aplicaciones en tiempo real quieren un sending rate minimo (que no los frenen), que no haya casi delays y toleran que se pierdan datos. Para estas aplicaciones UDP cubre mejor sus necesidades que TCP.
No connection establishment: El three-way handshake produce un delay muchas veces indeseable. Por ejemplo, el servicio DNS sería mucho mas lento si usara TCP (con UDP es tan solo dos paquetes que viajan!). En la Web se usa TCP para no perder información, pero incluso se están creando protoclos como QUIC que usan UDP e implementan la reliability por encima de UDP.
No connection state: TCP requiere almacenar variables por cada conexión: buffers, congestion-control parameters, sequence and ack parameters, etc. UDP no mantiene ningún estado ni seguimiento de parametros. Por lo tanto un servidor puede tener muchos mas clientes activos por UDP que TCP.
Menor overhead en el header del paquete: Un segmento TCP tiene un header de 20 bytes por cada segmento. Mientras que uno UDP tiene tan solo 8 bytes. Wow!
Según Kurose, UDP es un protocolo controversial, ya que no tiene control de congestion y el uso de UDP está en detrimento de las conexiones TCP cuando la red está saturada. Por ello, el uso de UDP en realidad no contribuye pero empeora el esfuerzo de mantener la red saludable. Incluso peor es el hecho de que no es necesario TCP para tener una aplicación con transmisión de datos confiable si este implementa sus controles por encima de UDP (QUIC), resultando en protoclos con las ventajas de UDP pero con la reliability de TCP.
UDP Segment Structure
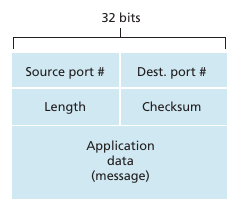
Se necesita un length field ya que el tamaño del campo data es variable. La checksum se utiliza para verificar que no se introdujeron errores en el segmento. En length field incluye el tamaño del header. El checksum se realiza haciendo el 1s complement de la suma de todas las 16bit words del segmento. UDP implementa corrección de errores a pesar de que capas más abajo lo implementan (ej ethernet) ya que nada asegura que no haya algún link sin error-checking. Esto es un caso del end-to-end principle el cual indica que ciertas funcionalidades (corrección de errores) deben ser implementadas en una end-end basis. Recordar que UDP no hace nada para recuperarse en el caso de que la checksum de mal. Simplemente no hace nada o le envía una warning a la aplicación.
Functions placed at the lower levels may be redundant or of little value when compared to the cost of providing them at the higher level.
Principles of Reliable Data Transfer
Como podemos implementar un reliable data transfer protocol? En el libro se hace un proceso incremental de una maquina de estados hasta un protocolo que soporta pipelining.
La siguiente maquina de estados muestra un protocolo que implementa reliable data transfers. Los paquetes pueden corromperse y nunca llegar y esto no sería un problema. La lógica del mismo es:
Mando un paquete con secuencia 0. Espero que me llegue un ACK de la secuencia 0 y setteo un timer. Si me llega algo corrupto o de otra secuencia no hago nada. Si se da timeout reenvío el paquete. Si me llega el ACK del seq 0 paro el timer y queda confirmo que el paquete que envié llegó a su destino :^).
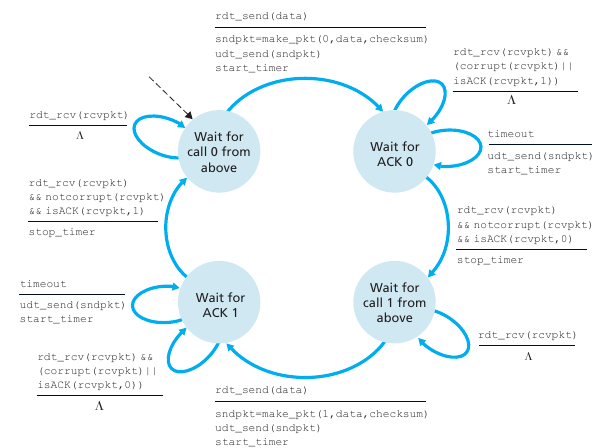
El protocolo de la image es un alternating-bit-protocol. Notar que tras envíar un paquete nos quedamos esperando el acknowledge (zzz). Muy ineficiente... de ahi surge la idea del pipelining, que consiste en enviar varios paquetes sin esperar el acknowledge. Ahora surge el desafío de implementar un protocolo que soporte reliable pipelining. Para llevar a cabo esto:
- Los números de secuencia ahora deben ser enteros ya que se debe llevar la cuenta de los paquetes que están en transito y no fueron ACK.
- El sender y el receiver tendrán que bufferear más de un paquete. El rango de paquetes buffereados depende de la estrategia a utilizar para responde cuando se pierde, corrompe o retrasa un paquete. Las dos estrategias básicas son Go-back-N y Selective repeat (SR).
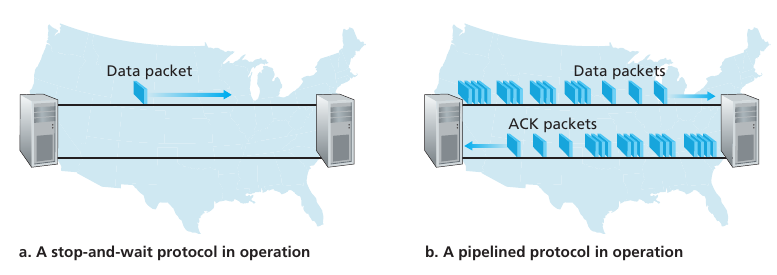
Go-back-N (GBD)
Ver: java applet
En el go back N el sender manda hasta N paquetes en un rango sin esperar el acknowledge. Esto crea una ventana de tamaño N con espacios para bufferear paquetes que todavía no recibieron el ACK. Por ello se le llama al protocolo sliding-window protocol. Cuando el servidor recibe el paquete este le manda el ACK. Ahora bien, lo intersante de esta estrategia es lo que pasa cuando algún paquete se pierde o se corrompe. En primer lugar, el receiver espera una secuencia especifica de paquete. Por ejemplo, si está esperando el 0 y le llega el 1, simplemente descarta el paquete. Va a esperar el seq0 para mandar un ack0. La complejidad reside entonces en el sender: La ventana se mueve a medida que se recibe los ack de los primeros paquetes del buffer, ahora bien si recibimos un ack de un paquete mayor al que estabamos esperando, entonces sabemos que los paquetes anteriores a este se recibieron, por lo que el sender no espera estos acknowledge y los da por enviados (cumulative acknowledgement). Ahora bien, el primer paquete del buffer al enviarlo se settea un timer. Cada vez que llega el paquete al cual se le setteó el timer este se vuelve a resetear (si es que hay paquetes enviándose). Ahora bien, en caso de timeout lo que hace el sender es enviar todos los paquetes que están esperando un acknowledge una vez más. (y se reinicia el timer). Con esta técnica, aunque un poco ineficiente, se implementa un reliable pipelining. La implementación de estas técnicas requiere event-based programming.
Selective Reapeat (SR)
Ver: java applet
SR va un paso más allá en cuanto a eficiencia y permite que el receiver aceptar paquetes de un seq mayor al que se esperaba. Este los bufferea. A su vez, si se vuelve a mandar un paquete seq que ya fue aceptado se vuelve a enviar un ack. Por el lado del sender, tenemos un timer para cada paquete esperando un ack, si hay timeout se vuelve a envíar solamente ese paquete. Como ahora el receiver acepta todos los seq dentro de una ventana, ya NO tenemos cumulative acknowledgement. Notar que ahora hay dos ventanas buffer que no necesariamente están sincronizadas.
Para solucionar el problema de que los paquetes pueden llegar fuera de orden se utiliza los seq siempre asegurando que hay un único seq x viajando en la red. Para esto el protocolo asume que un paquete no puede "vivir" en la red por un periodo arbitrario de tiempo (En TCP es 3 minutos, este usa 32bit sequence number).
La siguiente imagen muestra los aspectos calves del reliable data transfer:
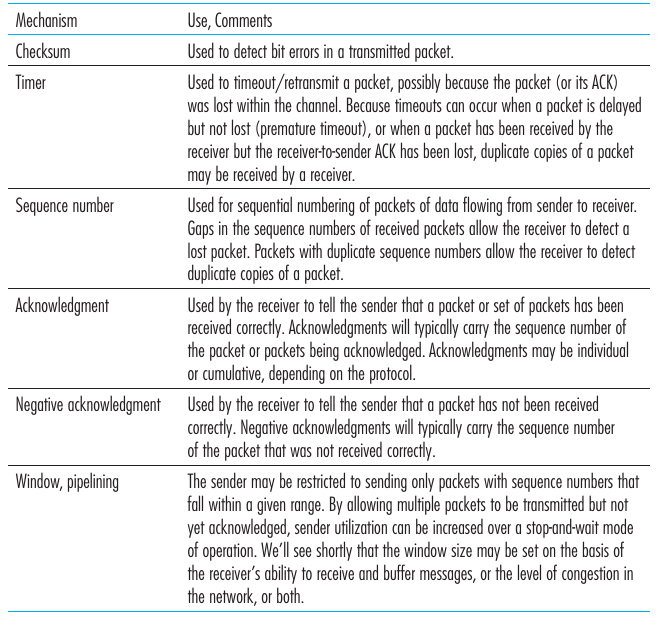
Connection-Oriented Transport: TCP
Características TCP
- Connection-Oriented: Antes de enviarse data entre dos hosts, estos tiene que hacer un "handshake", el handshake permite establecer los parametros y asignar buffers/variables que implementan la reliable data transfer.
- Conexión lógica: Solamente los end-systems conocen la conexión. Los routers solamente ven datagramas.
- Full-duplex-service: Los datos pueden fluir en ambos sentidos.
- Point-to-point: Los datos siempre viajan de un host a otro unicamente. (No hay multicasting)
Esta conexión se crea a través del 3-way hanshake que ya se vió. Tras establecer la conexión ya es posible enviar datos. TCP redirige los datos que se envían a un Send buffer. Cada cierto tiempo TCP agarra chunks de este buffer y las envía a la capa de red. La cantidad de datos que pueden colocarse en un chunk se le llama maximum segment size (MSS). Este se determina en base a la capacidad del link-layer frame más grande del host (aka maximum transmission unit MTU). Cada chunk de datos se empareja con un TCP header, asi construyendo el segmento TCP, el cual es envíado al network layer. Recordar que MSS es el maximo contenido de application data en el segmento sin incluir los headers. TCP tiene que tener en cuenta el tamaño del header para poder meterlo en un frame (MTU). Cuando llega un segmento de la red, TCP lo coloca en el receive buffer. La aplicación puede leer este stream de datos cuando le plazca.
TCP Segment Structure
Un segmento TCP consiste en un campo header y un campo datos. MSS limita el tamaño del data field. La estructura de un segmento se ilustra en la siguiente imagen:
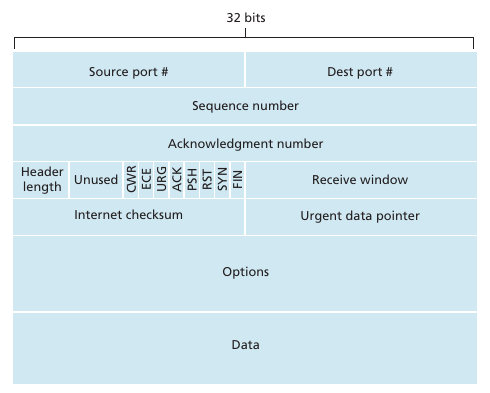
Se pueden visualizar los siguientes elementos:
- Source and destination ports: Son necesarios para multiplexar/demultiplexar los segmentos a las distitnas app-layer apps.
- Checksum: Al igual que UDP, permite determinar si el segmento está corrupto.
- Sequence number field y acknowledgement number field: Son dos campos que permiten implementar la reliable data transfer.
- Receive window: Utilizada para el control de flujo, permite indicar cuantos bytes el que lo envía estará dispuesto a aceptar.
- Header length field: (4bits). Especifica el largo del header en 32bit words. (1=32 bits). El header tiene largo variable por el options fields, aunque típicamente esta vacío y el header ocupa 20 bytes.
- El options field es utilizado para negociar el MSS o para escalar la ventana (receive windows) en conexiones rápidas. También incluye time-stamps si se lo desea.
- El flag field contiene 6 bits. El ACK bit se usa para indicar que el acknowledge field es valido. El RST, SYN, FIN son para iniciar una conexión y destruirla. PSH se usa para indicar que el que recibe el paquete lo debe pasar a la capa de arriba enseguida. URG indica que hay datos que son de carácter urgente (según el sender). La ubicación de el ultimo byte de estos datos se encuentra en el urgent data pointer field.
SEQ and ACK
Para TCP, los datos son un stream de bytes ordenado. TCP usa esta secuencia de bytes que fueron transmitidos y los que no para los seq numbers. El numero de secuencia de un segmento es el numero de secuencia del primer byte que se incluye en el segmento. El acknowledgement number contiene el numero de secuencia que el quien lo envía está esperando recibir (del a quien se le envía el ACK). TCP envía acknowledgements del byte mas bajo de la secuencia que aún no se recibió (si estoy esperando el byte 15 y 20, mando acks con el byte 15). Por lo tanto, quien recibe los ACKS sabe que si le llega un ack 70, quien envió el ACK ya recibió todos los bytes del 0 al 69. Esto es cumulative acknowledgements.
Es importante destacar que si el receiver recibe un segmento fuera de orden, la RFC no le obliga a que debe que hacer con el. Puede descartarlo o bufferearlo (en la practica se suelen bufferear ya que es más eficiente.). Otro detalle a notar es que inicialmente los acks y seq no empiezan en 0, sino que se escoge un numero aleatorio en el handshake. Esto es para minimizar la posibilidad que haya segmentos con el mismo número de seq viajando en la red por una conexión TCP vieja que usó el mismo puerto.
Ejemplo de SEQ y ACK en el protocolo Telnet:
RTT & Timeout
TCP necesita estimar el RTT para poder calcular el timeout. Este settea una variable $SampleRTT$ que mide el RTT de un segmento que aun no fue ack'd (solamente uno dado un periodo de tiempo). A su vez este segmento debe ser fresco, no se mide el RTT de una retransmisión. Luego se hace un average del RTT con la siguiente formula: $$ EstimatedRTT = (1-\alpha).EstimatedRTT + \alpha . SampleRTT $$
Por lo tanto, el valor del RTT se va a actualizando por cada sample. RFC6298 recomienda $\alpha = 1/8 $
Podemos observar que los sample values más nuevos tienen mayor peso que los sample values mas viejos en el estimatedRTT, esto se le llama exponential weighted moving average (EWMA). Adicionalmente, se mide como varía el RTT con la siguiente formula: $$ DevRTT = (1- \beta).DevRTT+ \beta . | SampleRTT-EstimatedRTT | $$ Se recomienda $\beta = 1/4$
Como el timeout interval no puede ser tan similar al RTT, pero tampoco tan lejano. TCP decide que el timout tiene que ser igual a 4 desvaisiones de la media (Al inicio $TimoutInterval = 1s$):
$$ TimoutInterval = EstimatedRTT + 4. DevRTT $$
Cuando se da un timeout este valor se duplica, cuando un segmento llega tras el timout, este valor se vuelve a calcular con la formula.
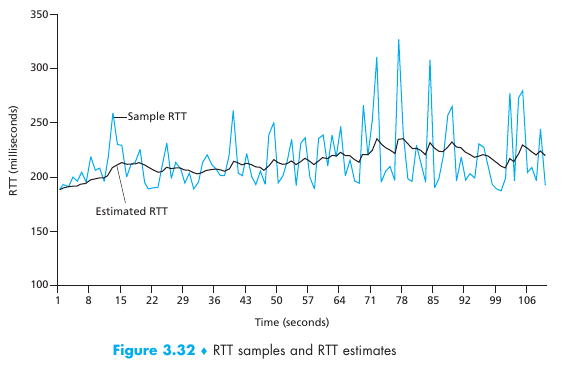
Reliable Data Transfer
TCP reliable data transfer service asegura que el TCP receive buffer este sin corromperse, sin huecos, sin duplicados y en secuencia: Un byte stream perfecto.
Utilizar timers para cada paquete produce overhead, por lo que TCP utiliza un single retransmission timer. El sender settea este timer siempre que se va a enviar un paquete y este está apagado (o cuando se receive el ack'd del segmento que inicio el timer y hay segmentos viajando). Cuando hay un timeout se retransmite unicamente el segmento más pequeño (según el orden) que aún no fue ack'd. El timout se calcula con las formulas que vimos ($TimeoutInterval$).
Ejemplos:
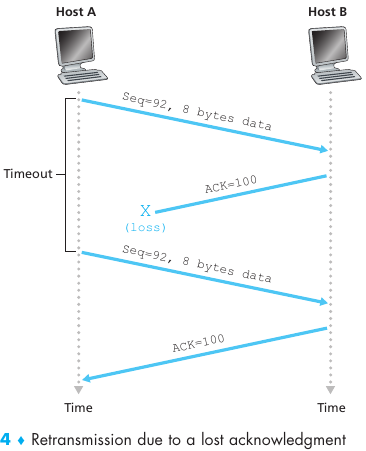
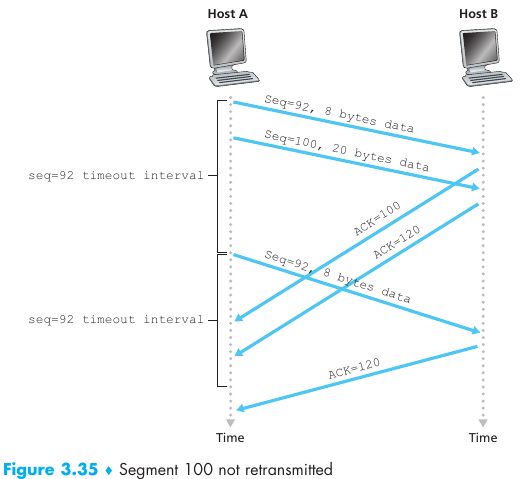
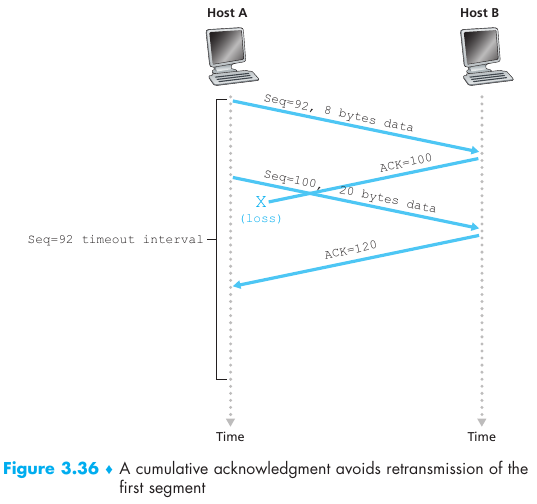
Observar que cuando se da un timout TCP duplica el siguiente timout. Esta es una forma primitiva de congestion control. Estas son las recomendaciones de la RFC para los ACK:
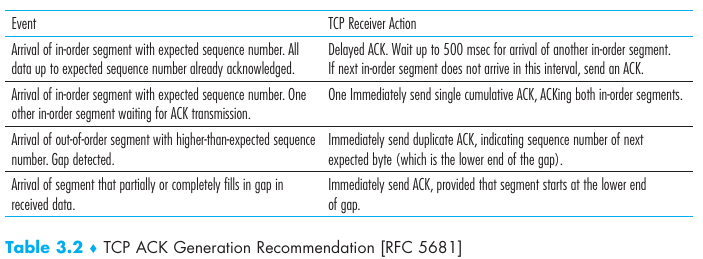
Adicionalmente a esto se suma el comportamiento fast retransmit: Cuando TCP sender receive tres ACKs duplicados, este entiende que el segmento que referencia el ACK se perdió. Por ello TCP sender realiza un fast retransmit, retransmitiendo el segmento perdido antes de que se de un timeout.
Este sistema de TCP puede verse como un híbrido entre go-back-n y selective repeat. Ya que tiene el cumulative acknowledgement de GBN, pero TCP también puede bufferear segmentos fuera de orden.
FLow Control
Como una app puede leer del buffer cuando ella desea, puede suceder que si se mandan muchos datos al buffer se de un buffer overflow. Por ello, TCP provee de un flow control service para evitar lo anterior. Iguala el ratio de envío con el de procesamiento. Esto se implementa haciendo que el que envía datos mantenga una variable llamada receive window. Esto le da al sender una idea de cuanto espacio libre hay en el receive buffer. (como la conexión TCP es full-duplex ambos lados implementan esto). Para ello se tiene que cumplir estas condiciones (rwnd is receive window):
$$ LastByteSent - LastByteAcked \leq rwnd = RcvBuffer - (LastByteRcvd - LastByteRead)$$
Cuando rwnd=0, para evitar que el sistema se tranque, el que envía segmentos cada cierto periodo envía segmentos de 1 data byte que van a ser ack'd por el receiver el cual va a contener el valor actualizado del $ rwnd $
TCP Connection Management
Los 3 pasos para establecer una conexión TCP son los siguientes (Explicación completa del famoso three-way handshake):
El cliente TCP envía un segmento especial (sin datos) con el SYN bit=1. El cliente elige un numero random para el numero de secuencia inicial (seq) y envía todo esto en el segmento TCP SYN.
Cuando el TCP SYN llega al servidor, el servidor extrae el TCP SYN del datagrama, aloca buffers y variables de conexión y envía un segmento TCP diciendo que se concedió la conexión (El momento de locación real de los buffers/variables puede variar para evitar ataques de SYN Flooding). Este segmento especial contiene 3 elementos: Un SYN bit=1, un ack field que vale al numero de seq recibido+1, y un numero aleatorio escogido por el servidor para el sequence field (seq). A este segmento se le llama SYNACK segment
Cuando el cliente receive el SYNACK el aloca también buffers y variables. Luego le envía un nuevo segmento al servidor que tiene el seq recibido + 1 como ack field. Syn bit=0 y la conexión ya esta pronta! Este segmento ya puede contener application data.
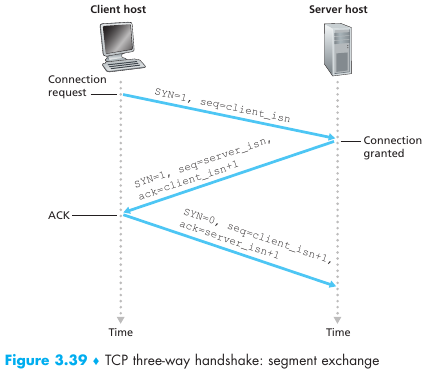
Para cerrar la conexión cualquiera de los dos puede enviar un segmento especial el cual tiene el FIN bit=1. Cuando se receive este segmento se manda un ack segment como respuesta. Luego tras mandar el ack se enviá un FIN segment y espera que el otro le mande un ack. Tras recibir el ack se sabe que la conexión ha terminado. Los estados de una conexión pueden modelarse con un AFD:
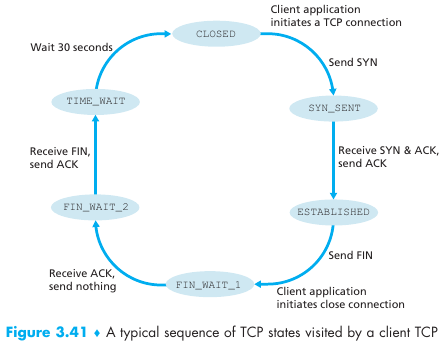
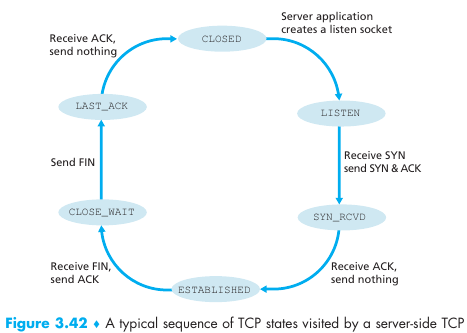
Que pasa cuando alguien no esta preparado para que le lleguen paquetes? Por ejemplo, si TCP esta aceptando paquetes al puerto 80, al llegarle un segmento con esa dirección este va a enviar un segmento de respuesta con el RST bit=1. Indicando que el puerto esta cerrado y que no manden segmento allí. En el caso de UDP, cuando UDP no esta configurado para recibir segmentos a un puerto, el servidor envía un datagrama especial ICMP.
La herramienta nmap permite visualizar los puertos de un host. Para TCP se pueden recibir 3 respuestas para un puerto: Un SYNACK, que indica que el puerto está abierto. RST que marca que el puerto está cerrado. O no recibir ninguna respuesta. Lo que indica que el SYN envíado fue interceptado y no llegó al host (firewall).
Principles of Congestion Control
Se dan 3 escenarios y los problemas que generan:
Conexión con buffer infinito: Son dos hosts por un cable con capacidad R. Si alguno manda R/2 el buffer se va a ir al infinito! Even in this (extremely) idealized scenario, we’ve already found one cost of a congested network—large queuing delays are experienced as the packet-arrival rate nears the link capacity.
Conexión con buffer finito: We see here another cost of a congested network the sender must perform retransmissions in order to compensate for dropped (lost) packets due to buffer overflow.. También esta el problema de si se manda una retransmisión cuando el paquete en realidad estaba en el buffer del router: Here then is yet another cost of a congested network—unneeded retransmissions by the sender in the face of large delays may cause a router to use its link bandwidth to forward unneeded copies of a packet.
- Path con muchos routers: So here we see yet another cost of dropping a packet due to congestion—when a packet is dropped along a path, the transmission capacity that was used at each of the upstream links to forward that packet to the point at which it is dropped ends up having been wasted. A–C end-to-end throughput goes to zero in the limit of heavy traffic.
Existen dos approaches al control de congestion:
- End-to-end congestion control: Se supone que la capa de red no nos ayuda en nada. El sistema tiene que inferir el estado de la red envíando paquetes y viendo como llegan. TCP usa este approach, usando timeout, triple ACKs y más.
- Network-assisted congestion control. Aquí el network layer nos ayuda. Un ejemplo es un bit que indica la congestion de un link (que nos llega como información). Un ejemplo sofisticado es el **ATM Available Bite Rate (ABR) en donde un router informa a quien envía el sendingrate que puede soportar como maximo. IP/TCP puede implementar opcionalmente alguna de estas técnicas
TCP Congestion Control
TCP implementa el control de congestion limitando el rate en que se puede enviar trafico en función de la congestion percibida de la red. Esto se hace con una variable congestion window $cwnd$ que impone:
$$ lastByteSent - LastByteAck'd \leq \min{cwnd,rwnd} $$
La congestión se detecta como un loss event, ya sea con un timeout o un triple ACK. El cwnd varía en función de los acks. Por lo tanto, si los acks llegan más rapido el cwnd va a cambiar más rapido, y si llegan más lento el cwnd va a aumentar pero más lento. Por eso se dice que este sistema es self-clocking.
La filosofía del mecanismo es de probing. Se trata de aumentar indefinidamente el cwnd hasta que algo falla:
The TCP sender’s behaviour is perhaps analogous to the child who requests (and gets) more and more goodies until finally he/she is finally told “No!”, backs off a bit, but then begins making requests again shortly afterwards.
El algoritmo
El algoritmo tiene 3 partes: Slow start, congestion avoidance y fast recovery. Cuando comienza una conexión TCP, se inicia cwnd=1 MSS. TCP le gustaría conocer el max bandwith rápidamente. Por ello, en el estado inicial slow-start state. Cuando llegan los ack de los segmentos se aumenta 1 MSS el cwnd. Esto hace que se duplique el sending rate en cada RTT, aumentando el bandwidth de manera exponencial.
Slow Start
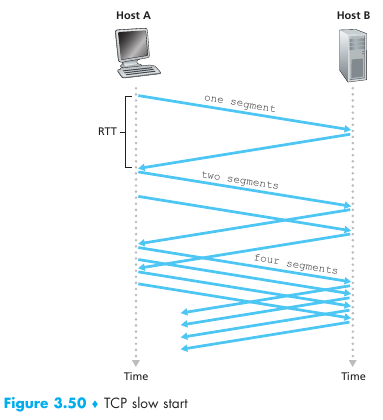
Cuando se da un timeout se reinicia el cwnd en 1 y se comienza el slow-start devuelta. Y a su vez settea una variable $ssthresh=cwnd/2$ (slow start threshold). Cuando cwnd supera este sshtresh, estamos a la mitad de cuando se rompio todo! Por lo que entramos a otro modo que aumenta el cwnd más despacio: congestion avoidance mode.
Si en vez del timeout recibiésemos triple ack. Se entra en modo fast recovery.
Congestion avoidance
Queremos evitar que se congestione! Estamos en este modo porque estamos a la mitad de cuando nos excedimos, por lo tanto el cwnd se incrementa en 1 MSS por cada RTT (incremento lineal). Cuando se tiene un timeout se settea el cwnd=1 MSS y sshthresh=cwnd. Cuando se da el triple ack se settea $ssthresh=cwnd/2$ y se cambia a $cwnd=cwnd/2 + 3 MSS$
Fast recovery
En fast recovery se aumenta el cwnd en 1 MSS por cada ACK recibido de los segmentos que causaron que se entre a este modo. Cuando llegan todos los acks se entra en congestion avoidance (achicando el cwnd) y si hay un timeout se entra al modo slow-start setteando cwnd=1 y sshtresh a la mitad.
Cabe aclarar que fast recovery no es obligatorio según el RFC para implementar TCP. Sin embargo su performance parece ser mejor.
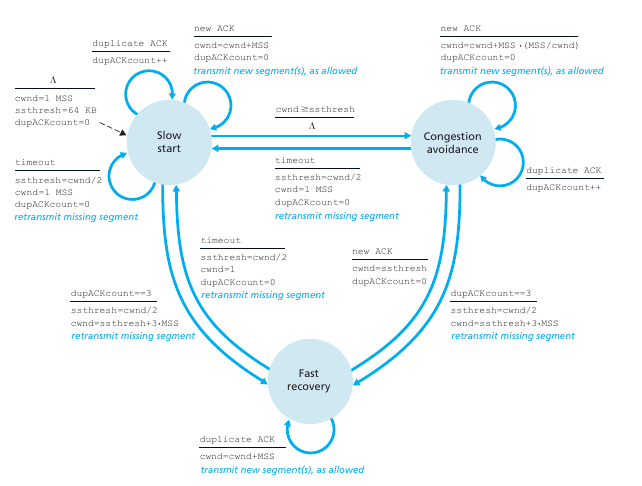
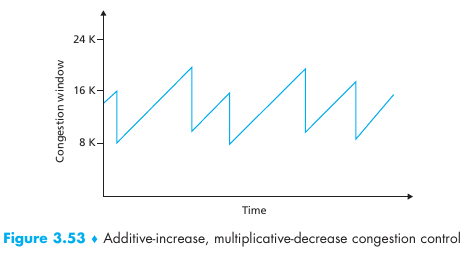
Por como evoluciona (exp->lineal) a este sistema se le llama additive-increase, multiplicative-decrease (AIMD) form of congestion control. Estos sistemas tiene el distintivo saw tooth behaviour.
Caba señalar que este algoritmo de congestión es justo en condiciones ideales. Sin embargo en la practica (Donde los clientes tienen distintos RTT y MSS) las conexiónes con menor RTT consiguen mayor ancho de banda obteniéndolo más rapido cuando este se encuentra disponible.
From the perspective of TCP, the multimedia applications running over UDP are not being fair—they do not cooperate with the other connections nor adjust their transmission rates appropriately. Because TCP congestion control will decrease its transmission rate in the face of increasing congestion (loss), while UDP sources need not, it is possible for UDP sources to crowd out TCP traffic. An area of research today is thus the development of congestion-control mechanisms for the Internet that prevent UDP traffic from bringing the Internet’s throughput to a grinding halt
Otra forma de aprovecharse del sistema es tener muchas conexiónes TCP en paralelo. De esta forma un host puede obtener un ancho de banda superior en comparación a host que usan una única conexión TCP. La mayoría de los browsers modernos usan conexiones TCP múltiples para surfear la web.
Explicit Congestion Notification (ECN): Network-assisted Congestion Control
Se han hecho extensiones a IP y TCP para permitir el uso de señales que permiten control de congestion de forma explicita. A estos metodos se les llama Explicit Congestion Notification. En el network layer dos bits en el datagrama son utilizados para ECN. Uno es usada por un router para indicar que está experimentando congestión. Este bit viaja por el datagrama hasta el host destino. El cual luego le informa al host que inicialmente había mandado el mensaje sobre la congestión. La definición de congestión no esta definida por la RFC.
Parte IV-1 - Network Layer (Data Plane)
El plano de datos refiere a las funciones de los routers que determinan como un datagrama que recibe un router es reenviado a otra interfaz en base a su dirección de destino (IP).
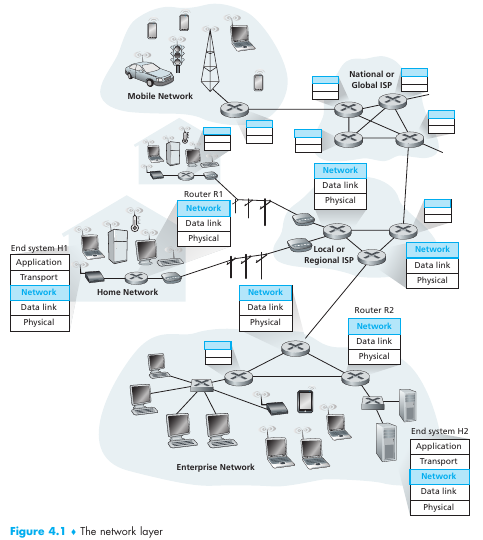
El rol central del network layer es simple: Mover paquetes de un host a otro. Para hacer esto posible se identifican dos funciones clave:
Forwarding: Refiere al hecho de enviar un paquete entrante a otra interfaz. En un caso mas general, un paquete puede ser bloqueado de salir de un router, o duplicado por muchos links!. Forwarding refiere a la accion local del router de transferir un paquete de una input de una interfaz a la correcta interfaz de salida. (Se hace muy seguido! Se implementa en hardware)
Routing: Los algoritmos que calculan los caminos que recorren los paquetes se les llama routing algorithms. El routing determina que caminos toma un paquete para llegar a un host. El routing se implementa en el control plane. Routing refiere al proceso de la red para determinar los caminos end-to-end que los paquetes toman desde una fuente al destino. Estos algoritmos no son "instantaneos" como el forwaring.
Podemos entender la diferencia con la analogia de un auto viajando de Montevideo a Punta del Este. Routing refiere a trazar la ruta y determinar las calles que se van a tomar, forwarding es en cada intersección, tomar el camino correcto.
Network service model
Que servicios podria brindar la capa de red? Algunos ejemplos:
- Delivery asegurado: Si un paquete se envía LLEGARÁ a su destino.
- Delivery asegurado y acotado en el tiempo: Un paquete enviado LLEGARÁ en MENOS DE X TIEMPO.
- In-order packet delivery: Los paquetes que se envían primero llegaran primero.
- Bandwith asegurada: Todos los paquetes viajaran a por lo menos X mbps.
- Seguridad: La capa de red podría encriptar todos los datagramas mientras viajan y desencriptarlos en el destino.
La capa de red de la internet no provee nada de esto xd. Simplemente hace las cosas lo mejor que puede, a esto se le llama best-effort service.
Son los packet switches los que están forwarding los paquetes de un lado para otro. Más especificamente, se les llama link-layer switches a los que deciden forwardear de a cuerdo a los valores de los campos del link layer, mientras que los routers determinan para donde forwardear según el header del network layer.
Que hay en un router?
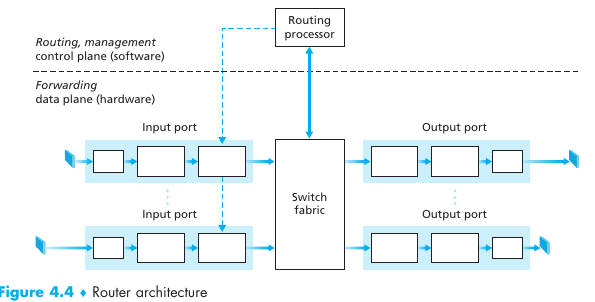
Input ports: Los puertos es donde se implemetna todo el link layer. A su vez los paquetes que llegan al input port se consulta la forwarding table para ver para donde mandarlo. Las empresas chicas tienen routers con unos pocos puertos mienrtas que las ISP cuentan con routers de incluso 960 puertos ethernet.
Switching fabric: Conecta los input ports con los output ports. Esta totalmente contenido en cada router.
Output Port: Almacena los paquetes que les llega de la switching fabric y los transmite por el link saliente. Cuando un link es bidireccional se suele emparejar un output port y un input port para una misma entrada.
Routing processor: Ejecuta los protocolos de enrutamiento, mantiene las tablas de routing y construye la forwarding table
Existen dos clases de forwarding:
- Destintation based forwarding: Se determina para que output port enviar el paquete según su dirección
- Generalized forwarding: No solo se mira la dirección sino que los headears. Por ser un paquete de tipo "email" podría envíarse por redes mas lentas si así se desea.
Input port processing and destination-based forwarding
El input port utiliza la forwarding table computada por el routing processor (o es recibida por un controlador SDN). Esta tabla es copiada a los puertos en un bus separando, evitando la necesidad de los puertos de invocar al procesador.
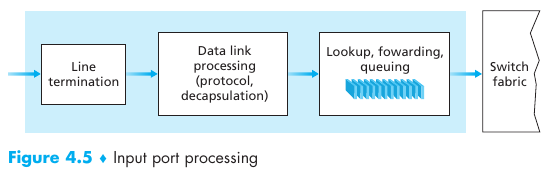
La forwading table contiene un rango de ips y a que interfaz debe matchearse. Para ello se mira el PREFIJO de la dirección destino. Si hay más de un matching se decide a favor del prefijo más largo (longest prefix matching rule).
Para que el matching de la tabla sea eficiente (nanoseconds) se emplean tecnologías avanzadas de electronica como las Ternary Content Addressable Memories (TCAM), las cuales pueden contener más de un millon de entradas y procesarlas todas en tiempo casi constante.
Es importante notar que si bien el matching para el forwarding es la acción esencial del input port también se realizan otras acciones:
- Implementación del link layer
- Analisis del checksum del paquete, version, TTL y actualización de valores.
- Actualizar contadores internos del router (cantidad de datagramas recibidos por ejemplo)
Es importante notar que esta accion de matchear y forwardear es un caso particular de la abstracción match+action que realizan muchos dispositivos como firewalls, NAT's, etc. Básicamente la idea es tener una funcion que dado un elemento le aplica una cierta transformación.
Switching
El traspaso de datagramas entre puertos (switching) se puede lograr de las siguientes maneras:
Via memoria: Manera tradicional, analoga a una computadora. Un puerto interrumpe a la CPU para hacer un proceso de copia a otro puerto (como si estos fueran dispositivos IO. Solo se puede transferir de a 1 puerto a la vez). Los routers mas modernos que operan via memoria procesan y copian los datos sus entradas en la misma tarjeta de red. Funcionan como un multiprocessor con memoria compartida.
Via BUS: Los paquetes se transfieren via un bus compartido entre todos los puertos. El input que enviá el paquete manda un header interno indicando la dirección destino, y solo el puerto salida correspondiente copia el paquete. Solo se puede transferir un paquete a la vez en un mismo bus.
Interconnection network: Se utilizan conexiones entre puertos más complejas, como la de una grilla. En esta se pueden mandar multiples paquetes por el fabric a la vez mientras no colisionen en la grilla.
Existen técnicas avanzadas donde se combinan todas las estrategias, creando un switching fabric de varias capas. Adicionalmente, existe la técnica de "spraying" que particiona los datagramas y los manda por distintas salidas del fabric en paralelo, acelerando el proceso de transferencia.
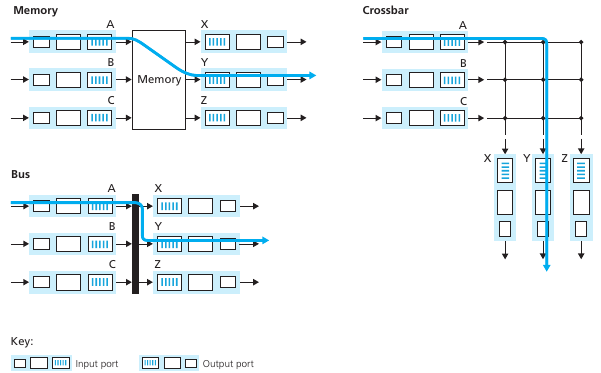
Output port processing
En el output port procesing los paquetes transferidos se almacenan en memoria y esperan ser transmitidos por el output link. Esto incluye seleccionar y desencolar los paquetes a transmitir e implementar el link layer correspondiente.
Queueing and Scheduling
El encolamiento de los paquetes puede suceder en dos lugares: En los buffers del input port y en los buffers de los output ports. El primero se da si llegan mas paquetes de los que se pueden transmitir por el switching fabric, el segundo se da cuando llegan mas paquetes de los que se pueden transmitir por el output link. Cuando cualquiera de los buffers se llena, no va a haber lugar para insertar más paquetes y tendremos packet loss. cuando se decide desechar el ultimo paquete en llegar se le llama política drop-tail.
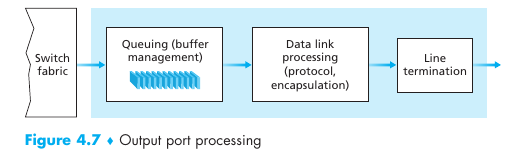
En la transferencia de input a output el encolamiento se da cuando dos inputs están requiriendo un mismo recurso, ya sea la CPU, un bus o un output. Un problema que se da aquí es el fenómeno de head-of-line (HOL) blocking. Este sucede en conexiones que permiten paralelismo y se da cuando en la cola el primer paquete está esperando la disponibilidad de un output y los otros paquetes que están atrás podrían estarse enviando ya que se estos cuentan con los recursos disponibles para hacerlo.
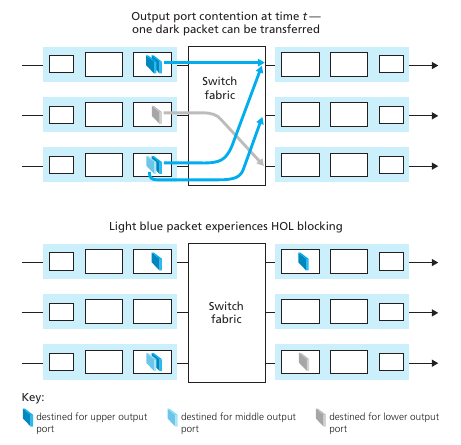
Como decidir que paquete enviar? Se necesita un packet scheduling algorithm!!! El comportamiento del scheduler es bastante similar al process scheduler visto en sistemas operativos. Los schedulers usualmente siguen las siguientes políticas: FIFO, Priority queueing (+FIFO), Round Robin and Weighted Fair Queueing (RRQ). Este ultimo asigna tiempo round robin según pesos asignados a cada input. El tiempo dedicado a un input $i$ será $w_i / \sum w_j$ donde $w$ es el peso de los input y vale $0$ si la cola está vacía.
The Internet Protocol (IP): IPv4, Addressing, IPv6, and More
IPv4 Datagram format
El formato de un datagrama ipv4 es:
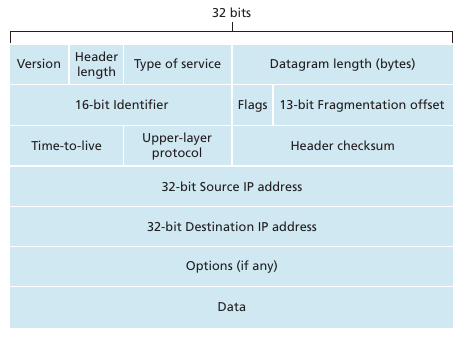
- Version number: Le permite identificar al router que version IP es el datagrama.
- Header length: como ipv4 tiene header variable por las opciones necesita determinar donde comienza el payload. Por lo general los datagramas no tienen options, por lo que el largo clásico es de 20 bytes
- Tipo de servicio: Permite a los datagramas distinguirse, por ejemplo los que son de voIP y los FTP (tiempo real/no tiempo real). Como estos son tratados depende de las políticas del administrador de red.
- Datagram length: Largo total del datagrama (header+data). Como ocupa 16 bits, el largo maximo sería 65535 bytes, aunque por lo general los datagramas no son mas grandes de 1500 bytes para poder entrar en un ethernet frame.
- Identifier, flags, fragmentation offset: Estos tres campos implementan la fragmentación IP. (En ipv6 no hay fragmentación!)
- Time-to-live (TTL): Asegura que los datagramas no quedan loopeando, se decrementa en cada hop del router. Si el TTL vale 0, el datagrama ese descartado por el router.
- Protocol: Se utiliza cuando el datagrama llega al desinto. Indica a que protocolo de la capa de transporte debe pasarse el datagrama. Por ejemplo el 6 indica TCP, 17 indica UDP. Tiene un rol análogo al numero de puerto (the protocol number is the glue that binds the network and transport layers together).
- HeaderChecksum: Permite detectar errores en el header. Como el TTL cambia en cada hop, cada router debe verificar y actualizar el checksum antes de forwardear. Este checksum se computa agarrando de a dos bytes como números y sumandolos usando 1s complement arithmetric.
- Source and destination IP: Indica de donde viene y hacia donde va.
- Options: Permite extender el IP header. Complican mucho por lo que se sacaron en el ipv6.
- Data (payload): The raison d'etre for the datagram. Contiene el segmento de la capa de transporte! O puede ser un segmento ICMP!
IP Datagram Fragmentation
Cuando a un router le llega un datagrama de 1500 bytes pero los output links tienen un maximum transmission unit (MTU) de 500 bytes, que hace el router? Ipv4 realiza fragmentación IP. Fragmenta la payload en varios datagramas ip y los reenvia. Luego el end host reconstruye el datagrama mirando ciertos atributos del header. Cuando el host destinto recibe datagramas de un mismo source, debe determinar si los datagramas son fragmentos de un datagrama mas grande. Si hay fragmentos debe determinar cuando recibió el ultimo fragmento y como deben estos fragmentos unirse. Para esto está la identification, flag and fragmentation offset. Cuando se crea un datagrama, se le pone un numero de identificación (usalemente con la ayuda de un contador). Cuando el desinto examina los datagramas de un mismo host y ve que tiene la misma identificación sabe que hubo framentacion! El ultimo datagrama del fragmento tiene el flagbit set en 0, mientras que todos los demas tienen flagbit de 1. Por ultimo, para saber el orden de todos los fragmentos que deberían llegar se tiene un numero de offset. con esto tenemos todas las cosas para reconstruir el datagrama original!
IPv4 Addressing
En este momento es importante precisar que la frontera entre un host y su link físico se le llama interface. Tanto para hosts finales como para routers. Es decir, un router tiene multiples interfaces. Por lo tanto. Una dirección IP esta asociada a una interfaz de red, no al host que contiene dicha interfaz.
Cada dirección IP tiene 32 bits de largo 4 bytes. Se usa la dotted-decimal notation para escribir las direcciones. Donde se separa de a 8bits la dirección con un punto. Y estos 8 bits se representan como un numero. Como consecuencia tenemos que las direcciones IP pueden representarse con la siguiente expresión regular:
[0-255].[0-255].[0-255].[0-255]
Cada interfaz en cada host tiene que tener una IP que es globalmente única. No es algo al azar! Sin embargo, una porción de la IP address de la interfaz va a estar determinada por la subred donde está conectada.
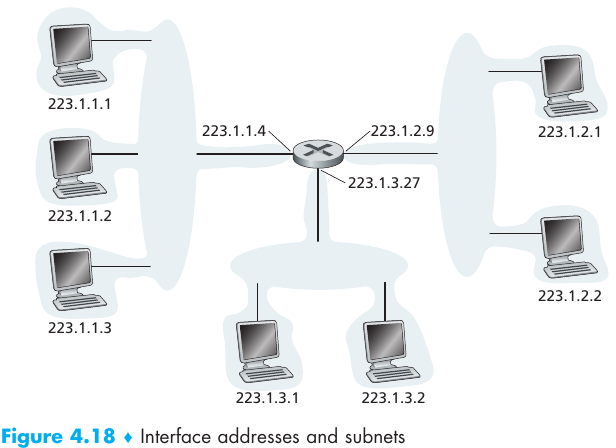
La red que interconecta 3 interfaces de red y un router forma una subnet. IP addressing asigna una dirección a esta subred: 223.1.1.0/24 a esto se le llama una subnet mask. Indica que los 24 bits más a la izquierda de los 32, definen la dirección de subred. Cualquier host que se conecte a esta subnet must have an address de la forma 223.1.1.xxx
Para determinar las subnets mirando un mapa topológico seguimos esta receta:
To determine the subnets, detach each interface form its host or router, creating islands of isolated networks, with interfaces termianting the end points of the isolated networks. Each of these isolated networks is called a subnet.
Como se asignan ips en la internet? La estrategia utilizada se la conoce como Classless Interdomain Routing (CIDR). Generaliza la noción de subnet addressing. Dividiendo la 32bit IP en dos partes con la forma *a.b.c.d/x donde x indica los bits de la primera parte del address. Los x bits más significativos son el network prefix* las ISP le asignan a las organizaciones un bloque de direcciones definido por el network prefix. Los demas bits permiten distinguir los hosts presentes en la organización.
La organización con este bloque puede hacer más subnets dentro con total libertad.
Antes de existir el CIDR se utilizaba *classful addressing, donde las subnets tenian como prefijo 8, 16 o 24 bits de largo. Esto desperdiciaba muchas direcciones porque hay un salto muy importante entre necesitar 256 ips (2^8) a precisar 65534 ips (2^16).
Las ISP que conectan muchas subnets utilizan address aggregation, route aggregation, route summarization para simplificar su tabla de forwarding. Por ejemplo si un router atiende todas las subnets 200.23.16.0/23,...,200.23.30.0/23 puede poner en su router que le manden todo lo que tenga dirección 200.23.16.0/20
Adicionalmente, a esto tenemos la broadcast ip address: 255.255.255.255: La cual enviá datagramas a todos los hosts dentro de la misma subnet. Los routers podrian forwardear el mensaje a las subredes vecinas (pero no lo suelen hacer).
Si bien es la ISP la forma tradicional de obtener un bloque de direcciones IP, como es que las IPs obtienen un bloque de direcciones? Existe un organismo regulador: Internet Corporation for Assigned Names and Numbers (ICANN) que se encarga de alocar direcciones IP a las ISP, controlar los DNS Root servers y resolver disputas de nombres de dominio. La ICANN asigna direcciones a los nombres de registro regionales (ARIN,RIPE,APNIC y LACNIC (por continente)) los cuales forman la Address Supporting Organization of ICANN (ASO-ICANN) y gestionen la locación de direcciones en cada una de sus regiones.
Obtaining a Host Address: The Dynamic Host Configuration Protocol (DHCP)
El network administrator configura el ip address de los routers. Pero los hosts no tienen por qué hacerlo manualmente, para ello existe un protocolo de autoconfiguration llamado Dynamic Host Configuration Protocol (DHCP). El net.admin configura DHCP para que cada host reciba la misma IP address cada vez que se conecta a la red, o un IP temporal que va cambinado. Adicionalmente a la ip, el host también obtiene infomracion de la mascara de subred, el address del router (default gateway) y el address del servidor de DNS local.
Esta capacidad de autoconfiguarcion de DHCP recibe el nombre de plug&play o zeroconf protocol. DHCP es un protocolo cliente/servidor. donde el cliente es el nuevo host que se conecta.\ En el caso mas simple cada subnet tiene un DHCP server, de lo contrario se necesita un DHCP relay agent (usualmente el router) que conozca donde está el servidor.
El protocolo DHCP queda ilustrado con esta imagen:
yaddr: indica la nueva IP address que va a ser alocada al nuevo cliente.
Los 4 pasos del protocolo son:
- DHCP server discovery: Lo primero que tiene que hacer el cliente es encontrar el servidor DHCP para interactuar. Esto se hace con un DHCP discover message que envía paquetes UDP por puerto 67 enviado en un datagrama de broadcast. El yaddr vale 0.0.0.0. Se manda un transaction ID para identificar el protocolo entrante.
- DHCP server offer: El servidor responde al discovery enviando al broadcast address la oferta. Como pueden haber muchos servidores DHCP, cada mensaje contiene la transaction ID de la petición de discovery, la oferta de la IP del cliente, la mascara de red y el IP Address lease time, que indica por cuantos segundos va a ser valido.
- DHCP request: El cliente va a escoger alguna de als ofertas y va a responder con un DHCP request mesage, echoing los parametros ofrecidos.
- DHCP ACK: El servidor DHCP resonde al mensaje, confirmando los parametros enviados.
Luego de esta interaccion el cliente ya tiene su IP!!! También existe un mecanismo para renovar el alquiler de la IP. La contra mas grande de DHCP es que si nos movemos de subnet nuestra ip deja de ser valida (Esto tiene un gran impacto en las redes móviles).
Network Address Translation (NAT)
Dado que las ipv4 son preciadas, el ISP no nos asigna un bloque entero de IPs como su servicio básico para hogares. Para conectar nuestros dispositivos nos tenemos que valer de las redes privadas y sus dominios de direcciones. Estos rangos de direcciones solo tienen sentido dentro de la subred:
| RFC 1918 name | IP address range | Number of addresses | Largest CIDR block (subnet mask) | Host ID size | Mask bits | Classful description |
|---|---|---|---|---|---|---|
| 24-bit block | 10.0.0.0 – 10.255.255.255 | 16777216 | 10.0.0.0/8 (255.0.0.0) | 24 bits | 8 bits | single class A network |
| 20-bit block | 172.16.0.0 – 172.31.255.255 | 1048576 | 172.16.0.0/12 (255.240.0.0) | 20 bits | 12 bits | 16 contiguous class B networks |
| 16-bit block | 192.168.0.0 – 192.168.255.255 | 65536 | 192.168.0.0/16 (255.255.0.0) | 16 bits | 16 bits | 256 contiguous class C networks |
Como se comunican estos dispositivos por internet? Respuesta: NAT. En essencia, la NAT es un servicio del router que empareja una comunicación entre dos hosts utilizando los puertos del router. Se utiliza una NAT Translation Table para emparejar un host y puerto locales con un servidor externo. En esencia, cuando se hace un pedido a un servidor externo, al pasar por el router se le cambia la ip origen por la ip pública del router y el puerto a uno que el router crea conveniente. La nat translation table guarda el mappeo (IP destino,puerto)<->(IP local, puerto). De tal forma de que cuando llega la respuesta del servidor, el router cambia la ip y puerto del datagrama y la envía al host inicial.
IPv6
Direcciones de 128 bits. Largo de cabezal fijo de 40 bytes.
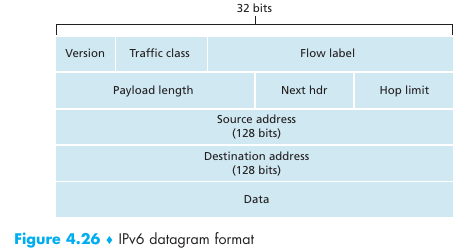
A diferencia de ipv4, el cabezal de tamaño fijo. El checksum se remueve, era una perdida de tiempo que debía recalcularse cada vez que pasaba por cada router (ya que se modificaba el TTL).
Ya no se implementa fragmentación. Si no hay lugar (MTU), mando al sender un mensaje ICMP avisandole del problema (con el MTU maximo del camino por lo que el datagrama no pudo pasar!!!).
Agregaron un identificador de flujo. La idea sería tratar, por ejemplo un streaming, como un flujo de datos y no un montón de datagramas. Puede ser utilizado para reservar recursos, simplificar mapping a MPLS, etc.
Se cambió el nombre del TTL a Hop Limit para respetar mejor la realidad. (Aclaración lingüística)
Traffic class es un descriptor de los distintos tipos de trafico. (en ipv4 este campo se llama TOS)
El payload, ahora indica la cantidad de contenido de datos. Que sería maxsize-header. El payload maximo es de 65536 bytes (MTU- payload+header length)
El nextheader es un puntero a la siguiente opción. Me permite agregar opciones agregando otro header ipv6 o directamente al contendio (payload) como el cabezal TCP. Es decir, indica la presencia de extension headers o identifica el protocolo de la capa superior acarreado al payload.
Notación
Los 128 bits de una dirección IPv6 se notan como ocho enteros de 16 bits, en notación hexadecimal, separados por dos puntos (:).
Ejemplo: fe80:0000:0000:0000:224:7eff:fee0:3bc9 (if config de enp0s25 de Makise)
Algunas abreviaciones son: Remover los zeros a la izquierda para cada entero. Los juegos de enteros con valor cero pueden abreviarse mediante dos puntos (Puede darse que hayan varias formas de escribir una misma ip).
Ejemplo: fe80::224:7eff:fee0:3bc9
Para transformar una dirección ipv4 a ipv6 se suele escribir asi: FFFF::192.168.50.222
Para escribir direcciones en una URL deben escribirse entre corchetes.
Los prefijos son escritos utilizando la misma notacion de barra que en ipv4 (slashed notation).
Ejemplo: fe80:AAAA:7600::/40 es una dirección de red con prefijo de 40 bits.
Direcciones especiales:
Unspecified address: Puede ser utilizada únicamente por un nodo que aún no tiene una dirección, y su valor es "0:0:0:0:0:0:0:0" abreviandose como "::" o "::/128":
Loopback address: Analoga al 127.0.0.1 de ipv4, envía datagramas ipv6 al mismo host del remitente. El valor para ipv6 de loopback es: 0:0:0:0:0:0:1. Abreviado como "::1" o "::1/128".
Default route: Requerida para especificar el routeo por defecto en las tablas de routeo. Se representa por "0:0:0:0:0:0:0:0/0" y abreviada como "::/0" (La subred por defecto).
Global Unicast: 2000::/3 (Es decir, los primeros 3 bits son 001, despues podes asignar lo que sea).
Unique Local Unicast: Único a nivel de subred: FC00::/7
Link local Unicast:** Único a nivel de link (switch?): FE80::/10
Multicast: FF00::/8
IPv6 extension headers
Los headers son enganchados usando el campo next header. Los valores de las opciones son interoperables con los valores utilizados en el protocolo ipv4. (ej: TCP=6,UDP=17,etc)
Extension header table:
- Hop-by-Hop header (NH=0)
- Routing header (NH=43) (Va a permitir hacer que un datagrama siga un determinado camino, ignorado la routing table del router)
Fragment header (NH=44) (Permite fragmentar datagramas solo en las puntas del flujo, pero esto solo lo puede hacer el emisor. Solo se realiza fragmentación end-to-end. Ipv6 require un link MTU de al menos 1280 bytes para cualquier link, entonces, 1280 es también un valor para el path MTU)
Authentication header (NH=51)
- Encapsulated security payload
- Destination option (NH=50) (que debería hacer el host cuando le llega este datagrama )
Consideraciones de seguridad: Si me llega un datagrama con un routing header. NO SE DEBE responder a dicho datagrama por el camino inverso propuesto por el routing header A MENOS QUE esté el security header presente y autentifique al sender para saber que es confiable. Esto se hace para evitar ataques que desvían todo el trafico a un solo router/enlace.
Direcciones IPv6
Tenemos $2^96$ más direcciones que IPv4. Es una cantidad GIGANTE de direcciones. Tenemos 128 bits y distintos tipos de direcciones:
Unicast: Identifican exactamente a una interfaz. (Un origen, un destino)
Multicast: Identifican a un grupo de interfaces. Un paquete enviado a una dirección multicast es entregado a todos los miembros del grupo (Un origen, muchos destinos)
Anycast: Un paquete enviado a una dirección anycast es entregado al miembro "más proximo del grupo". (Un origen, algún host que pertenece al grupo). Es un buen mecanismo para CDN, aunque su mayor implementación de uso se encuentra presente en el servicio DNS. Los Root DNS tienen cientos de servidores y todos atienden la misma IP!!!
Unicast
Las direcciones unicast se dividen en globales (Clásica definición de IP), link-local (solo tiene sentido en este link), Unique local (ULA) (Analoga a la 192.168...) y IPv4 mapped (cosas para transformar una ipv4 en una ipv6)
Global Unicast Address
Las global unicast address tienen el formato 001<45 bits><16 bits><64 bits>. Los primeros 45 se les llama global routing prefix y es eun valor asignado jerárquicamente por las a las RIR 's (Regional Internet Registry) e ISPs. Los siguientes 16 bits son el sub-net id que es un identificador de red dentro de un sitio utilizado por las ISP y RIR para asignar espacios de direcciones. Finalmente los 64 bits determinan una interfaz en la red.
Unique Local IPv6 Unicast Addresses
Son las de prefijo local FC00::/7. Si bien no hay garantía de unicidad, esta es muy alta "Según Murphy". Se reservan para comunicaciones locales dentro del site. No se routean a través de la internet, solo en entornos restringidos. Los prefijos son bien conocidos ("Well known prefiexes") y se filtran fácilmente en el borde de la red
Los ISPs pueden usarlas aunque no tengan acceso a Internet, y el trafico que se escape no causa daño (o es mínimo). Las aplicaciones usan estas direcciones desconociendo su naturaleza de Unique local address
El formato de estas address son:
FC00(7bits)<-L=1-><-40 bits (Global ID)><-16 bits (subnetID)-><-64 bits(interfaceID)-> L=1 significa asignación local (L=0 no está definido, reservado para uso futuro). Global ID debería ser creado de forma aleatoria para minimizar colisiones.
La interface ID puede ser asignada de las siguientes formas:
- Autoconfiguration (modified EUI-64)
- DHCPv6
- Configuración manual
- Aleatoriamente
- Futuros métodos
La más común es la autoconfiguración. En que consiste? Se utiliza el MAC address de la interfaz de red para generar una dirección necesariamente única. Esto se basa en el estándar IEEE para MAC Address de 48-bits, el cual es un numero que identifica de manera única una interfaz de red. Está pensado para que los 24 bits más altos los asigne la IEEE a los manufacturers de hardware y los otros la fabrica los asigna a los dispositivos.
Esta se expande a la izquierda agregando unos y un zero al final a la derecha (De lo que se expandió). Finalmente, se cambia el bit 7 a 1.
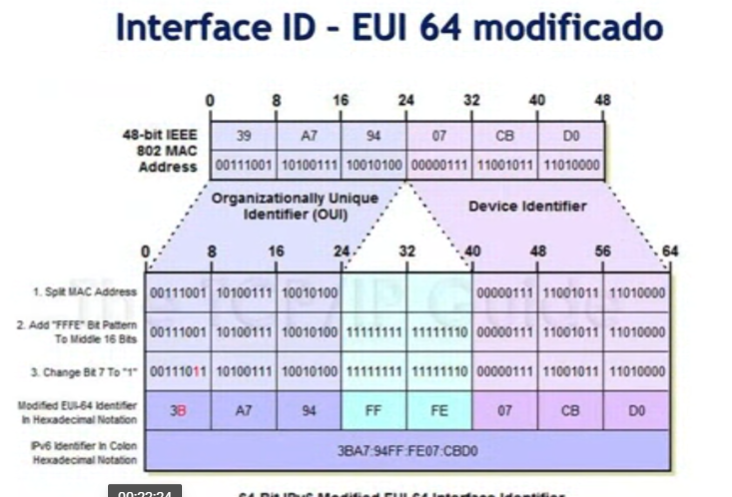
Direcciones IPv6 obligatorias para un Host
A diferencia de IPv4, para obedecer el protocolo ipv6 un host debe definir ciertas direcciones:
- Una dirección Link-local para cada interfaz (más toda otra dirección unicast o anycast manual o automáticamente configurada)
- Loopback address
- Direcciones de multicast All-nodes (FF01::1 y FF02::1)
- Dirección de multicasSolicited-Node para cada dirección unicast y anycast
- Direcciones de multicast para todos los grupos a los que pertenezca el nodo.
Y un router que implementa ipv6 debe tener
- Todas las direcciones de un host
- Dirección de anycast Subnet-router para todas las interfaces utilizada para hacer forwarding de paquetes
- Toda otra dirección anycast configureada
- Direcciones de red múlticast All-routers (FF01::2 y FF02::2)
ICMPv6
Misma filosofía que ICMP para IPv4, pero ahora en vez del valor 1 de ICMPv4 se usa el valor 58 en el area NextHeader de ipv6. ICMPv6 es obligatorio (a MUST) en la suite de protocolos y debe ser completamente implementado por todo nodo.
Si el tamaño del paquete ICMPv6 resultante excede los 1280 bytes, es truncado a ese tamaño. (Recordar el MTU mínimo) Algunos mensajes de error ICMPv6:
0 - No route to destitnation
1 - Communication with the destination administratively prohibited
2 - Beyond scope of source address
3- Address unreachable
4 - Port unreachable
5 - Source address failed/ingress/egress policy
(Type2,code0,parameter=next-hopMTU) Packet too big message
(Type3,parameter=0),code: 0 - Hip limit exceeded
IPv4 to IPv6
El protocol field 41 en ipv4 indica que el protocolo de la payload es un datagrama ipv6! Esto sirve para implementar el tunneling entre routers. Esto es, encapsular un datagrama ipv6 en uno ipv4 para permitir la comunicación de datagramas entre enlaces que no soportan ipv6.
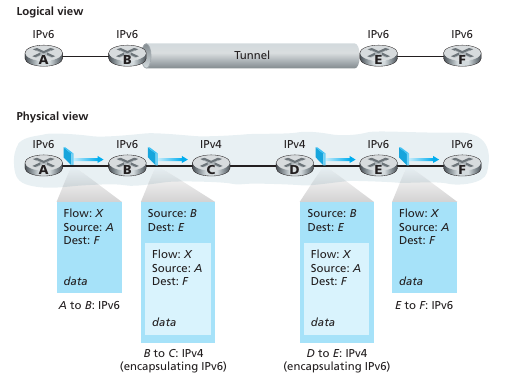
Broadcast and multicast routing
Broadcast routing es un servicio que permite enviar un paquete desde un origen a todos los nodos de una red. Multicast routing permite a un origen enviar un mismo paquete a un subset de destinos en la red.
Broadcast Routing algorithms
Una implementación naive del broadcast seria que el origen retransmitiera el paquete a cada uno de los destinos de la red. Esto trae 2 problemas grandes. Primero, es ineficiente si el link que conecta el origen a la red es lento, este link actúa como cuello de botella entorpeciendo el proceso de broadcast. Segundo, como el origen sabe todos los destinos de la red? Se necesitarían protocolos y mecanismos adicionales que complicarían la red.
Uncontrolled Flooding
Una técnica obvia llamada flooding refiere a que cuando un nodo recibe un broadcast datagram, este lo copia y lo trasmite por todos sus output links. Este approach tiene el error fatal de que si el grafo de red tiene ciclos entonces vamos a estar retransmitiendo y duplicando el mensaje mas de lo necesario e incluso un destino puede recibir el broadcast message infinitas veces! Este efecto fatal para la red se le llama broadcast storm.
Controlled Flooding
Para evitar el broadcast storm, la clave esta en decidir cuando un paquete debe ser flooded y cuando no. Existen varias técnicas
Sequence number controlled flooding: Un nodo fuente pone su dirección (o identificador), y un broadcast sequence number en el paquete de broadcast y lo manda a todos sus vecinos. Los nodos mantienen una lista con las tuplas (fuente,broadcast sequence number). Cuando a un nodo le llega un paquete broadcast, se fija si esta en su tabla antes de mandarlo. Si lo esta, no lo floodea por sus output links. El protocolo de broadcast Gnutella implementa esta técnica.
Reverse path forwartding/broadcast (RPF/RPB): Cuando un router recibe un broadcast packet con un source address, retransmite el paquete en todos los output links (excepto por donde vino) solamente si el link por donde arrivó el paquete es parte del camino mas corto de vuelta al origen en unicast. De lo contrario, se descarta el link. Esto previene las broadcast storms.
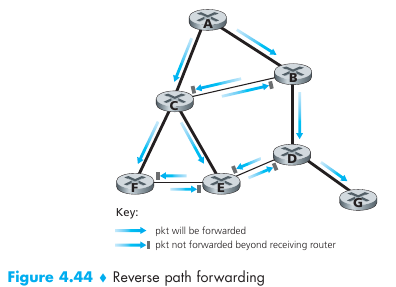
- Spanning tree broadcast: Si construimos un minimum spanning tree y se mandan los broadcast packets por estos links ya ganamos. La dificultad está en construir y mantener dicho spanning tree en la red. Una de las técnicas más simpels es la center-based approach. La cual se define un nodo core y los nodos hacen unicast tree-join message al nodo core. Estos tree-join messages viajan hasta llegar al spanning tree definido, merging la ruta que hicieron con el spanning tree ya definido para agrandar el mismo con el nuevo nodo.
In practice
Gnutella utiliza application-level broadcast over TCP con un sequence number controlled flooding de 16 bits y un 16 bit payload descriptor (Gnutella message type). A su vez se incluye el TTL para limitar los hops, de esta manera se puede limitar los peers que están a un cierto numero de application-level hops del query initiator (a esto se le llama limited-scoped flooding).
El sequence number controlled flooding también se utiliza para broadcast link-state advertisements (LSA) en los protocolos OSPF y IS-IS (Intermediate-System-to-Intermediate-System).
Multicast
A packet is delivered only to a subset of network nodes. Muchas aplicaciones requieren este tipo de comportamiento: Bulk data transfers, streaming media, shared data applications , data feeds, interactive gaming, etc.
En multicast communication aparecen dos problemas: Como identificar a los que reciben los paquetes multicast y como definir el address de un paquete enviado a estos destinos.
En internet un multicast packet is addressed using address indirection. I.e se usa un solo identificador para el grupo de destino. Y se hace una copia de los paquete.
El identificador que representa un grupo de destinos es un type D multicast address. El grupo de destintos asociados a este identificador se le llama multicast group.
En la internet el multicast es implementado por el Internet Group Management Protocol (IGMP).
Internet Group Management Protocol
IGMPv3 opera entre un host is su router vecino. IGMP permite a un host decirle a su router que quiere unirse a un grupo especifico de multicast.
Como IGMP solo habla entre host y su router amigo, se necesita otro protocolo para llevar adelante la comunicación entre multicast routers sobre la internet. Esto es llevado a cabo por network layer multicast routing algorithms.
IGMP tiene solo tres tipos de mensajes, los cuales se encapsulan en un datagrama IP (con numero de protocolo 2):
- membership_query message: Se enviá por un router a todos sus hosts adjuntos para determinar el conjunto de multicast groups que los hosts se han unido. Los hosts responden a esta query con:
- membership_report message: Respuesta a un query message. También son generados por un host cuando por primera vez una aplicación quiere unirse a un multicast group sin querer esperar que llegue un membership query message del router.
- leave_group message: Este mensaje es opcional, un router puede inferir que un host ya no quiere pertenecer a un multicast group por su respuesta en el membership_report message. Este es un ejemplo de un soft state protocol donde la infomracion se va a no ser que se refresque. (con un membership report). Coined by clark in:
"... the state information would not be critical in mantaining the desired type of service associated with the flow. Insted, that type of service would be enforced by the end points, which would periodically send messages to ensure that the proper type of service was being associated with the flow. In this way, the state information associated with the flow could be lost in a crash without permanent disruption of the service features being used. I call this concept "soft state, " and it may very well permit us to achieve our primary goals of survivability and flexibility..."
Multicast routing algorithms
Existen dos approaches para los algoritmos. Las cuales difieren en si un single group-shared tree es usado para distribuir el trafico para todos los senders o si el árbol que se construye es source specific por cada sender.
Multicast routing using a group shared tree: Se basa en construir un árbol que incluya a todos los edge routers con sus hosts adjuntos que pertenecen a un multicast group. Se usa el center based approach visto en los routing algorithms. (Join messages addressed to the center node).
Multicast routing using a source-based tree: Mientras que el anterior construye un único árbol para todos los frens. Este approach construye un multicast tree para cada uno de las sources del multicast group. Se utiliza el algoritmo RPF para construir los forwarding trees para cada node. Este mismo necesita hacerse un pequeño ajuste, ya que RPF mandaria mensajes a routers que no tienen a ningún host ni router en el multicast group, literalmente mensajes basura. Esto no es agradable si un router se conecta a miles de otros routers! La solución a esto es que el router que no quiere ser spammed envía mensajes prune para decirle al router multicasting que no le mande esos mensajes.
Multicast routing in the internet
El primer protocolo multicast de la interwebs fue el Distance Vector Multicast routing protocol (DVMRP). El cual utiliza source based trees con RPF y pruning. El multicast routing protocol mas popular es el Protocol Independent Multicast (PIM) routing protocol, el cual tiene dos tipos de "escenarios":
Dense mode: Muchos routers juntos en un area que requiere routear multicast datagrams. PIM en modo denso utiliza flood-and-prune reversa path forwarding (Como DVMRP)
Sparse mode: El numero de routers attached al grupo es bajo en relación a la cantidad de routers. PIM en modo disperso usa puntos de encuentro para setear el multicast distribution tree.
Estos algoritmos los configura el network administrator en su red ( al igual que OSPF, RIP e IS-IS), pero que pasa si se quiere hacer multicast entre sistemas autonomos? Existen extensiones al protocolo BGP que permiten llevar routing information de otros protocolos: incluyendo incluyendo información del multicast. El Multicast Source Discovery Protocol (MSDP) se utiliza para conectar puntos de encuentro para el protocolo PIM en modo disperso.
Aun queda mucho por trabajar en el IP multicast y el tiempo va a definir si el multicast se va a realizar sobre el application layer o el network layer (en la practica).
IP multicast has yet to take off in a big way.
Parte IV-2 - Network Layer (Control Plane)
El plano de control se encarga de controlar las rutas que hacen los datagramas por la red y como administrar los distintos componentes y servicios del network layer.
Como se construyen las tablas de forwading? Existen dos approaches: Per-router control: Los algoritmos corren en cada uno de los routers. Logically centralized control: Las tablas son computadas por un agente externo, y son enviadas a los routers. El primer approach es utilizado por los clásicos algoritmos OSPF y BGP mientras que el segundo es el utilizado por los protocolos SDN.
Routing Algorithms
Un mapa de rutas puede representarse con un grafo ponderado $G=(N,E,W)$ . El objetivo de un routing algorithm es identificar el camino menos costoso entre dos nodos (least cost path). Si todos los costos son iguales, también se halla el camino más corto (shortest path).
Clasificación
Existen dos formas de clasificar los algoritmos de enrutamiento:
Centralized routing: Computa el least-cost path entre fuente y destino usando un conocimiento global de la red. De alguna manera se necesita conocer el grafo G,E,W completo. La ejecución del algoritmo puede realizarse en un solo lugar (controlador centralizado), o puede ser replicada en cada uno de los routers. Estos algoritmos con información global se les llama link-state (LS) algorithms.
Decentralized routing algorithm: El calculo del least-cost path se lleva de manera distribuida e iterativa entre los routers. Cada router tiene información parcial del grafo: Solamente conoce sus vecinos. Mediante un proceso iterativo de calculo e intercambio de información con sus vecinos, el nodo calcula el camino menos costos a un destino. Un algoritmo descentralizado a estudiar es el distance vector (DV) algorithm.
Otros criterios adicionales son si el algoritmo es dinamico o estático. El primero se ejecuta con cierta frecuencia y responde a cambios en el estado de la red. Mientras que el estático no cambia, unicamente con intervencion manual (Alguien que cambia los costos y vuelve a ejecutar el algoritmo).
Finalmente, los algoritmos pueden ser sensibles al estado de congestion de la red. Los algoritmos que se usan en la internet son load insensitive, se detectaron numerosas dificultadas en los algoritmos sensibles que dificultan su aplicación en la realidad.
Link-State (LS) Algorithm
En el algoritmo LS se conoce el estado global de la red. Esto se hace haciendo que cada nodo haga un broadcast con link state packets a todos los nodos de la red con la identidad y costos de los links vecinos a cada nodo. Esto se hace con un link-state broadcast algorithm.
El algoritmo que utiliza LS es el de Dijkstra. El mismo tiene una complejidad computacional de $O(n^2)$ .
Un caso patológico es si los costos de los nodos es la carga (congestión) que tienen. En este caso pueden generarse loops si cada vez que un paquete viaja, el mejor camino cambia haciendo que el router "vuelva de donde vino".
Distance-Vector (DV) Algorithm
A diferencia de LV, DV es un algoritmo iterativo, asíncrono y distribuido. Cada nodo recibe información unicamente de sus vecinos, realiza un calculo, y distribuye los resultados de dicho calculo a sus vecinos. Es iterativo porque el proceso continua hasta que no haya mas información para intercambiar entre los vecinos. Es self-terminating (no hay una señal que lo detenga, solo se detiene). Es asíncrono ya que los nodos no están sincronizados para actuar entre si.
El DV se basa en la ecuacion de Bellman-Ford: (Donde $d_x(y)$ es el costo de viajar de x a y) :
$$ d_x(y) = min_v {c(x,v) + d_v(y)}$$
Cada nodo $x$ guarda:
- El costo $c(x,v)$ de viajar desde x a un vecino v
- El vector distancia de x: $D_x = {D_x(y): y \in N}$ con la distancia estimada de viajar desde x hasta todos los demas nodos
- El vector distancia de los vecinos de x: $D_v = {D_v(y): y \in N}$
El algoritmo consiste en:
Para cada nodo x: ---Inicializar--- para los demas nodos y en N: si es vecino D_x(y)=c(x,y) else D_x(y)=inf para cada vecino w: D_w(y)=? para cada vecino w:
enviar vector de distancia D_x
-----
loop
wait (esperar a que cambie un costo o recibir información de un nodo vecino)
para cada y en N:
D_x(y)=min_v {c(x,v)+D_v(y)}
si D_x(y) cambió para algún destino:
Enviar D_x a todos los vecinos.
forever
Algoritmos DV son muy utilizados en la practica. Ejemplos: RIP, BGP, ISO IDRP, Novell IPX y ARPANet.
El único problema que sufre los algoritmos DV son el count to infinity problem. Que pasa si se actualiza este peso a 60?
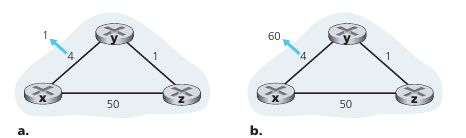
El problema radica en que z usaba a y para llegar a x, y esta información se transmite lentamente... (ejecutar algoritmo para darse cuenta)
Una solución a cuando el problema se da por ciclos en 2 routers es usar poisoned reverse. Este consiste en que si (por ejemplo), el nodo z utiliza y para llegar a x, entonces z le manda a y D_z(x)=infinity, por lo que el nodo y no va a tratar de pasar por z para llegar a x.
Comparación LSvsDV
Complejidad de los mensajes: LS require conocer el costo de cada link de la red. Es decir, precisa O(|E|,|N|). Cuando hay un cambio en los costos, se debe enviar un mensaje a todos los nodos. DV solo envía mensajes a los vecinos.
Velocidad de convergencia: LS es O(n^2) que requiere O(|E|,|N|) mensajes. DV puede converger lentamente y puede haber routing loops mientras el algoritmo converge, a su vez sufre del count-to-infinity problem.
Robustness: En LS cada tabla de distancias es independiente, mientras que en DV un cambio afecta las de las demas. En este sentido LS es más robusto.
Intra-AS Routing in the internet: OSPF
Los algoritmos LS y DV vistos no son aplicables a la internet de forma completa, la cantidad de nodos que habria de este un costo prohibitivo. Adicionalmente, no asegura la autonomía de las subredes. Es decir, que una ISP pueda si lo desea, ocultar aspectos de su organización interna y seguir estando conectada.
La solución de esto es organizar los routers como autonomous systems (AS). Donde cada AS consiste de un set de routers que están bajo la misma égida administrativa. Las ISP suelen tener uno o varios AS. Un sistema autonomo es definido por un identificador global asignado y administrado por la ICANN.
Los routers dentro de un mismo AS comparten información entre ellos. A estos algoritmos se les llama intra-autonomous system routing protocol.
OSPF (Open shortest path first), y su primo IS-IS son usados para intra AS routing. El Open viene de que el algoritmo es público. En OSPF, cada router tiene un mapa completo del sistema autonomo. (Es decir, el grafo donde los nodos son los routers y hosts del sistema). Cada router ejecuta Dijkstra para determinar el árbol de caminos más cortos de todas las subredes.
En OSPF, los routers broadcastean routing information de todos los routers del AS cuando hay un cambio en algún enlace (también lo hacen de forma periódica cada treinta minutos). Los mensajes OSPF viajan por IP con el upper-layyer protocol 89, por lo que OSPF tiene que inventar su reliable data transer.
Algunas características extra que se fueron agregando a OSPF a lo largo del tiempo son:
Seguridad: Se habilitan mecanismos de authentication para que usuarios no confiables inyecten información erronea en las tablas de enrutamiento. Se puede hacer authentication simple y con MD5.
Multiple same-cost paths: Se puede tener mas de uni camino a un destinto (esto sirve cuandio se tienen muchos paquetes llegando juntos)
Integrated suppot for unicast and multicast routing. Se proveen extensiones para broadcasting en OSPF.
Support for hierarchy within a single AS: Se puede tener el AS en varias areas, donde cada una corre su OSPF interno. En cada area hay routers responsables de routear paquetes para afuera del area, ademas de una backbone area que permite intercomunicar lostas las areas (el backbone tiene todos los routers bordes (que comunican areas) del AS)
Routing Among the ISPs: BGP
Para comunicarnos entre ISPs, i.e entre AS necesitamos un inter autonomous system routing protocol. En la internet, todos los AS corren el mismo protocolo: Border Gateway Protocol (BGP)
Es un protocolo asíncrono descentralizado que utiliza distance vector routing. Las direcciones en BGP tienen la forma de una subnet, por lo que la forwarding table de BGP va a tener la forma $(x,I)$ donde x es el prefijo e I es la interfaz de algún router dentro de la subnet.
BGP permite a cada router obtener prefix reachability information desde AS vecinos. En efecto, cada subred anuncia su existencia al resto de internet. A su vez, permite determinar cual es la mejor ruta para los prefijos.
Advertising BGP Route Information
Es importante diferenciar los gateway routers y los internal routers los primeros son aquellos que se encuentran en el borde del AS y conectan routers internos del AS con routers gateway de otro AS.
En BGP, parejas de routers intercambian routing information sobre conexiones TCP semi-permanentes sobre el puerto 179. Cada conexión TCP junto a los mensajes enviados se le llama BGP connection. Una conexión BGP entre dos routers de distintos AS se le llama external BGP (eBGP) connetion, las que son entre routers internos es una internal BGP (iBGP) connection.
Una configuración clásica de conexiones es la mostrada a continuacion. Notar que la red de conexiones TCP no corresponde necesariamente a los links físicos entre los routers. Para propagar la información se necesita tanto iBGP como BGP.
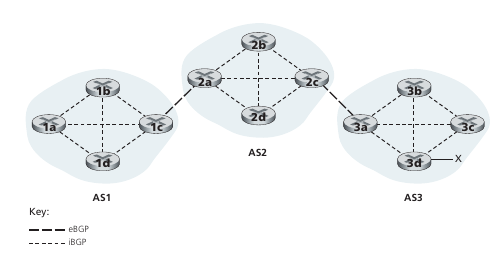
La lógica de BGP es básicamente que para cada subnet se agrega el AS que recibe el mensaje para indicar que tiene que pasar por ahi para poder acceder a la red. Un mensaje del estilo: "AS2 AS3 x".
Determining the best routes
Existen muchos caminos para llegar a una subnet que pasan por distintos sistemas autonomos. Como hace un router para escoger el mas adecuado?
Cuando un router anuncia un prefijo por una conexión BGP, incluye varios BGP attributes. En BGP , un prefijo junto a sus atributos se le llama route. Los dos atributos mas importantes son AS-PATH y NEXT-HOP. El primero indica la lista de AS por los que pasó el anuncio. Para generar este valor, cuando un prefijo pasa por un AS, el AS agrega su ASN (Autonomous sistem number) en la lista AS-PATH existente. El AS-PATH también permite evitar ciclos. Ya que si un AS ve su propio anuncio en la lista entonces no lo vuelve a incluir. Por ejemplo, en la siguiente imagen existen dos rutas desde AS1 a la subnet X. Anunciadas en el AS PATH "AS2 AS3" y "AS3". Por otro lado NEXT-HOP, el link entre los protocolos inter-AS e intra-AS, es la IP address de la interfaz de router que comienza el AS-PATH. Por ejemplo, en la imagen se tiene los routers 2a y 3d para las 2 rutas. En resumen, una BGP route tiene una terna de valores (NEXT HOP/ AS PATH / PREFIX) Ej: (IP(2a); AS2 AS3; x) y (IP(3d);AS3; x).
Observar que NEXT HOP no es una ip que pertenece al AS inicial pero se encuentra directamente conectado a este.
Hot Potato Routing
En hot potato routing, la ruta elegida va a ser la ruta con menor costo de routeo hacia el NEXT HOP. Es decir, el rute va a consultar su intra-AS routing info para determinar cual es el next-hop mas barato de mandar. Los pasops para agregar una entrada en al forwarding table con una entrada de un AS externo se ilustra a continuacion. }
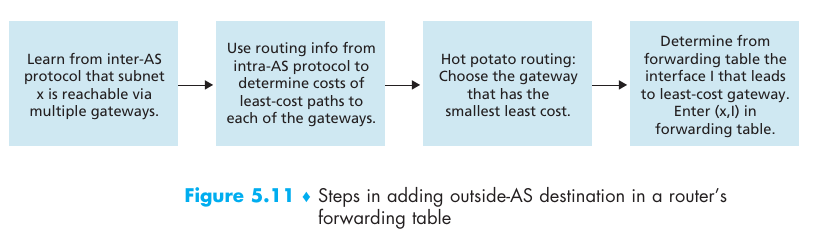
La idea detrás del hot potato es sacarse los paquetes del AS lo más rapido posible (i.e con el menor costo) sin considerar la ruta que tiene que hacer el datagrama por fuera del AS. Notar que distintos routers dentro del AS pueden tener diferentes AS paths para un mismo prefijo.
Route selection Algorithm
El algoritmo de BGP es un poco mas complejo que el de la papa caliente: Para un prefix destino dado y un set rutas aprendidas (y aceptadas) para ese prefijo. BGP realiza las siguientes reglas de eliminación hasta que solo una opción queda (si solo hay 1 no hay eliminación):
Se le asigna a una ruta preferencia local. Este valor es asignado por el network network administrator
Quedarse con los (o la) ruta con el AS-PATH más corto (que pasa por menos AS).
Aplicar la papa caliente para elegir según el NEXT-HOP más cercano.
Si todavía queda mas de uno, se escoge según los identificadores BGP.
Debido que primero se aplica la regla dos, BGP no es un algoritmo egoísta como el Hot Potato Routing
IP-Anycast
Adicionalmente a implementar el Inter-AS routing protocol, BGP también se usa para implementar el servicio IP-Anycast, el cual se usa en las DNS. Ip anycast surge de la necesidad de replicar contenido en distintos servidores ubicados en distintas ubicaciones geográficas y permitir a los usuarios acceder al contenido a traves del servidor mas cercano a este.
Por ejemplo, varios servidores se ponen la misma IP. Luego los routers BGP van a recibir varios anuncios de dicha IP, como consecuencia va a tomar el camino mas corto. DNS utiliza esto, las CDN no porque cambios en el routing BGP puede resultar en distitnos segmentos TCP llegando a distintos serviddores.
Routing policy
Dado que los sistemas autonomos existen por factores socioeconomicos . Existen decisiones de no permitir comunicaciones entre AS entre otras cosas. Por ello es que existe el local preference attribute en BGP.
Multihome access ISP: ISP connected to the internet via 2 different ISP providers.
ICMP: The Internet Control Message Protocol
Este protocolo es utilizado por host y routers para comunicarse información del network-layer. El uso mas clásico es error reporting. (Ej el destination unreachable es un mensaje ICMP: El router no sabe para donde mandar el packet y crea un mensaje ICMP de respuesta).
Los mensajes ICMP se transportan a traves de datagrams IP. (upper-layer-protocol number 1).
Los mensajes ICMP tienen un tipo, código y contienen el cabezal y los primeros 8 bytes del datagrama IP que generó el mensaje. (Así el sender puede determinar cual fue el datagrama que generó el error).
El programa ping manda mensajes ICMP type 8 code 0 los cuales son un echo request, al cual se le responde a type 0, code 0 ICMP echo reply.
También tiene mensajes source quench que se usan para el control de congestion.
El funcionamiento de traceroute se basa en que cuando un datagrama muere e n un router, el router debería responder con un ICMP warning (type 11, code 0). Como los mensajes UDP que se envían se mandan a un puerto que probablemente no está abierto, se espera que el destino reponda con un mensaje ICMP type 3 code 3 de port unreachable.
ICMPv6 agrega los mensajes "packet too big" y "unrecognized IPv6 options error codes."
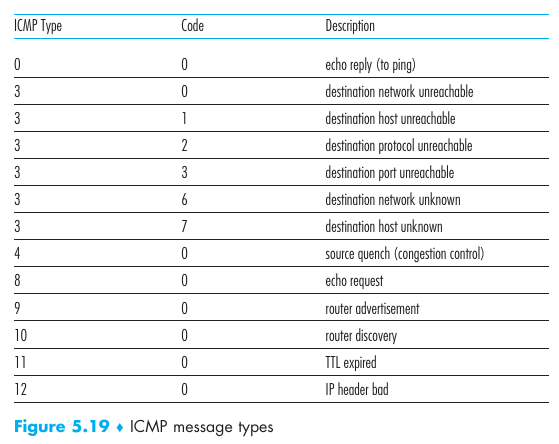
Parte V - The Link Layer and LANs
How packets are sent across the individual links that make up the end-to-end communication path
En el link layer se entiende a todos los dispositivos que corren el link layer como nodes y los canales de comunicación entre ellos links. Sobre un link, el nodo transmisor encapsula los datagramas en un link-layer-frame.
El link layer podría proporcionar los siguientes servicios:
Framing: Casi todos los link layer protocols encapsulan los datagramas del network layer en un frame. Un frame es una estructura que contiene el datagrama y headers que utiliza el link layer.
Link access : Se necesita un mecanismo de control de acceso: Medium Access Control (MAC) que indique las reglas para determinar cuando se puede mandar un frame por un link. El MAC es trivial cuando las conexiones son punto a punto (cable), pero resulta mas complejo cuando varios nodos comparten el mismo link. Por ejemplo, en reades inalámbricas.
Reliable delivery: Se asegura que mover un datagrama por un link estálibre de errores. Se suele tener este servicio en links que tienden a tener errores (eg conexiones wi-fi o satelitales). Sin embargo el overhead que genera hacen que no sea tan necesario en links de tipo fibra, coaxial o cobre.
Error detection & correction: El hardware del link layer puede tener un circuito que permite determinar si el frame entrante contiene errores y poder corregirlos. Para esto se implementan técnicas de correccion de errores a nivel de hardware.
Es importante observar que el link latyer se implementa en un adaptador de red (network adapter) . En los tiempos que el adaptador de red no venia incluido en la motherboard se les solía llamar network interface card (NIC). Es un chip especialmente diseñado para implementar los servicios del link layer (framing, error detection, etc). Por otro lado, el link layer también debe ser implementado en software y ejecutado por una CPU. Por ejemplo, para implementar el ensamblado de las direcciones del link layer, manejar las interrupciones del adaptador de red, etc.
Error detection & correction techniques
Existen varias técnicas de detección de errores. Muchas de ellas ya las vimos en el curso de arquitectura de computadoras. Se aplican técnicas de checksum en la capa de transporte, en el link layer, al utilizar hardware especializado, es posible aplicar técnicas mas efectivas y avanzadas para la detección de errores como el cyclic redundancy check (CRC).
CRC
Se quieren enviar $d$ bits, el sender y el receiver se ponen de acuerdos en un patron de $r+1$ bits que será el generador. La idea central está en: Para cada mensaje, el sender va a agregarle r bits adicionales (R) de tal manera que el patrón de d+r bits sea divisible por el patrón G definido. Entonces, ver si hubo errores o no es verificar si el resto de de dividir los d+r bits por el generador da 0.
Multiple Access Links and Protocols
Existen dos tipos de links, los point ot point links son los que tienen un single sender/single receiver. Existen multiples protocolos point ot point: point to point protocols (PPP) y high level data link control (HLDC) son dos ejemplos. Por otro lado los broadcast link son los que experimentan multiples senders. Ethernet y las W-LAN son ejemplos de link-layer broadcast protocols. Estos protoclos de broadcast sufren del multiple access problem. Para ello se implementan los multiple access protocols.
Cuando dos nodos transmiten un frame al mismo tiempo sobre un mismo canal, se dice que dichos frames colisionan. Cuando se da esta colisión, los frames quedan entrelazados y no hay forma de discernir cual es cual, por lo que la transmisión fracasa. Es por ello que los protocolos de acceso deben evitar que se den colisiones.
Existen tre categorías de MACs. Los channel partitioning protocols, random access protocols y los taking-turns protocols. Cada uno con sus propias características.
Es importante señalar que uno quiere que un MAC tenga las siguientes características sobre un enlace de velocidad de transmision R:
- Cuando solo hay un nodo enviando datos, la velocidad es R.
- Cuando hay M nodos enviando datos, la velocidad promedio de cada uno es R/M
- El protocolo es descentralizado, no hay un único punto de falla en la red
- El protocolo es simple y no genera overhead.
Channel partitioning protocols
Ya vimos dos protocolos de este tipo! El Time-division y el Frequency-division multiplexing (TDM y FDM respectivamente).
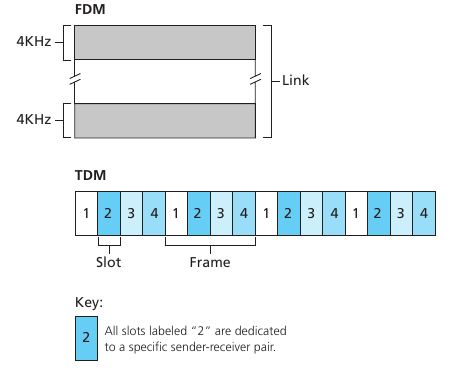
TDM divide el tiempo en time frames y cada time frame lo subdivide en time slots. Cada slot se le asigna a cada uno de los nodos conectados. Cuando un nodo queire enviar algo, espera su timeslot para enviarlo. El sabe que en ese momento no debe haber nadie utilizando el canal. TDM asegura una partición justa del ancho de banda, sin embargo tiene un problema grave: Si solamente un nodo queire utilizar la red, este no va a poder utilizar los timeslots de los demas. Es decir, hace un uso ineficiente de la red! El comportamiento de TDM es igual al de FDM, se particiona el ancho de banda y un nodo no puede aprovecharlo en su totalidad a pesar de que podría.
Random Access Protocols
En los protocolos RAP, los nodos transmiten a toda la velocidad del canal ($R$). Cuando hay una colision, los nodos involucrados en la colision retransmiten sus frames despues de esperar un tiempo de cooldown aleatorio (calculado por cada nodo) para luego retransmitir el frame. Como el cooldown es aleatorio e independiente, eventualmente va a darse que los nodos puedan trasmitir sus frames sin colisiones. Existen multiples protocolos RAP que veremos a continuacion
Slotted ALOHA
El slotted aloha consiste en que el tiempo se divide en slots de L/R segundos, donde L es el tamaño de los frames. Todos los nodos están sincronizados y saben cuando comienza cada slot. Cada nodo va a transmitir un frame por el slot con una probabilidad $p$. Si falla la transmisión se vuelve a reintentar en el siguiente con una probabilidad $p$. Se puede demostrar que la cantidad de slots exitosos (que consiguen transmitir un único frame de un nodo) es de proporcion $1/e = 0.37$ . Bastante ineficiente desu.
ALOHA
El protocolo ALOHA clásico es descentralizado. Y los nodos no saben cuando comienza o termina un slot. Simplemente se mandan de una a tantear aguas. Sin embargo la idea del comportamiento es la misma. La eficiencia de este protocolo es $1/2e$ .
Carrier Sense Multiple Access (CSMA)
El problema del ALOHA es que el mecanismo de colisiones era muy primitivo. Especificamente, no se siguen estas dos ideas esenciales:
Listen before speaking. Si alguien está hablando dejalo terminar. En las redes esto se le llama carrier sensing: el nodo escucha si hay actividad en el canal.
If someone else begina talking, stop talking. Esto se le llama colision detection.
CSMA implementa carrier sense, y CSMA with collision detection (CSMA/CD) implementa adicionalmente detección de colision.
Ahora bien, si los nodos esperan a que el canal este tranquilo para hablar? Como es que se generan las colisiones? De la misma manera que en las charlas humanas! Porque dos nodos deciden hablar "casi al mismo tiempo" entonces los nodos no registran que el otro nodo comenzó o hablar. Por lo que la colisión es inevitable. En las redes, esto está dado por el tiempo de propagación.
Carrier Sense multiple access with collision detection (CSMA/CD)
cuando se detecta colision, los nodos dejan de transmitir inmediatamente. Esto genera la pregunta, y cuando se vuelve a reintentar? Es importante observar que dependiendo de la cantidad de nodos en el canal determina la cantidad de tiempo que debería esperarse. Es decir, el tiempo de cooldown debería ser proporcional a la cantidad de nodos en el canal.
Para ello, CSMA/CD emplea un mecanismo de binary exponential backoff. Este también se usa en Ethernet y DOCSIS. Este consiste en: Cuando un frame experimenta $n$ colisiones, este va a pickear un numero random de cooldown del set ${ x : 0 \leq x \leq 2^{n-1} }$ . Por lo que cuantas mas colisiones experimenta un frame, mas probabilidad de que este espera un tiempo más largo. En Ethernet el cooldown es K*512 (512 es el tiempo de esperar que se mande 512 bits), y K es el numero aleatorio. En ethernet el valor $n$ esta capped en 10.
La eficiencia de CSMA/AD puede demostrarse que vale:
$$ Efficiency = \frac{1}{ 1 + 5\frac{d{prop}}{d{trans}}}$$
De aquí se deduce que si los delays de propagación tienden a 0 la eficiencia es del 100%
Taking turns Protocols
Como los protoclos ALOHA y CSMA cumplen que la transmision maxima de un nodo es R pero no que cada nodo activo tenga R/M de velocidad. Por ello se crearon los protoclos taking turns.
Polling protocol
El polling protocol requiere que uno de los nodos se designe como master. El nodo maestro polls cada uno de los nodos estilo round-robin. (Ej. el masternode le dice al nodo uno que si quiere puede transmit ahora como maximo x frames). El polling protocol elimina las collisiones y los empty slots de los random access protocols. Por otro lado, lo malo de este protocolo es que induce polling delays generados por la comunicación entre el master node y los otros nodos para confirmar el envío de frames. El otro problema mas serio es que si el master node se rompe la red queda inoperativa.
Token Passing Protocol
Este protocolo no tiene master node. Se utiliza un frame especial llamado token que se intercambia entre los nodos en un orden definido. El que tiene el token se lo queda hasta que termine de mandar los frames que tenga que transmitir, de lo contrario le manda el token a otro nodo. El problema de este tipo de comunicación se da si un nodo falla o si decide acapararse el token. Deben implementarse mecanismo s complejos para recuperar el sistema. Ejemplos de protocolos token passing son: Fiber distributed data interface protocol (FDDI) y el famoso IEEE 802.5 token ring protocol .
DOCSIS: The link layer protocol for Cable Internet Access
Como funcionan las redes cableadas del ISP. Utilizan todos estos protocolos discutidos anteriormente! El internet por cable consiste de muchos modems que se conectan a un cable modem termination stystem (CMTS). El Data-Over-Cable Service Interface Specification define como tiene que darse esta comunicación.
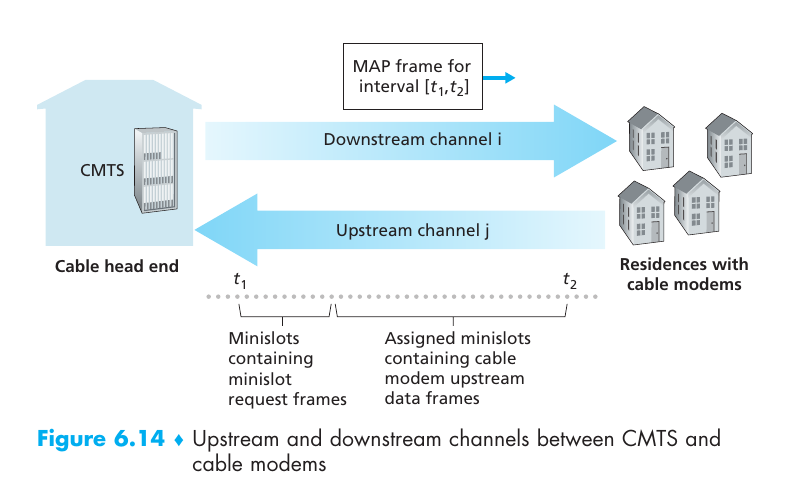
Existen dos canales que están time slotted. Cada uno de estos canales es un broadcast channel. Los frames transmitidos por el downstream channel por el CTMS son recibidos por todos los modems. (Como solo hay uno que transmite no hay problemas de multiple acceso). En la dirección upstream es donde pueden ocurrir colisiones.
CMTS envía un mensaje de control llamado MAP para indicar cual modem es el que puede transmitir en cada mini-slot de tiempo especificado en el mensaje de control. Estilo polling! El CTMS sabe los modems que quieren mandar frames porque estos envían requests en mini timeslots especificamente diseñados para ello de manera de evitar colisiones. Cuando hay una colision los modemos usan el binary exponential backoff.
Switched Local Area Networks
Link layer Addressing and ARP
Los hosts tienen link-layer addressess. Se tiene que entender que es necesario tener tanto una link address como una network address para un host como un humano precisa tener un código postal y una cedula de identidad.
Las interfaces tienen una dirección física asociada. Es importante destacar que los link-layer switches no tienen una dirección física asociada. Los switches son un objeto transparte en relación a los links entre los hosts. Los link layer address son llamados LAN Address, physical address o MAC address. La MAC address tiene 6 bytes de largo. Es decir, $2^{48}$ direcciones. Las MAC address son unicas en el mundo! Es definida por los device manufacturers en acuerdo con el espacio de direcciones que la IEEE les asigna.
Cuando un adaptador de red quiere enviar un frame a un adaptador destino, el que enviá inserta la MAC address del destino en el frame y la manda por la LAN. Cuando un adaptador de red recibe un frame, se fija si la dirección MAC destino de dicho frame coincide con su MAC Address. Si coincide, el adaptador extrae el datagrama que se encuentra en el frame y se lo manda al network stack. También existe la dirección de broadcast para que todos los hosts reciban el frame, esta dirección es la todo 1s (FF-FF-FF-FF-FF-FF).
ARP
Como hace un host para obtener la MAC address dada una dirección IP destino? Para ello existe el Address Resolution Protocol (ARP). El funcionamiento de ARP es el siguiente: Cada host tiene una ARP Table. La cual contiene tuplas < IP Address, MAC Address, TTL > . Donde este ultimo indica cuando se eliminará la entrada de la tabla.
Cuando se quiere mandar un mensaje a una IP, y no se tiene la entrada en la tabla para obtener la dirección MAC se debe enviar un ARP Packet. Los paquetes query y response tienen el mismo formato. El ARP query se manda a la dirección de broadcast FF-FF-FF-FF-FF-FF. El ARP query la reciben todos los nodos conectados y se fijan si la IP consultada coincide con la suya. El nodo que coincide su IP la responde al nodo que envió la query con su MAC Address. Al llegar al nodo original, este puede actualizar su ARP Table. Notar que la query se manda por broadcast pero la response se manda unicamente al host. Las tablas ARP no necesitan auto-configuración. Este tipo de protocolos se les llama plug & play. Notar que ARP se utiliza para enviar el datagrama al next-hop, el cual en el ultimo viaje coincide con el host destino. ARP es el protocolo que conecta el network layer y el link layer!
Ethernet
Ethernet es la tecnología dominante en las LAN. Esto se debe por ser la primera y superar a los competidores que fueron surgiendo (token ring, ATM) con el tiempo. En efecto, desde su introducción en 1970 ha ido cambiando drásticamente, no solo en su eficiencia sino también en las tecnologías que utiliza.
En 1970, ethernet utilizaba un bus coaxial que interconectaba todas las computadoras. Las colisiones se resolvían utilizando protocolos de acceso CSMA/CD con binary exponential backoff. Para 1990, la mayoria de las redes Ethernet utilizaba una topologia estrella con un hub en el centro. Un hub es un physical-layer device que trabaja bit-a-bit replicando todos los bits que entran por todas las salidas (y a su vez reactiva la energía de la señal). Notar que si un hub recibe dos frames al mismo tiempo se va a dar una colisión.
Para los 2000 Ethernet sigue utilizando la topología estrella pero ahora con un switch. Un link-layer device que es collisionles y de funcionamiento store-and-forward.
Ethernet frame structure

La imagen de arriba muestra la estructura de un ethernet frame.
Data-field (46 to 1500 bytes): Contiene el datagrama IP. El tamaño maximo (MTU) es 1500 bytes, si el datagrama es mas grande se debe fragmentar. El tamaño minimo del datafield es 46 bytes, si lo que se envía es mas chico debe llenarse con basura al final. El network layer utiliza el campo length-field para poder remover la basura después.
Destination Address (6 bytes): Contiene la MAC address del destino. Cuando un adaptador de red recibe un frame que el destino coincide con su MAC address, pasa el contenido del frame al network layer.
Source Address(6 bytes): Contiene la dirección MAC de quien envió el paquete.
Type field(2 bytes): Ethernet permite que se utilize otros protocolos de red aparte de IP. Como Novell IPX o AppleTalk. Este numero permite identificar el protocolo que de red que contiene el datafield. Esto es necesario para saber a que network layer se debería mandar el frame. Notar que ARP tiene su propio type field: 0x0806
Cyclic Redundancy Check (CRC) (4 bytes): Código para la detección de errores en el frame
Preamble (8 bytes): Los primeros 7 bits tienen el valor 10101010 y el ultimo tiene el valor 10101011. Estos bits se usan para "despertar" al adaptador de red. Se utiliza para sincronizar el que recibe los bits con el sender clock. Imaginate que uno recibe los bits tuc...tuc...tuc...tuc entonces el adaptador se sincroniza al ritmo en que llegan los bits (Si bien ethernet tiene una velocidad de transmision definida, en la realidad y por variantes físicas esta puede cambiar bastante). Los dos bits seguidos de 1s indican que los bits venideros serán el contenido posta del frame (fin del preámbulo).
Ethernet ofrece un servicio unreliable y connectionless. Las tecnologías de ethernet siguen un formato de nombre (Velocidad)(Baseband)-(Medio físico). Por ejemplo, Ethernet 10GBASE-T indica que la velocidad es de 10Gigabit por segundo, BASE indica que el trafico que pasa por el medio es unicamente tarfico de internet, y la T indica que el medio físico es Twisted Pair (UTP/STP).
El largo del cable ethernet es otra limitante, para superar el largo maximo se deben utilizar repetidores que revivan la señal. Ethernet de hoy en día es irreconocible con ethernet en 1970 a menos del formato de estructura del frame.
It is interesting to note, however, that through all of these changes, there has indeed been one enduring constant that has remained unchanged over 30 years— Ethernet’s frame format. Perhaps this then is the one true and timeless centerpiece of the Ethernet standard.
Link-layer Switches
Un link layer switch es un dispositivo de la capa de enlace que es transparente sobre los demas nodos de la red: Los nodos no saben que están interconectados por un switch. Los switches tienen buffers para poder procesar grandes cantidades de frames entrantes.
Forwarding and Filtering
Forwarding and filtering son loas dos funciones básicas de un switch. Filtering determina si un frame entrante debe ser reenviado o descartado. Forwarding es la funcion del switch, analoga la router, que determina para que interfaz el frame debe ser redirigido. Para hacer el forwarding, el switch se vale de una switch table, la cual contiene tuplas < MAC Address, Interfaz, Tiempo en que se insertó a la tabla>.
Entonces, el funcionamiento de un router es el siguiente: Al llegar un frame X...
- Si la MAC address destino del frame X no se encuentra en la tabla, se reenvía por todas las interfaces excepto por la interfaz X por donde vino. (Broadcast)
- Si la MAC address destino del frame X coincide en la tabla con la interfaz por donde vino inicialmente el frame, entonces el switch descarta el frame. Ya que se estaría replicando el mensaje
- Si la MAC address destino del frame X se encuentra en la tabla y es distinta a por donde vino, se hace el forwarding unicamente por esa interfaz.
La switch table se genera sola con un mecanismo de self learning que implementan los switches:
- La tabla está inicialmente vacía
- Para cada frame entrante, el switch guarda su dirección MAC, la interfaz por donde vino, y el tiempo. Si todos los hosts mandan frames, la switch table quedaría completa.
- La switch table borra direcciones que no fueron registradas tras un periodo de tiempo definido (aging time).
Properties of link layer switching
- Eliminación de colisiones
- Heterogenous links: Se puede tener links con distintas capacidades: 100BASE-FX, 10GBASE-T, etc. Todos conectados a un mismo switch.
- Management: Un switch puede administrar la red de manera automática. Por ejemplo si un adaptador de red se rompe y empieza a mandar frames a lo loco, el switch puede desconectarlo complementamente de la red.
- Seguridad: Eventualmente un switch enviá los frames solamente al link destino.
Existe una técnica de sniffing llamada switch poisoning que permite sniffear el trafico de un switch. Consiste en llenar la switch table de forma que todos los frames legítimos tengan que ser broadcasteados y así poder sniffear todos los paquetes que viajan por el switch.
La discusión entre cuando debe usuarse un router y cuando un switch puede llegar a ser eventualmente una pregunta compleja. Se debe tener en cuanta aspectos como la cantidad de dispositivos, seguridad, routeo optimo, etc.
Virtual Local Area Networks (VLAN)
Una lan clásica puede llegar a tener los siguientes problemas:
- Falta de isolación: En una lan, cuando el broadcast traffic viaja por todos los links. Si la cantidad de links conectados crece, la performance comienza a bajar. Estaría bueno una forma mas especifica de limitar el scope del trafico dfe broadcast. También estaría bueno esto por motivos de seguridad.
- Uso ineficiente de switches: Se necesita un switch por cada grupo de nodos. Si hay 10 grupos, 10 switches físicos distintos. No sería mejor tener un solo switch de 100 particionable?
- Administrar usuarios: Si un usuario se cambia de grupo o pertenece a varios grupos, no se formaría un cablerío infernal?
Para solucionar estos problemas es que se diseñaron las virtual local area networks (VLAN). Un switch que soporta VLAN permite configurar multiples redes locales en un solo switch. Y los hosts se comunican entre ellos como si estuvieran en un switch aparte. El administrador de red divide los grupos del vlan switch utilizando las herramientas del manufacturer.
Y como se comunican las distitnas redes virtualeS? Se tiene que enviar el trafico desde la VLAN al router y el router vuelve a la vlan al puerto donde se encuentra la otra red local. Los vendedores de switches VLAN incluyen un router dentro que ya implementa este funcionamiento.
Y si queremos conectar varias computadores que están a grandes distancias, tenemos que mandar cables por todos lados? No hay una forma de interconectar VLAN switches e indicar grupos de VLAN que se encuentran presentes en varios switches? La respuesta es Si! Esta técnica se le conoce como VLAN trunking. En el VLAN switch se define una interfaz como VLAN trunk la cual permite conectar 2 switches para que compartan groups de VLAN. Los puertos trunk pertenecen a todas las VLAN y todo frame enviado a una VLAN se reenvía por el trunk port.
Para definir los grupos de VLAN entre distintos switches se define un formato extendido de ethernet (IEEE 802.1Q) que incluye una VLAN tag de 4 bytes. Este tag permite identificar a cual VLAN un switch pertenece. Este VLAN tag incluye dos bytes para definir el protocolo (Tag Protocol Identifier TPID), 2 bytes que tienen el VLAN identifier ID y 3 bits que actúan como un priority field.
Link Virtualization: A network as a link layer
Multiprotocol Label Switching (MPLS) networks son packet-switched, virtual-circuit networks. Tiene sus propios formatos de paquetes y comportamientos. Sin embargo, desde el punto de vista de internet, no es mas que un link-layer que interconecta hosts IP. Las MPLS requieren routers que la soporten. La diferencia clave es que no necesitan la IP para forwardear los paquetes sino que utilizan un label que se determina cuando ingresa el paquete inicialmente en un router MPLS. Luego los routers miran el label para fijarse por donde lo tienen que mandar literalmente. Es decir, no tiene que tomar ninguna descisión o implementar forwarding/routing. Esto aumenta la performance de la red.
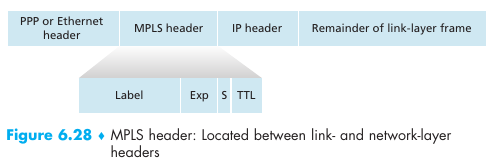
Data Center Networking
Los datacenters es un caso interesante de infraestructura de red por la gran cantidad de nodos y flujo de dato que se encuentra presente en estos edificios. Los hosts en los data centers se les llama blades, estas blades están apiladas en racks que contienen entre 20 a 40 blades. Arriba de cada rack se encuentra un Top of Rack (TOR) Switch. El cual interconecta todas las blades con otros switches en el datacenter. Para cumplir los requerimientos funcionales de un data center se suigen estructuras de red complejas:
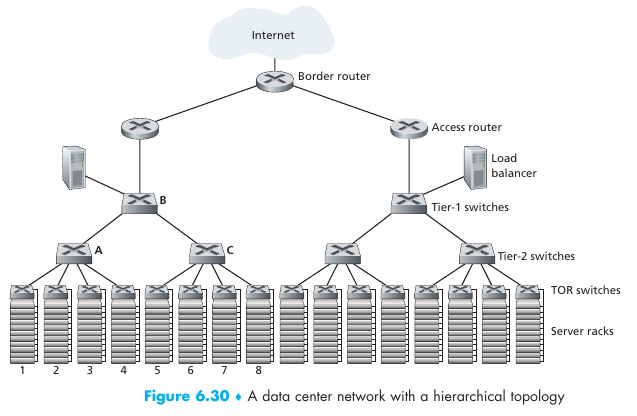
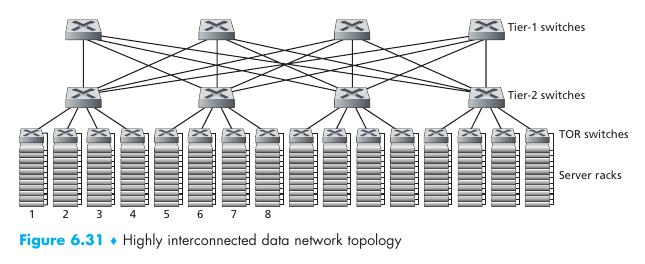
Anexo
Wireshark
Algunos filtros útiles:
- tcp contains WORD: WORD es una palabra cualquiera en el paquete. Filtro muy potente!!!
- ip.addr == xxx.xxx.xxx.xxx
Kathara
kathara lstart/lclean/lrestart permiten iniciar y limpiar un laboratorio. kathara connect device permite conectarte con ssh a un dispositivo de kathara kathara wipe limpia todos los laboratorios cargados en el sistema